mysql慢查询日志配置情况
-
在Windows系统中配置开启MySQL数据库日志的步骤
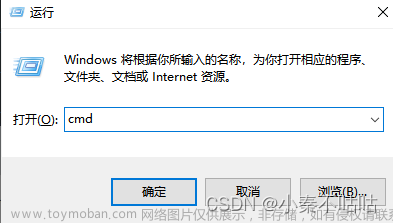
1.首先Win+R,打开命令运行框,输入cmd打开终端窗口。 2.输入指令mysql -u root -p回车输入密码进入mysql数据库。 3.输入:show global variables like\\\'log_bin\\\'; 这里注意一定要带上“;”,回车后查看MySQL的log日志是否已近开启,若是开启状态则会如下图
-
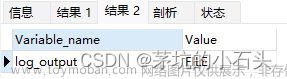
mysql8查看执行sql历史日志、慢sql历史日志,配置开启sql历史日志general_log、慢sql历史日志slow_query_log
mysql8默认未开启 sql 历史日志。 mysql8默认已开启 慢sql 历史日志。 log_output : sql日志输出位置 FILE :输出到文件。默认值 TABLE :输出到表。 mysql.general_log mysql.slow_log general_log : sql历史 日志开关。默认为 OFF slow_query_log : 慢sql历史 日志开关。默认为 ON long_query_time : 慢sql历
-
Linux系统内存、磁盘占用情况查询
#查看磁盘占用空间 显示所有磁盘的使用情况,包括磁盘的总大小、已用空间、可用空间和文件系统类型等。 #查看运行内存的占用情况 #查看进程 1、 ps 命令:该命令用于列出当前用户的进程。以下是几个常用的选项: ps -ef :列出所有进程(包括系统进程)的详细信息。
-
查询sqlserver内存分配情况的SQL
SELECT mg.granted_memory_kb, mg.session_id, t.text, qp.query_plan FROM sys.dm_exec_query_memory_grants AS mg CROSS APPLY sys.dm_exec_sql_text(mg.sql_handle) AS t CROSS APPLY sys.dm_exec_query_plan(mg.plan_handle) AS qp ORDER BY 1 DESC OPTION (MAXDOP 1) USE master GO ;WITH cte AS ( SELECT RP.pool_id , RP.Name , RP.min_memory_percent ,
-
怎么查询电脑的登录记录及密码更改情况?
源头是办公室公用的电脑莫名其妙打不开了,问别人也都不知道密码是多少 因为本来就没设密码啊!(躺倒) 甚至已经想好了如果是50万想攻破电脑,被po抓住要怎么花这笔钱了 是我想太多 当然最后也没解决,莫名其妙重启就又好了,不用输密码 倒是阴差阳错学了点有点意
-

复杂 SQL 实现分组分情况分页查询
Java基础合集 数据结构与算法合集 设计模式合集 多线程合集 分布式合集 ES合集 其他系列文章导航 文章目录 前言 一、根据 camp_status 字段分为 6 种情况 1.1 SQL语句 1.2 SQL解释 二、分页 SQL 实现 2.1 SQL语句 2.2 根据 camp_type 区分返回字段 2.3 根据 camp_status 字段分为 6 种情况 三、分
-
【五一创作】Springboot+多环境+多数据源(MySQL+Phoenix)配置及查询(多知识点)
实时数据展示,通常分两部分, 一部分是离线数据计算,这部分通过大数据程序计算好后,同步到MySQL中。 一部分是实时程序,这部分是Flink实时写入Phoenix表中。 这样两部分拼接好后,就是完整的实时数据部分,所以现在一个接口查询需要将MySQL和Phoenix中的表查询并合并在
-
RabbitMQ查询队列使用情况和消费者详情实现
spring-boot-starter-amqp 是Spring Boot框架中与AMQP(高级消息队列协议)相关的自动配置启动器。它提供了使用AMQP进行消息传递和异步通信的功能。 以下是 spring-boot-starter-amqp 的主要特性和功能: 自动配置: spring-boot-starter-amqp 通过自动配置功能简化了与AMQP相关的组件的集成。它根
-
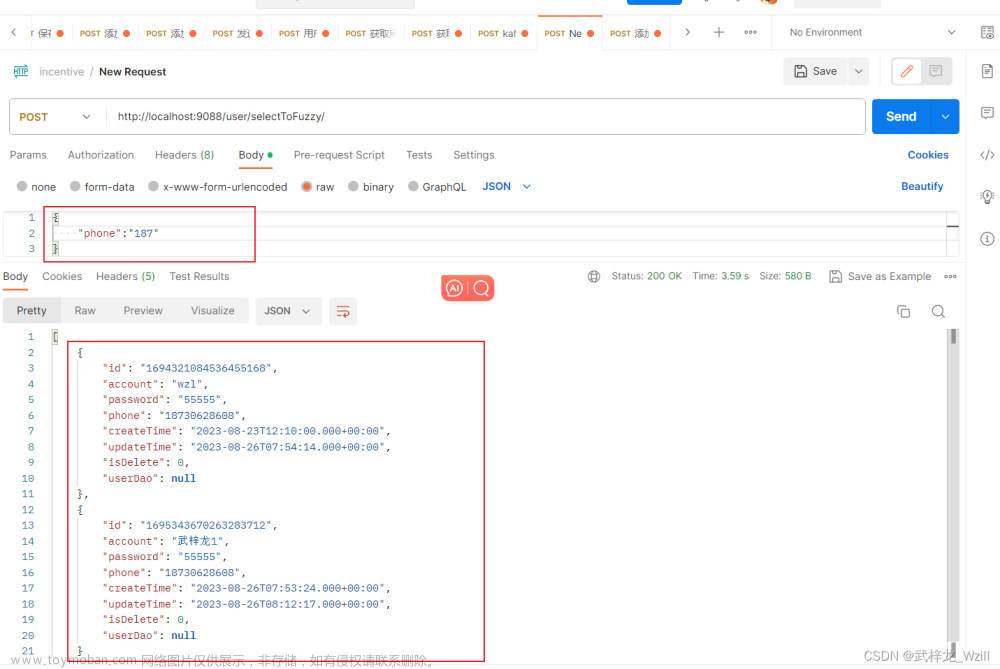
JPA在不写sql的情况下实现模糊查询
本文已收录于专栏 《Java》 在我们的项目中很多的业务都会设计模糊查询,例如按照姓氏去获取人员的信息,按照手机号的前三位去获取人员的信息等。我们除了正常的手写模糊查询的sql语句去获取信息之外,还可以使用JPA自带的API来实现任意字段的模糊查询。JPA已经给
-

docker安装canal1.1.5监控mysql的binlog日志并配置rocketmq进行数据同步到elasticsearch(超级大干货)
1、直接拉取canal镜像 2、创建canal文件夹,用来存在容器挂载到宿主机的目录或文件(注:本实例在/home下操作) 3、先启动canal容器,把需要挂载的目录都copy出来,本例子只挂载了conf和logs目录(自己还想挂载啥东西就进去容器里面看看呗,docker exec -it canal /bin/bash) 4、第
-

【kafka】服务器命令行查询kafka信息消费情况
大家好,我是好学的小师弟,kafka-tool出问题的情况下,可以用命令行来查看kafka信息 1.找到kafka所在的安装目录 2.列出有哪些用户组来消费: 3.查看某个用户组的kafka消息消费情况,有没有数据积压 4.查看topic某分区数据偏移量(offset)最大值,就是看目前Kafka里有多少条消息 新
-

详解Mybatis查询之resultType返回值类型问题【4种情况】
编译软件:IntelliJ IDEA 2019.2.4 x64 操作系统:win10 x64 位 家庭版 Maven版本:apache-maven-3.6.3 Mybatis版本:3.5.6 在Mybatis中,resultType属性是 selcet元素 【映射查询语句】中常用的属性之一,这个属性是什么意思呢?Mybatis官方对它的描述如下所示: 期望从这条语句中返回结果的类全限定
-
SQL 查询两个时间段是否有交集的情况 三种写法
mysql 写法 其他一样 数据库的字段 start_time, end_time 输入的字段 a,b 第一种 第二种 第三种 三种结果相同 推荐用第三种 200万数据测试 第一种23秒 第三种19秒 总结起来就一句话:最小值 小于等于 最大值 并且 最大值 大于等于 最小值,则一定有交集。
-
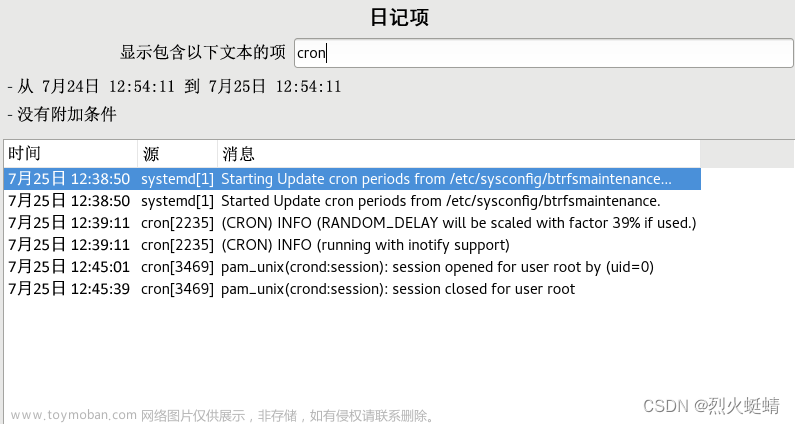
Linux 系统服务日志查询 journalctl:查询 systemd 日记
systemd 在取代 SUSE Linux Enterprise 12 中的传统 init 脚本时(参见第 13 章 “systemd 守护程序”),引入了自身的称为日记的日志记录系统。由于所有系统事件都将写入到日记中,因此,用户不再需要运行基于 syslog 的服务。 日记本身是 systemd 管理的系统服务,全名为 systemd-journal
-

出差学知识No3:ubuntu查询文件大小|文件包大小|磁盘占用情况等
使用指令: ls -lh 文件 指令: du -sh* 打开终端,并执行以下命令: df -h 。该命令将显示文件系统的使用情况,包括每个挂载点的总大小、已用空间、可用空间以及使用百分比。 开终端,并执行以下命令: du -h目录路径 。将目录路径替换为你要检查的目录的路径。该命令将显
-
Linux 日志查询
目录 一.sed 二.cat 三.tail 四.more 五.less 六.vim 七.时间范围查询 一.sed sed -n \\\'/2023-06-28 10:08/,/2023-06-28 10:09/p\\\' nohup.out 查询一段时间日志 sed -n \\\'/2023-06-28 10:08/,/2023-06-28 10:09/p\\\' nohup.out nohup0521.out 查询一段时间日志输出到指定文件 二.cat 根据查看日志cat test.log
-
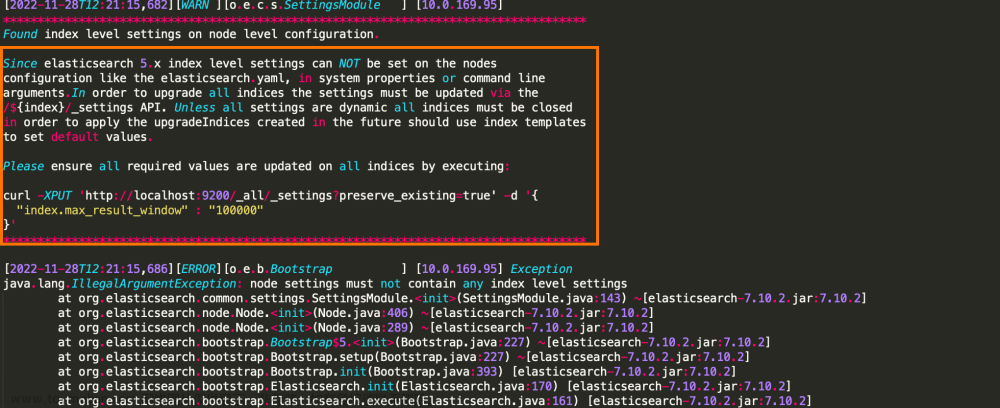
Graylog日志查询超过10000限制问题
在使用graylog时,默认分页查询存在限制,真实使用不能满足,需要我们手动处理。当查询超过执行长度时,会出现一下错误提示 问题描述 查询超过 10000 页, Elasticsearch 出现异常 解决方案 方案一:修改配置文件,重启 Elasticsearch 服务【 Elasticsearch5.x 版本以后不支持】 修改
-
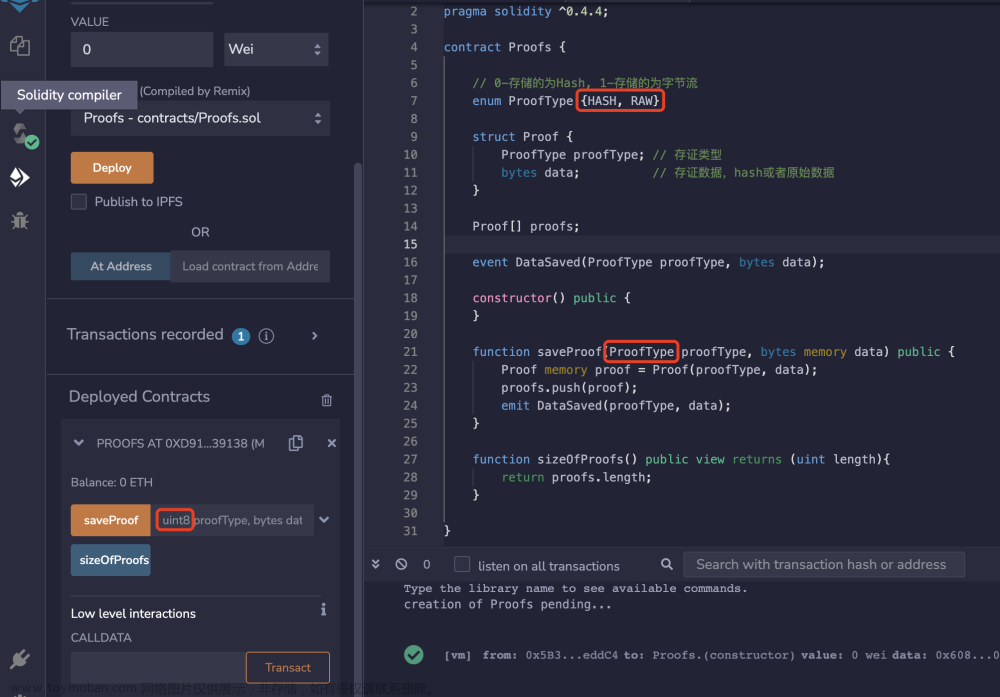
Ethereum以太坊事件日志查询参数
详见:https://www.quicknode.com/docs/ethereum/eth_getLogs address:合约地址 fromBlock:开始区块 toBlock:结束区块 topics:主题数组 blockHash:区块哈希,优先级高于fromBlock、toBlock 这里主要介绍topics参数,其他参数都比较好理解,topics是长度为4的数组集合,topic分为2种:一种事件签名topic,
-

【MySQL】MySQL不走索引的情况分析
当数据表没有设计相关索引时,查询会扫描全表。 查询频繁是数据表字段增加合适的索引。 当数据库查询命中索引时,数据库会首先利用索引列的值定位到对应的数据节点。这个数据节点上记录了对应数据行的行标识符(Row Identifier)。然而,如果查询需要获取该行其他列的
-
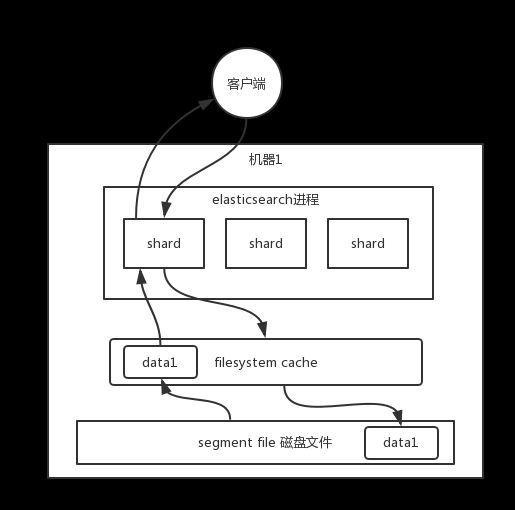
互联网大厂技术-elasticsearch(es)- 在数据量很大的情况下(数十亿级别)提高查询效率
互联网大厂技术-elasticsearch(es)- 在数据量很大的情况下(数十亿级别)提高查询效率 目录 一、问题分析 二、问题剖析 三、性能优化的杀手锏(filesystem cache) 四、数据预热 五、冷热分离 六、document 模型设计 七、分页性能优化 八、解决方案 这个问题是肯定要问的,说白了,就