扫描ocr软件
-
100天精通Python(实用脚本篇)——第113天:基于Tesseract-OCR实现OCR图片文字识别实战
🔥🔥 本文已收录于 《100天精通Python从入门到就业》:本专栏专门针对零基础和需要进阶提升的同学所准备的一套完整教学,从0到100的不断进阶深入,后续还有实战项目,轻松应对面试,专栏订阅地址:https://blog.csdn.net/yuan2019035055/category_11466020.html 优点 : 订阅限时9.9付费专
-

OCR -- 文本检测
目录 目标检测: 文本检测: 检测难点: 检测方法: 基于回归的文本检测 水平文本检测 任意角度文本检测 弯曲文本检测 基于分割的文本检测 代码示例 可视化文本检测预测 DB文本检测模型构建 backbone网络 FPN网络 Head网络 百度飞桨(PaddlePaddle) - PP-OCRv3 文字检测识别系统 预测
-

什么是OCR转换?
OCR转换是指将图片或扫描文档中的文字内容转换成电子文本的过程。OCR代表光学字符识别(Optical Character Recognition),是一种通过算法和模型来识别图像或文档中的文字,并将其转换成可编辑、可搜索的文本格式。OCR转换通常包括以下步骤: 1. **图像采集**:从扫描仪、摄像头
-

OCR在审核应用落地
本文字数: 6686 字 预计阅读时间: 35 分钟 01 背景 1、业务背景 在传统视频审核场景中,审核人员需要对进审视频中的文字内容进行逐一审核,避免在文字上出现敏感词、违禁词或者广告等相关词汇。这种人工审核费时费力,并且由于审核人员存在个体差异,审核尺度很难在
-
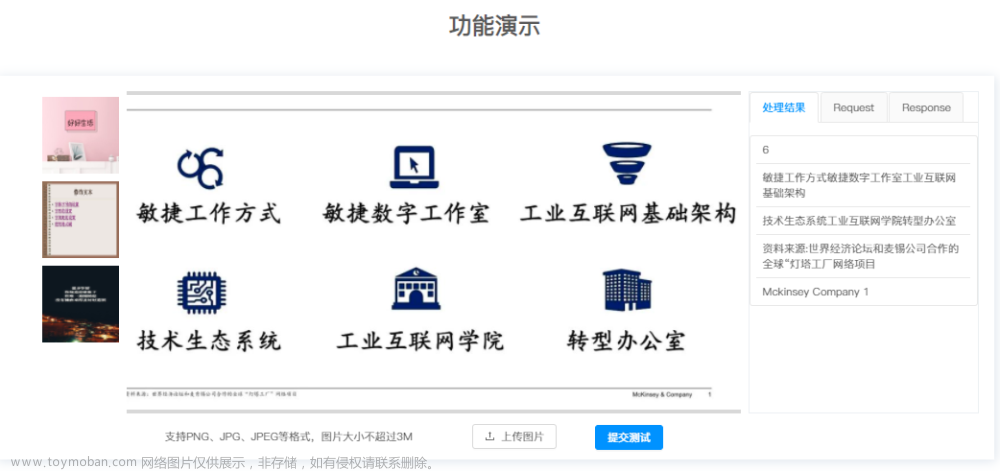
OCR文字识别技术
OCR全称是optical character recognition,中文光学字符识别。 主要技术是:把图像形状转变为文本字符。 简单来说,OCR技术就是通过图像处理和模式识别技术对光学的字符进行识别,即,对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。 OCR 支持各
-
python实现OCR
python实现OCR 在Python中实现OCR(光学字符识别)通常需要使用第三方库,如 pytesseract 。以下是使用 pytesseract 进行OCR的基本步骤: 安装 pytesseract 和相关的OCR库,如 tesseract-ocr 。 使用 pytesseract 库的 image_to_string 函数来识别图片中的文本。 首先,你需要安装 pytesseract 和 tesseract
-
阿里云OCR识别
ocr识别证件照;主要是使用阿里云j接口: 1、注册阿里云账户获取appKey appSer 2、调用接口 2.1:定义常量 2.2 :OCR识别工具: 主要是按照type调用个子的方法
-
离线视频ocr识别
windows安装方法: 下载安装 https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w64-setup-5.3.3.20231005.exe 下载 去掉版本依赖,修改如下: 之后安装 如果遇到 RuntimeError: Failed to init API, possibly an invalid tessdata path: ./ 则需要设置环境变量TESSDATA_PREFIX为C:Program FilesTesseract-OCRtessdata 默认只能
-
OCR 01
* OCR 01: Code generated by OCR 01 * OCR 01: * OCR 01: Prepare text model * OCR 01: create_text_model_reader (\\\'manual\\\', [], TextModel) set_text_model_param (TextModel, \\\'is_dotprint\\\', \\\'true\\\') set_text_model_param (TextModel, \\\'char_width\\\', 42) set_text_model_param (TextModel, \\\'char_height\\\', 54) set_text_model_param (TextModel, \\\'stroke_width\\\', 18.5) set_tex
-
腾讯云OCR识别
目录 前言 一、腾讯云身份验证 二、使用API 2.1 Python OCR API调用 2.2 JAVA OCR API调用 2.3 Go OCR API调用 2.4 Nodejs OCR API调用 2.5 .Net API调用 2.6 C++ API调用 三、代码仓库源码 提示:这里可以添加本文要记录的大概内容: 为了帮助同学们进行OCR识别,本文一共
-

OCR训练部署文档
以文本识别训练为例 环境使用anconda创建了”paddle”的虚拟环境,该环境适合paddleOCR。 数据准备 如图1-1,数据集需要提供train_list.txt,和val_list.txt,具体内容如图1-2,修改配置文件位置图1-3 图1-1 图1-2 train_list.txt,和val_list.txt具体内容 训练模型 安装Cmake,OpenCV,OpenCV-contribute
-
OCR之Tesseract安装
Tesseract是常用的开源OCR识别引擎,后续的图片文字识别项目我们将会调用该库进行识别,本文针对Tesseract的安装配置进行相关说明。 下载地址:Tesseract 选择最新的版本进行下载,下载完成后,解压安装在自己设定的安装路径,一直选择next即可完成安装。 打开系统属性页面,
-

OCR调研报告
本文简要概述了OCR的概念和应用场景,以及OCR常用算法解决方案。最主要的是调研并对比了几个github上star较多的开源项目。现阶段推荐百度开源的项目paddlocr,可直接使用其预训练模型进行演示,并且支持docker部署(实践通过)。可以支持身份证,车牌号,信用卡号识别。并
-

textract OCR的安装使用
在 Python 中,textract 是一个用于提取文本和信息的库。它提供了一个函数 textract.process() ,用于处理不同类型的文档并提取文本内容。下面是 textract.process() 函数的各个参数的介绍: filename (必需参数):要处理的文件的路径或文件对象。可以是本地文件的路径或文件对象,也
-

Paddle OCR 安装使用教程
PaddleOCR是飞浆开源文字识别模型,最新开源的超轻量PP-OCRv3模型大小仅为16.2M。同时支持中英文识别;支持倾斜、竖排等多种方向文字识别;支持GPU、CPU预测,并且支持使用paddle开源组件训练自己的超轻量模型,对于垂直领域的需求有很大帮助。 环境安装 说明:官方推荐使用
-

-
百度OCR api调用代码
import requests import json import base64, urllib API_KEY = \\\'xx\\\' SECRECT_KEY = \\\'xx\\\' pic_name = \\\"img.jpg\\\" def ocr_baidu(): \\\"\\\"\\\"invoke token\\\"\\\"\\\" url = \\\'https://aip.baidubce.com/oauth/2.0/token\\\' body = {\\\'grant_type\\\': \\\'client_credentials\\\', \\\'client_id\\\': API_KEY, \\\'client_secret\\\': SECRECT_KEY }