hmm语音识别python实现功能
-
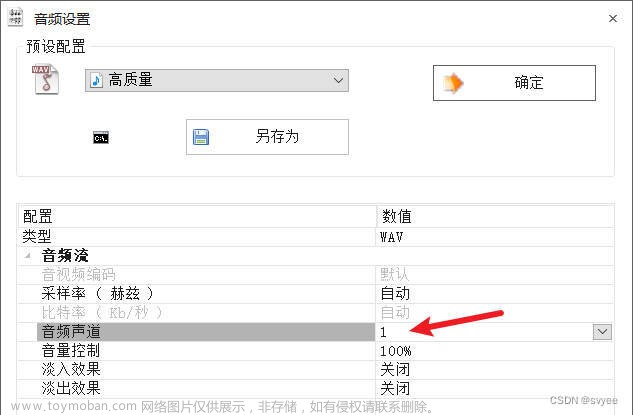
python使用VOSK实现离线语音识别(中文普通话)
目标:一个代码简单,离线,可直接使用,常用语句准确率还不错,免费的,普通话语音转文本的工具 几番对比下来,VSOK基本满足我的需求,记录一下。 环境 windows 10 / python3.8.10 s1 安装 vosk s2 下载模型 两个模型,一个很小,文件名中带有small字样,另一个就很大了,就我自
-
软件测试之语音识别功能如何测试?
语音识别功能的测试需要考虑以下几个方面: 1. 语音输入测试 测试语音识别系统能否准确识别用户的语音输入。这包括测试系统对各种不同语言、方言和口音的理解能力,以及对不同声音质量和噪音环境的鲁棒性测试。 2. 语义理解测试 测试语音识别系统能否准确解析和理解
-
扩展语音识别系统:增强功能与多语言支持
在之前的博客中,我们成功构建了一个基于 LibriSpeech 数据集的英文语音识别系统。现在,我们将对系统进行扩展,增加一些增强功能,并尝试支持多语言识别。 语音合成 --除了语音识别,我们还可以增加语音合成( Text-to-Speech, TTS )功能,将文本转换为语音输
-
语音识别功能测试:90%问题,可以通过技术解决
现在市面上的智能电子产品千千万,为了达到人们使用更加方便的目的,很多智能产品都开发了语音识别功能,用来语音唤醒进行交互;另外,各大公司也开发出来了各种智能语音机器人,比如小米公司的“小爱”,百度公司的“小度”,三星公司的“bixby”,苹果的“siri”
-
EM算法实现之隐马尔科夫模型HMM的python实现
1 基本概念 1.1 马尔科夫链(维基百科) 马尔可夫链(英语:Markov chain),又称离散时间马尔可夫链(discrete-time Markov chain,缩写为DTMC),因俄国数学家安德烈·马尔可夫得名,为状态空间中经过从一个状态到另一个状态的转换的随机过程。该过程要求具备“无记忆”的性质:
-

解析!1V1直播源码开发搭建技术实时语音识别翻译功能的应用
语言是我们人类交流的工具,它的种类繁多,比如世界语言,像是中国的汉语、英国的英语、法国的法语等;又或是我们中国的方言,像是山东话、北京话、上海话等。可谓是五花八门,争奇斗艳,每一种世界语言或是方言都有他独特的风格,但语言种类繁多的同时,这也
-
OpenAI Whisper 语音识别 API 模型使用 | python 语音识别
OpenAI 除了 ChatGPT 的 GPT3.5 API 更新之外,又推出了一个 Whisper 的语音识别模型。支持96种语言。 Python 安装 openai 库后,把需要翻译的音频目录放进去,运行程序即可生成音频对应的文字。 以上。
-
![[语音识别] 基于Python构建简易的音频录制与语音识别应用](https://imgs.yssmx.com/Uploads/2024/02/662057-1.png)
[语音识别] 基于Python构建简易的音频录制与语音识别应用
语音识别技术的快速发展为实现更多智能化应用提供了无限可能。本文旨在介绍一个基于Python实现的简易音频录制与语音识别应用。文章简要介绍相关技术的应用,重点放在音频录制方面,而语音识别则关注于调用相关的语音识别库。本文将首先概述一些音频基础概念,然后
-
Java与智能语音识别:实现准确的语音识别与转换
Java与智能语音识别是指利用Java编程语言和智能语音处理技术实现准确的语音识别和转换。下面是一个详细的教程,介绍了如何使用Java构建智能语音识别系统: 1. 音频数据采集: - 使用Java提供的音频采集库(如Java Sound API)获取音频数据流。 - 连接麦克风设备或读取
-

【花雕动手做】ASRPRO-Plus语音识别(03)---板载硬件模块和12项综合应用功能
ASRPRO-Plus 开发板:是一款全功能带语音识别的物联网开发板,它可以方便的进行系统学习和各种项目实验。板载 RS485、433M 无线收发、红外收发、ESP32-C3(2.4GHz Wi-Fi 和 Bluetooth 5LE)、SPI 彩屏、数码管、RGB 灯、光敏传感器、DHT11 温湿度传感器、1 路继电器输出模块等。 硬件功能分
-
UE4_UE5结合offline voice recognition插件做语音识别功能
市面上主流的语音识别大多是用科大讯飞的SDK,但是那个也不是完全免费使用的,于是我选择使用offline voice recognition的语音识别,购买插件终生使用。 offline voice recognition插件在UE官方商城卖200多元。 我将它需要的资源都打包成一个rar,分享给有需要的人。 其中
-

python 语音识别
在python中训练一个语音识别系统主要需要以下几个步骤: - 语料库准备 - 数据预处理 - 特征提取 - 训练模型 第一部分:语料库的准备 什么是语料库?语料库长什么样? 语料库由两部分组成,第一部分是语音,第二部分是玉莹的标注,通常为字符形式。本次项目中
-

python语音识别whisper
一、背景 最近想提取一些视频的字幕,语音文案,研究了一波 二、whisper语音识别 Whisper 是一种通用的语音识别模型。它在不同音频的大型数据集上进行训练,也是一个多任务模型,可以执行多语言语音识别以及语音翻译和语言识别。 stable-ts在 OpenAI 的 Whisper 之上修改并添加
-

【语音识别】落地实现--离线智能语音助手
参考:基于python和深度学习(语音识别、NLP)实现本地离线智能语音控制终端(带聊天功能和家居控制功能) 基于V3S的语音助手(三)移植pocketsphnix唤醒 基于V3S的语音助手(二)移植pyaudio到开发板 基于V3S的语音助手(一)python3的编译和安装(该版本解决zlib readline可
-
使用Python进行自动语音识别
自动语音识别(ASR)是将口头语言转换为书面文本的过程。 ASR技术已经存在多年,但随着机器学习和深度神经网络的进步,它变得更加准确可靠。在本文中,我们将探讨如何使用Python和Hugging Face Transformers库执行ASR,同时利用PySide6设计了一个简单的GUI界面,演示如下所示:
-
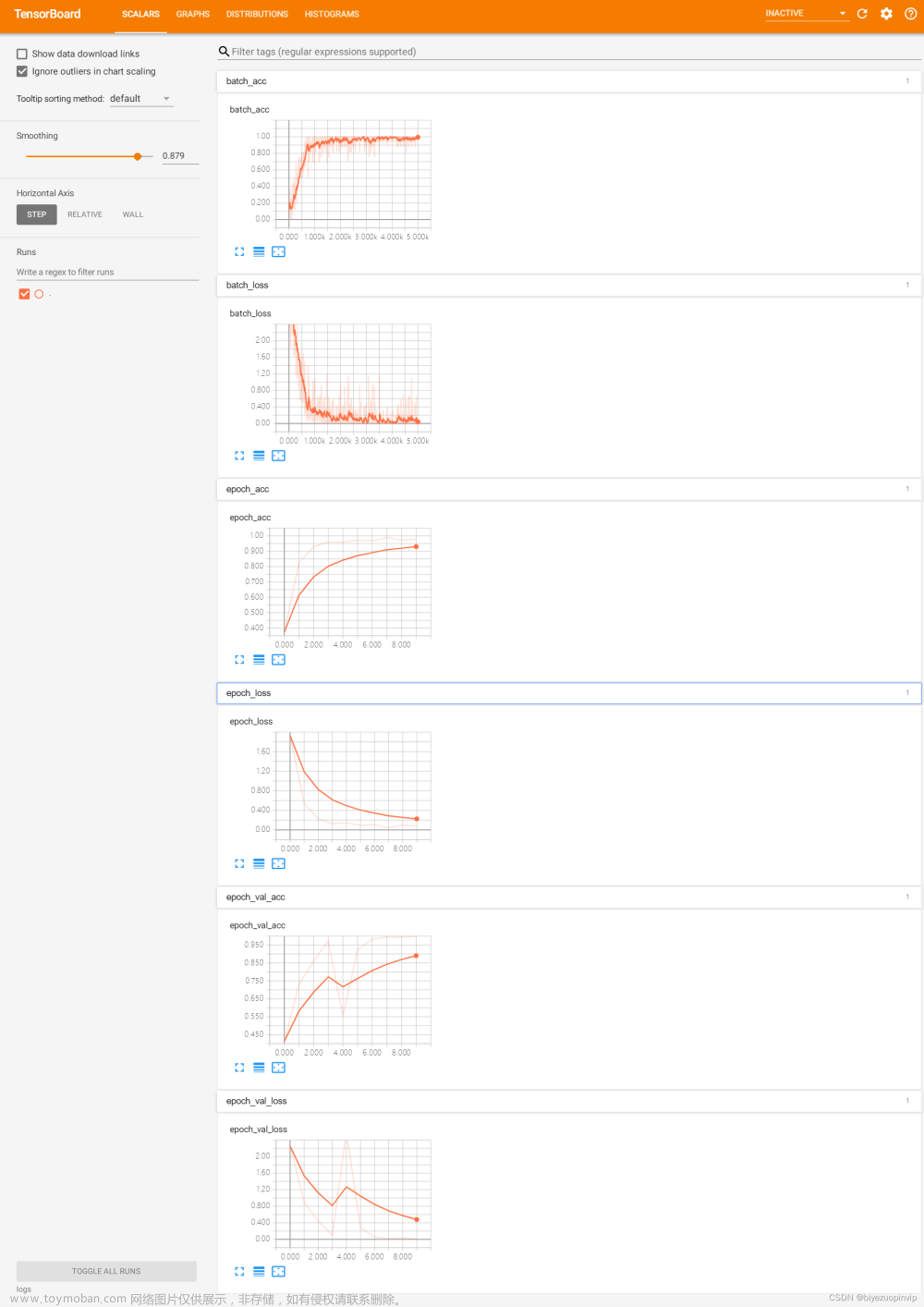
基于Python的语音识别系统
基于Python的语音识别系统的设计与实现 摘 要 随着互联网的发展,语音文件成为了人们接触得越来越多文件。如何高效的从一段录音中提取出关键信息,提取出其中人们感兴趣的内容,直观的呈现给人门。本文以DFSMN作为声学模型,引入TensorFlowr模型,将语音识别转化为翻译任
-

语音识别与Python编程实践
博主简介 博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c++,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,如果有错误之处,大家可以指正。 专栏简介: 本专栏主要研究
-
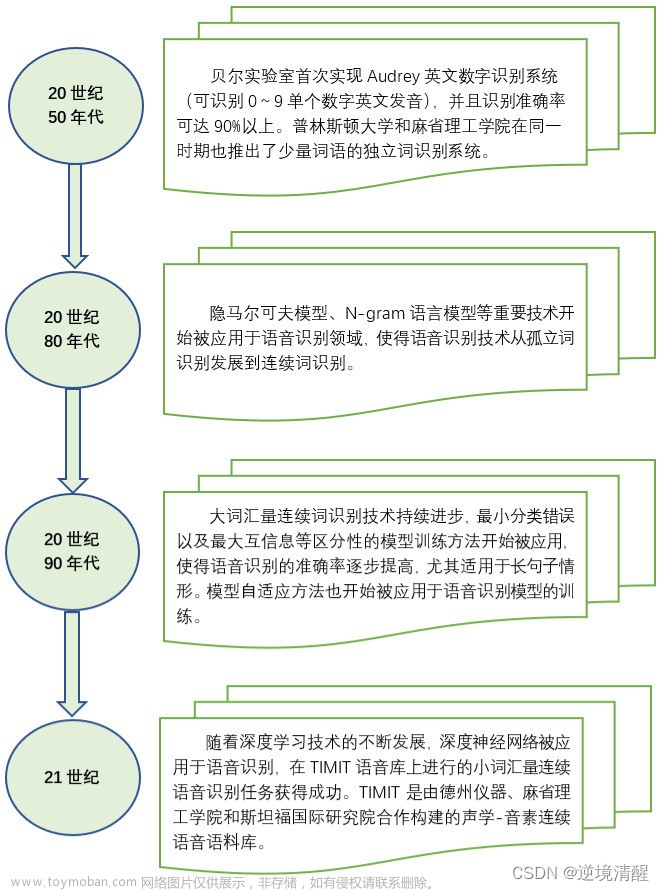
语音识别实战(python代码)(一)
(python :pyttsx、SAPI、SpeechLib实例代码)(一) 本文目录: 一、语音识别的基本原理 (1)、语音识别的起源与发展 (2)、语音识别的基本原理 (3)、语音识别过程 (4)、语音识别的近期发展 二、Python 语音识别 (1)、文本转换为语音 (2)、文本转存为语音文件wav 三、总结
-

语音识别(利用python将语音转化为文字)(升级版)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 基于语音识别(1)进行的完善,修改了60秒断触的问题,另外可以更加方便的调用,语音识别1的链接如下: https://blog.csdn.net/m0_46657126/article/details/124531081 https://www.xfyun.cn/ ps:注册账户是完全免费的,因
-
[python]基于faster whisper实时语音识别语音转文本
语音识别转文本相信很多人都用过,不管是手机自带,还是腾讯视频都附带有此功能,今天简单说下: faster whisper地址: https://github.com/SYSTRAN/faster-whisper https://link.zhihu.com/?target=https%3A//github.com/SYSTRAN/faster-whisper 实现功能: 从麦克风获取声音进行实时语音识别转文本 代码仅仅