python库实现语音识别的方法
-

合肥中科深谷嵌入式项目实战——基于ARM语音识别的智能家居系统(三)
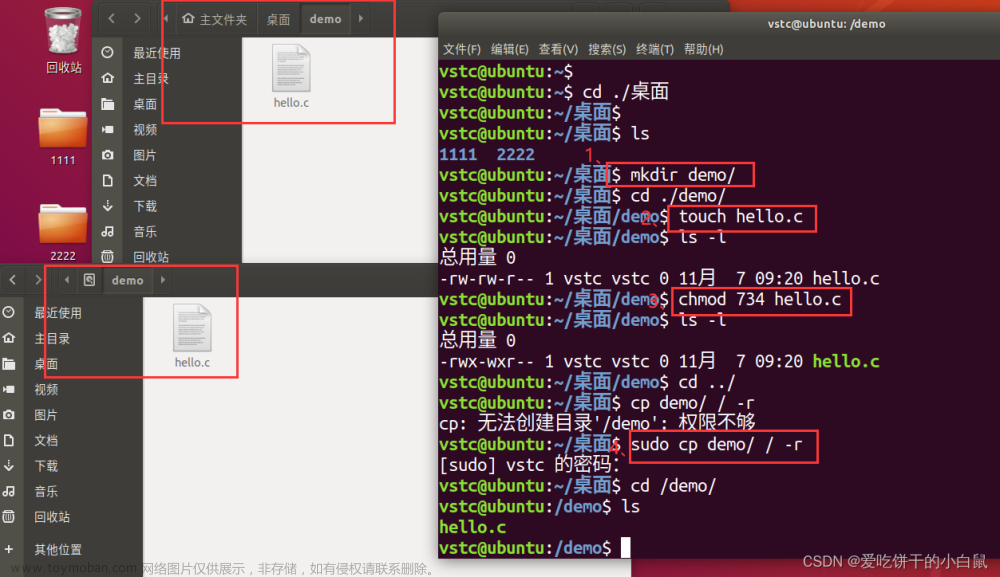
我们上一篇,我们实现在Linux系统下编译程序,我们首先通过两个小练习来熟悉一下如何去编译。今天,我们来介绍一下LCD屏幕基本使用。 如何使用LCD屏幕? 1、打开开发板LCD设备驱动文件。 (/dev/fb0) 2、准备颜色数据。 3、写入颜色像素点数据。 4、关闭
-
合肥中科深谷嵌入式项目实战——基于ARM语音识别的智能家居系统(二)
目录 基于ARM语音识别的智能家居系统 练习一 一、程序编译 练习二: 二、文件IO 三、文件IO常用API接口函数 1、打开文件 open() 2、将数据内容写入文件 write() 3、关闭(保存)文件 四、编程示例 总结 我们上一篇讲了,关于Linux系统的一些质量,今天,我们实现在Linux系统
-

基于Whisper语音识别的实时视频字幕生成 (一): 流式显示视频帧和音频帧
Whistream(微流)是基于Whisper语音识别的的在线字幕生成工具,支持rtsp/rtmp/mp4等视频流在线语音识别 whishow(微秀)是python实现的在线音视频流播放器,支持rtsp/rtmp/mp4等流式输入,也是whistream的前端。python实现原理如下: (1) SPROCESS.run() 的三个子线程负责:缓存流数据,处理音
-
【百度智能云】教程:连接百度ai开放平台api接口并完成语音识别的任务
本文章介绍了如何在Pycharm上用python语言简单的对连接百度ai开放平台的语音识别功能api端口的调用,并在代码里实现了现录音识别内容。 windows10、Pycharm、Python3.9 百度智能云官网为:百度ai开放平台官网 注册百度智能云账号并打开控制台 百度ai平台有许多现有的功能端口可以
-

【STM32单片机】基于语音识别的智能分类垃圾桶,ld3320语音识别模块如何使用,mp3播放模块如何使用
对于“可回收物”“有害垃圾”“厨余垃圾”“其它垃圾”,不能分清扔到哪个垃圾桶怎么办? 基于语音识别的智能分类垃圾桶,识别到就打开对应的垃圾桶,完全没有分不清的烦恼。 //可回收物:塑料瓶、玻璃瓶、铝罐、纸张、纸板、报纸、纸质包装盒、金属罐头等
-

Talk预告 | 中国科学技术大学和微软亚洲研究院联合培养博士生冷燚冲:语音识别的快速纠错模型FastCorrect
本期为 TechBeat人工智能社区 第 430 期 线上Talk。 北京时间 8月11 日 (周四)20:00 , 中国科学技术大学和微软亚洲研究院联合培养博士生—— 冷燚冲 的Talk将准时在TechBeat人工智能社区开播! 他与大家分享的主题是: “ 语音识别的快速纠错模型FastCorrect ”,届时将介绍FastCorrect系
-
MATLAB在语音合成与语音识别中的应用方法与算法实现
近年来,随着人工智能技术的迅猛发展,语音合成与语音识别技术逐渐成为热门研究领域。而MATLAB作为一款专业且强大的科学计算软件,在语音合成与语音识别的应用中发挥着重要的作用。本文将介绍MATLAB在语音合成与语音识别中的应用方法与算法实现,并探讨其
-
使用python实现语音识别
语音识别技术,也被称为自动语音识别,目标是以电脑自动将以人类的语音内容转换为相应的文字和文字转换为语音。 一. 文本转换为语音 1.1 使用pyttsx 使用名为pyttsx的python包,可以将文本转换为语音。 安装pyttsx包 示例 运行之后可以播放语音。 1.2 使用SAPI 在python 中,也可
-
python实现文字转语音
pyttsx3是一个Python库,用于文字转语音的功能。它可以将文本转换为语音,并使用不同的音频引擎进行输出。这个教程将向您介绍如何使用pyttsx3来创建自定义的语音应用程序。 使用以下命令安装pyttsx3库: 首先,导入pyttsx3库: 然后,创建一个引擎对象: 接下来,使用 say() 方
-

python实现语音识别
1. 首先安装依赖库 2. 播放音频文件 3. 语音识别 默认只识别英文,如果需要支持中文,需要下载中文模型包,下载地址如下: CMU Sphinx - Browse /Acoustic and Language Models at SourceForge.net 下载完解压到sphinx安装路径下: D:installAnacondaLibsite-packagesspeech_recognitionpocketsphinx-data
-
Python 实现文本转语音
: Python 是一种非常强大的脚本语言,可以用来实现各种复杂的应用,其中之一就是文本转语音,即把文字转换成声音来发出。在这里,我们将使用 Python 的 gTTS 库来实现文本转语音的功能。 使用 gTTS 库之前,我们需要先安装 gTTS。安装 gTTS 很简单,我们可以使用 pip 安装:
-
Python 实现语音转文本
Python可以使用多种方式来实现语音转文本,下面介绍其中两种。 Google Speech API 是 Google 在 2012 年推出的一个 API,可以用于实现语音转文本。使用 Google Speech API 需要安装 SpeechRecognition 库,可以使用 pip 安装: 安装完成后,可以使用下面的代码实现语音转文本: 除了 Google Spe
-
Python使用PaddleSpeech实现语音识别(ASR)、语音合成(TTS)
目录 安装 语音识别 补全标点 语音合成 参考 PaddleSpeech是百度飞桨开发的语音工具 注意,PaddleSpeech不支持过高版本的Python,因为在高版本的Python中,飞桨不再提供paddle.fluid API。这里面我用的是Python3.7 需要通过3个pip命令安装PaddleSpeech: 在使用的时候,urllib3库可能会报错,因
-
【小沐学Python】Python实现语音识别(SpeechRecognition)
https://pypi.org/project/SpeechRecognition/ https://github.com/Uberi/speech_recognition SpeechRecognition用于执行语音识别的库,支持多个引擎和 API,在线和离线。 Speech recognition engine/API 支持如下接口: 以上几个中只有 recognition_sphinx()可与CMU Sphinx 引擎脱机工作, 其他六个都需要连接互联网。另
-

【小沐学Python】Python实现语音识别(Whisper)
https://github.com/openai/whisper Whisper 是一种通用的语音识别模型。它是在包含各种音频的大型数据集上训练的,也是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。 Open AI在2022年9月21日开源了号称其英文语音辨识能力已达到人类水准的Whisper神经网络,且它亦支
-
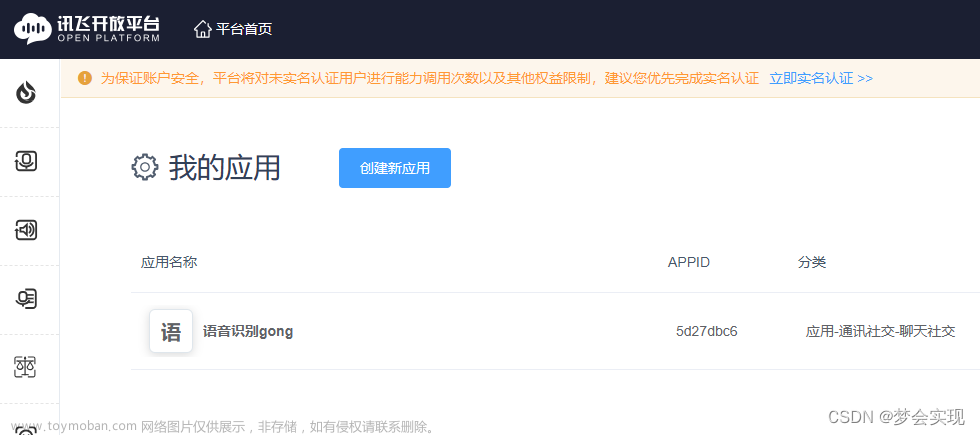
python实现语音识别(讯飞开放平台)
1.注册讯飞平台账号讯飞官网网址。 2.打开讯飞控制台。 3.点击“创建新应用”。 4.输入“应用名称”,“应用分类”,“应用功能描述”(这些都是自定义的)。 5.创建成功后,记住“APPID”,“APISecret”,“APIKey”这三个关键。 如果有没有的依赖库,通过pip在Anaconda的配置
-

语音增强——基本谱减法及其python实现
参考视频: https://www.bilibili.com/video/BV1eV411W7V4/?spm_id_from=333.788vd_source=77c874a500ef21df351103560dada737 语音增强(去噪):消除语音中的噪声,增加语音听感与可懂度。 顾名思义,谱减法,就是用带噪信号的频谱减去噪声信号的频谱。谱减法基于一个简单的假设:假设语音中的噪声只
-
Python使用whisper实现语音识别(ASR)
目录 Whisper的安装 Whisper的基本使用 识别结果转简体中文 断句 Whisper是OpenAI的一个强大的语音识别库,支持离线的语音识别。在使用之前,需要先安装它的库: 使用whisper,还需安装setuptools-rust: 但是,whisper安装时,自带的pytorch可能有些bug,因此需要卸载重装: 卸载: 重装
-
【NLP】用python实现文本转语音处理
介绍一款python调用库,离线软件包pyttsx3 API,它能够将文字转化成语音文件。Python 中有多种 API 可用于将文本转换为语音。pyttsx3 是一个非常易于使用的工具,可将输入的文本转换为音频。与其它类似的库不同,它可以离线工作,并且与 Python 2 和 3 兼容。
-
Ubuntu20.04 使用Python实现全过程离线语音识别(包含语音唤醒,语音转文字,指令识别,文字转语音)
因为手头有一个项目,该项目需要在香橙派上实现语音控制,并且带有语音唤醒功能。简单来说,就是通过唤醒词唤醒香橙派,然后说出相关指令,香橙派去执行指令。 但是,在弄香橙派的时候,自带的麦克风不好使了,单独进行麦克风测试的时候是好使的,但是程