python实现语音识别对错了
-
语音识别实战(python代码)(一)
(python :pyttsx、SAPI、SpeechLib实例代码)(一) 本文目录: 一、语音识别的基本原理 (1)、语音识别的起源与发展 (2)、语音识别的基本原理 (3)、语音识别过程 (4)、语音识别的近期发展 二、Python 语音识别 (1)、文本转换为语音 (2)、文本转存为语音文件wav 三、总结
-

语音识别(利用python将语音转化为文字)(升级版)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 基于语音识别(1)进行的完善,修改了60秒断触的问题,另外可以更加方便的调用,语音识别1的链接如下: https://blog.csdn.net/m0_46657126/article/details/124531081 https://www.xfyun.cn/ ps:注册账户是完全免费的,因
-
[python]基于faster whisper实时语音识别语音转文本
语音识别转文本相信很多人都用过,不管是手机自带,还是腾讯视频都附带有此功能,今天简单说下: faster whisper地址: https://github.com/SYSTRAN/faster-whisper https://link.zhihu.com/?target=https%3A//github.com/SYSTRAN/faster-whisper 实现功能: 从麦克风获取声音进行实时语音识别转文本 代码仅仅
-

Java 离线语音识别实现语音转文字
model下载 我们需要实现离线语音识别,那么就得将模型下载到本地电脑。下载地址为官网的 Models 模块: https://alphacephei.com/vosk/models 我们直接找到 Chinese 分类,这里有 2 个模型 将下载的语言模型包,在下面代码中引入 代码 CommonUtils 注意:以上代码只支持.wav格式的音频文件
-
实时语音识别(Python+HTML实战)
项目下载地址:FunASR 项目提示所需要下载的库文件:pip install -U funasr 和 pip install modelscope 运行过程中,我发现还需要下载以下库文件才能正常运行: 下载:pip install websockets,pip install ffmpeg 运行 FunASR-main/runtime/python/websocket/funasr_wss_server.py 文件,加载模型 注:如果提示缺少
-
小程序中使用微信同声传译插件实现语音识别、语音合成、文本翻译功能----语音识别(一)
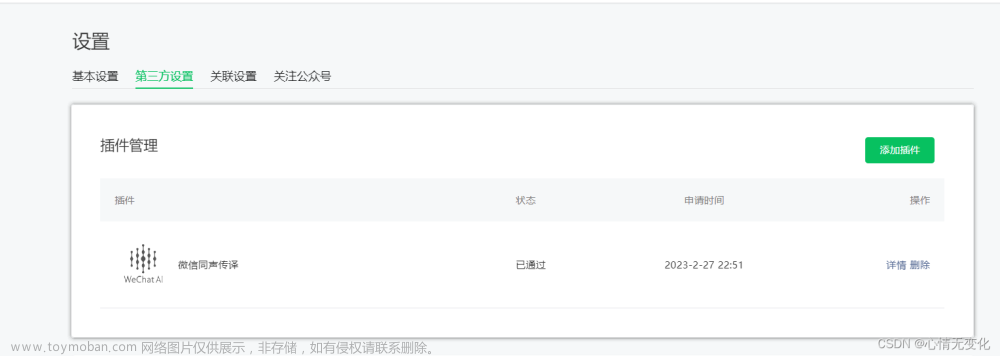
官方文档链接:https://mp.weixin.qq.com/wxopen/plugindevdoc?appid=wx069ba97219f66d99token=370941954lang=zh_CN#- 要使用插件需要先在小程序管理后台的 设置-第三方设置-插件管理 中添加插件,目前该插件仅认证后的小程序。 提供语音的实时流式识别能力,通过获取全局唯一的语音识别管理器rec
-
矩阵分析与语音识别:实现高效准确的识别
语音识别技术是人工智能领域的一个重要分支,它涉及到语音信号的采集、处理、特征提取和模式识别等多个环节。在过去的几十年里,语音识别技术已经发展得相当成熟,但是在实际应用中仍然存在一些挑战,如高效准确率、语音数据量大、多语言支持等。因此,在这篇文
-
第14章-Python-人工智能-语言识别-调用百度语音识别
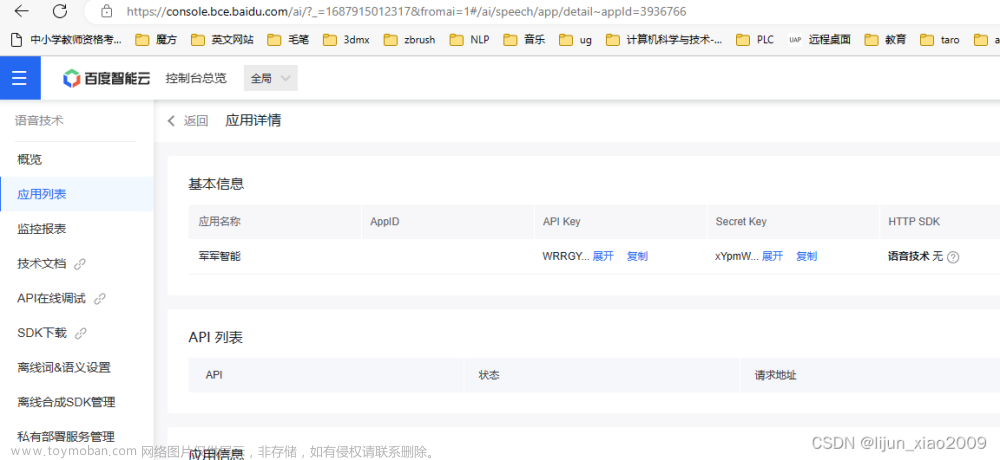
百度语音识别API是可以免费试用的,通过百度账号登录到百度智能云,在语音技术页面创建的应用,生成一个语音识别的应用,这个应用会给你一个APIKey和一个Secret Key,如图14.1所示。 我们在自己的程序中用 API Key 和 Secret Key 这两个值获取 Koken,然后再通过 Token 调
-
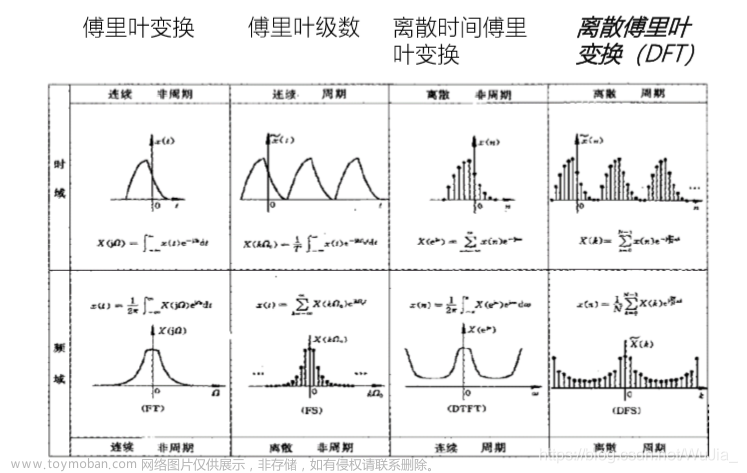
【语音识别入门】特征提取(Python完整代码)
1.1数字信号处理基础 在科学和工程中遇到的大多数信号都是连续模拟信号,例如电压随着时间变化,一天中温度的变化等等,而计算机智能处理离散的信号,因此必须对这些连续的模拟信号进行转化。通过 采样–量化 来转换成数字信号。 以 正弦波 为例: x ( t ) = s i n ( 2 Π
-
免费的语音识别 API:简单实现语音转文本功能
语音识别技术在现代信息处理和人机交互中扮演着重要角色。如果您正在寻找免费的语音识别 API,那么您来对地方了!本文将向您介绍一个简单的方法来实现语音转文本的功能,并提供相应的源代码供参考。 首先,您需要使用 Python 编程语言来实现这个功能。Python 提供了许
-
Pytorch 实现语音识别系统
作者:禅与计算机程序设计艺术 近年来,随着科技的飞速发展,人工智能(AI)领域也逐渐进入高速发展的时代。随着深度学习的火热,机器学习模型已经不再局限于图像分类、文本分类等简单任务,而是应用到各种各样的领域。因此,语音识别(ASR)系统成为了未来人工智
-
免费离线语音识别软件开发工具包(SDK):实现高效准确的语音识别
语音识别技术在当今信息时代扮演着重要的角色,为用户提供了更加便捷和自然的交互方式。然而,传统的语音识别方案通常需要依赖云服务器进行语音数据的处理,这可能会涉及到隐私问题和网络延迟。为了解决这些问题,免费离线语音识别软件开发工具包(SDK)应运而生
-
语音识别入门——常用软件及python运用
ffmpeg sox audacity pydub scipy librosa pyAudioAnalysis plotly 本文分为两个部分: P1 : 如何使用ffmpeg和sox处理音频文件 P2 : 如何编程处理音频文件并执行基本处理 格式转换 使用ffmpeg将输入mkv文件转为mp3文件 降采样、通道转换 ar:声频采样率(audio rate) ac:声频通道(audio channel) 此处
-
使用Python进行语音识别:将音频转为文字
语音识别是一项将语音信号转换为可理解的文本的技术。在Python中,我们可以使用一些库和工具来实现语音识别,并将音频转换为文本。本文将介绍如何使用Python进行语音识别的过程,并提供相应的源代码。 步骤1:安装所需的库 首先,我们需要安装一些Python库来支持语音识
-
语音识别系列︱用python进行音频解析(一)
笔者最近在挑选开源的语音识别模型,首要测试的是百度的paddlepaddle; 测试之前,肯定需要了解一下音频解析的一些基本技术点,于是有此篇先导文章。 笔者看到的音频解析主要有几个: soundfile ffmpy librosa 安装代码: 参考文档:librosa 文档位置:https://librosa.org/doc/latest/co
-
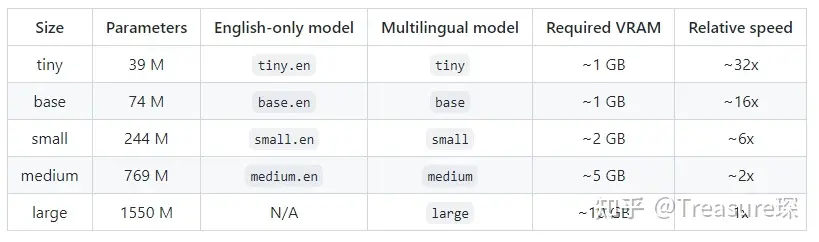
Whisper实现语音识别转文本
#教程 主要参考开源免费离线语音识别神器whisper如何安装, OpenAI开源模型Whisper——音频转文字 Whisper是一个开源的 自动语音识别 系统,它在网络上收集了680,000小时的多语种和多任务监督数据进行训练,使得它可以将多种语言的音频转文字。 Whisper的好处是 开源免费、支持多
-
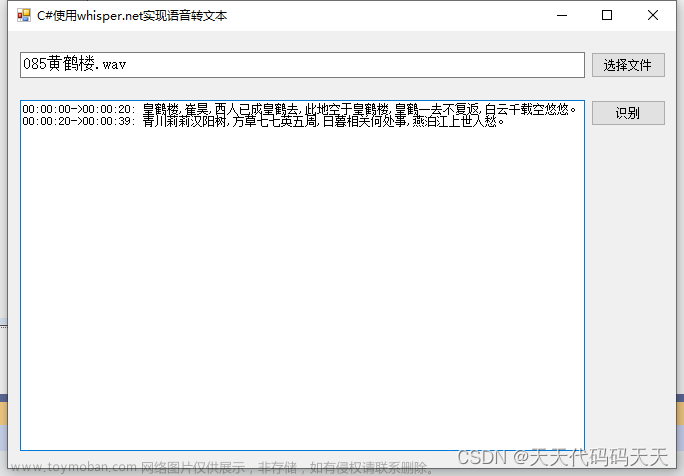
C#使用whisper.net实现语音识别(语音转文本)
目录 介绍 效果 输出信息 项目 代码 下载 github地址:https://github.com/sandrohanea/whisper.net Whisper.net. Speech to text made simple using Whisper Models 模型下载地址:https://huggingface.co/sandrohanea/whisper.net/tree/main/classic whisper_init_from_file_no_state: loading model from \\\'ggml-small.bin\\\' whisper_model_load: loading
-
树莓派Linux实现ChatGPT语音交互(语音识别,TTS)
ChatGPT使用想必大家都不陌生,进入官网,注册账号即可开始正式的对话聊天,可是如何使用ChatGPT API,且在Linux环境下进行语音交互呢?碰巧在今年暑期参加物联网设计竞赛有用到这项功能,今天就来教下大家详细步骤。 如何获取一个ChatGPT账号相比对大家来说不是一件难事,
-
语音识别与语音合成:实现完整的自然语言处理系统
自然语言处理(NLP)是一门研究如何让计算机理解、生成和处理人类语言的学科。在NLP中,语音识别和语音合成是两个重要的子领域。语音识别是将声音转换为文本的过程,而语音合成则是将文本转换为声音。本文将深入探讨这两个领域的核心概念、算法原理、实践和应用场景
-
一键智能视频语音转文本——基于PaddlePaddle语音识别与Python轻松提取视频语音并生成文案
如今进行入自媒体行业的人越来越多,短视频也逐渐成为了主流,但好多时候是想如何把视频里面的语音转成文字,比如,录制会议视频后,做会议纪要;比如,网课教程视频,想要做笔记;比如,需要提取视频中文案使用;比如,需要给视频加个字幕;这时候,只要把视频转