
Linux Centos 内核替换与ISO制作详细指南
本文详细介绍了在CentOS系统中进行内核替换和制作自定义ISO镜像的步骤和注意事项,并介绍了在替换内核过程中可能遇到的各种错误,并提供了解决方法,如处理vmlinuz权限问题、initrd.img加载失败、内核模块体积过大等。
vscode以及Anaconda安装以及相关环境配置
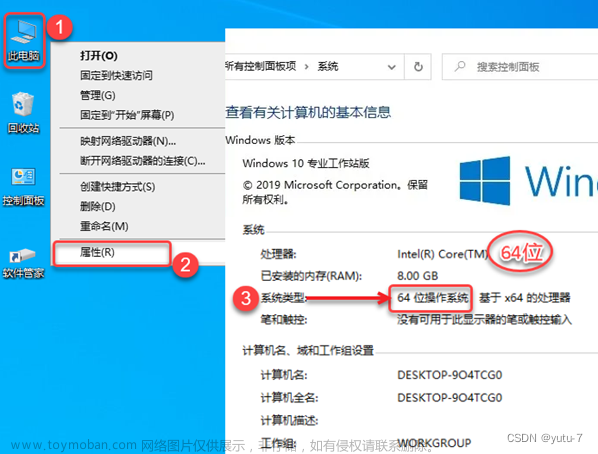
相信很多的小伙伴和我一样初步涉入深度学习领域,那么对于小萌新来说,该选择什么样的方案去运行我们学习或者是下载好的项目呢?最常见的选择方案无非就是两种,一种是python搭配vscode/pycharm,这种方式不值得推荐,理由待会再说。另一种就是主流推荐方案,即anacond

【Python相关】anaconda介绍、安装及conda命令详解
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️ 👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博相关......)👈 博主原文链接:https://www.yourmetaverse.cn/nlp/286/ 1.1 个人对anaconda的理解 个人认
tensorflow-gpu 2.3.0安装 及 相关对应版本库安装(Anaconda安装)
目录 如需转载,请标明出处,谢谢。 一、安装tensorflow-gpu2.3.0 二、配置其他相关的库 很多人以为安装完tensorflow-gpu就是一切都结束了,但是殊不知,python中的很多库,比如numpy,matplotlib等库,就与我们的tensorflow的版本有对应 总结 对于anaconda的下载,网上的教程很多,而且很
在Anaconda的虚拟环境上安装cuda、pytorch、opencv以及tensorflow 以及相关报错。
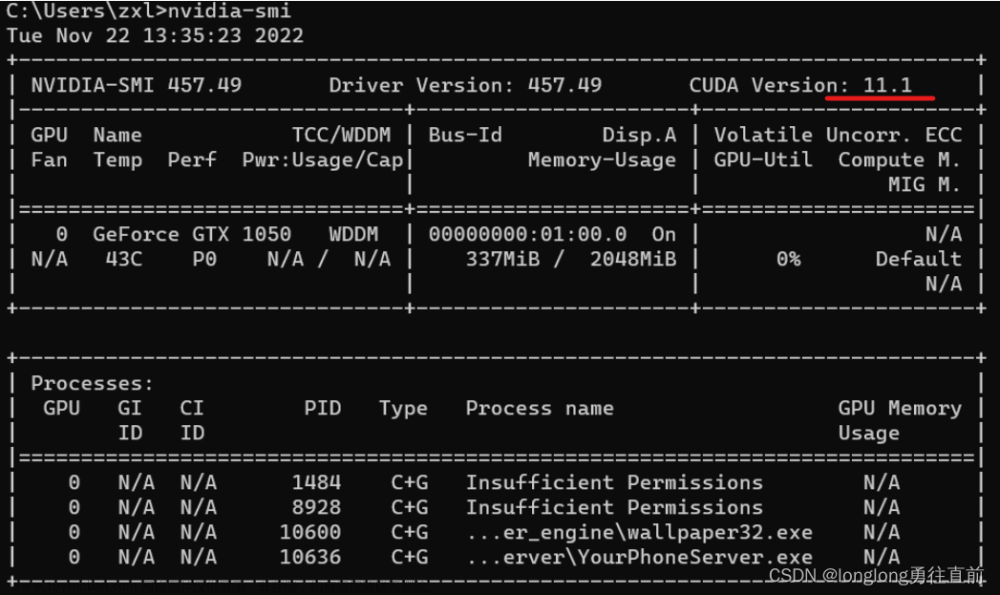
首先查看自己电脑能支持的cuda版本,查看方法,命令行输入:nvidia-smi 这里我的cuda最高支持11.1的版本,下载的时候找11.1及以下的都可以 然后是在命令行进入提前创建好的虚拟环境(我的虚拟环境名字叫DLGPU,这里要换成自己的) 然后去pytorch的官网里可以找到下载cuda和对应
Anaconda更换镜像源的相关配置
上一期博客主要成功的安装好了annaconda以及vscode,对我来说已经迫不及待想要从github导入项目自己运行一下了。但是环境的配置是第一关,我们需要根据自己下载的项目或者是自己编写的项目添加各种软件包。而问题的关键就在于通过Anaconda Prompt窗口直接pip install下载的网址
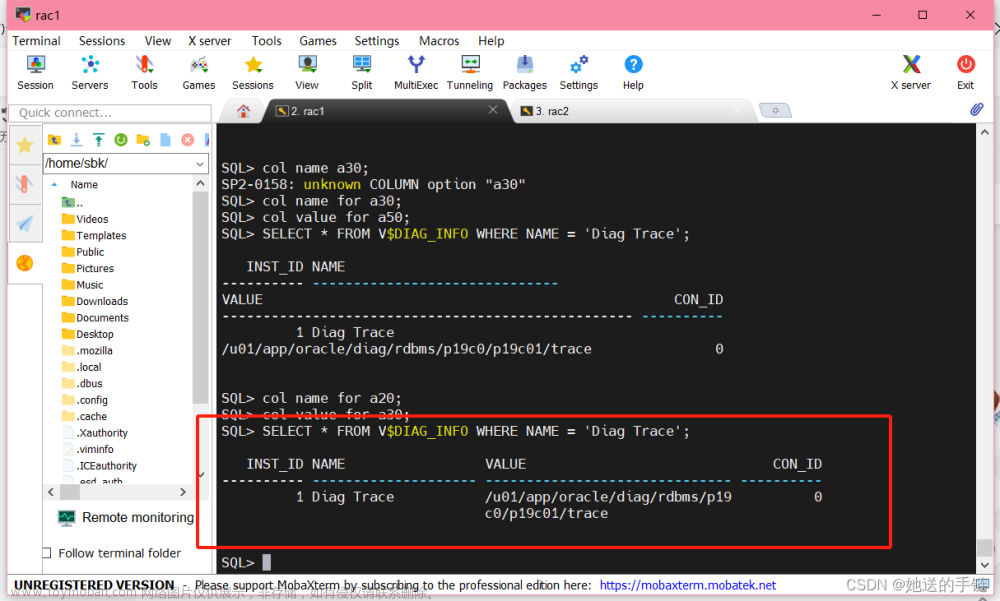
Oracle 19c RAC集群相关日志
在Oracle数据库中,重做日志记录了数据库发生的所有修改操作,包括数据的插入,更新和删除。 在RAC的环境中,每个实例都有自己的重做日志组(redo log group)。这些日志组通常存储在共享设备上,以确保所有节点上的实例都可以访问到。 多个实例可以并发的写入重做日志,
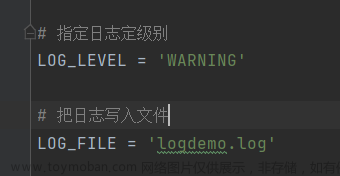
Python爬虫——scrapy_日志信息以及日志级别
日志级别(由高到低) CRITICAL: 严重错误 ERROR: 一般错误 WARNING: 警告 INFO: 一般警告 DEBUG: 调试信息 默认的日志等级是DEBUG 只要出现了DEBUG或者DEBUG以上等级的日志,那么这些日志将会打印 settings.py文件设置: 默认的级别为DEBUG,会显示上面所有的信息 LOG_FILE:将屏幕显
linux系统重启 查看相关日志和历史记录
last 命令不仅可以按照时间从近到远的顺序列出该会话的特定用户、终端和主机名,而且还可以列出指定日期和时间登录的用户。输出到终端的每一行都包括用户名、会话终端、主机名、会话开始和结束的时间、会话持续的时间. 使用 last 命令来查询最近登录到系统的用户和系
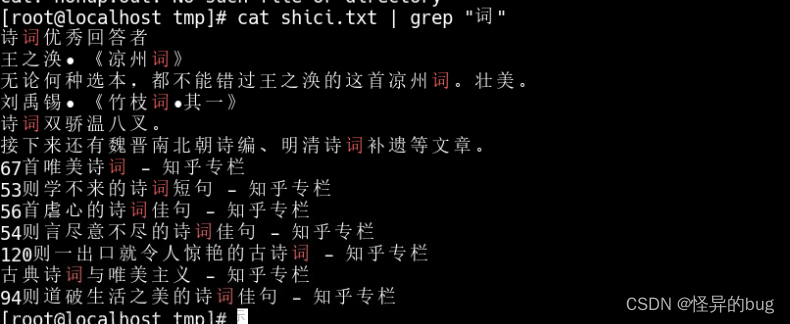
Linux日志相关命令—查看\关键词查询\截取\日志压缩备份
1、动态日志查看。 说明:程序启动可以动态查看运行日志。 2、显示最后100行 说明:动态日志没有写入的时候,可以用该命令查询最后的几行 常用(可记住): 说明:会查询日志文件中涉及的那一行,并显示出来,在日志中出现太多就不好定位。 说明:搜索

查看日志信息
在我们编写代码的过程中可能看不懂错误提示信息,或者不知道错出在什么地方的情况,我们可以打印输出日志信息来检查 使用lombok提供的日志记录器,自定义编程查看调试信息 1、引入lombok依赖 2、在application.properties中配置日志输出等级 3、在控制器中自定义输出日志 控制
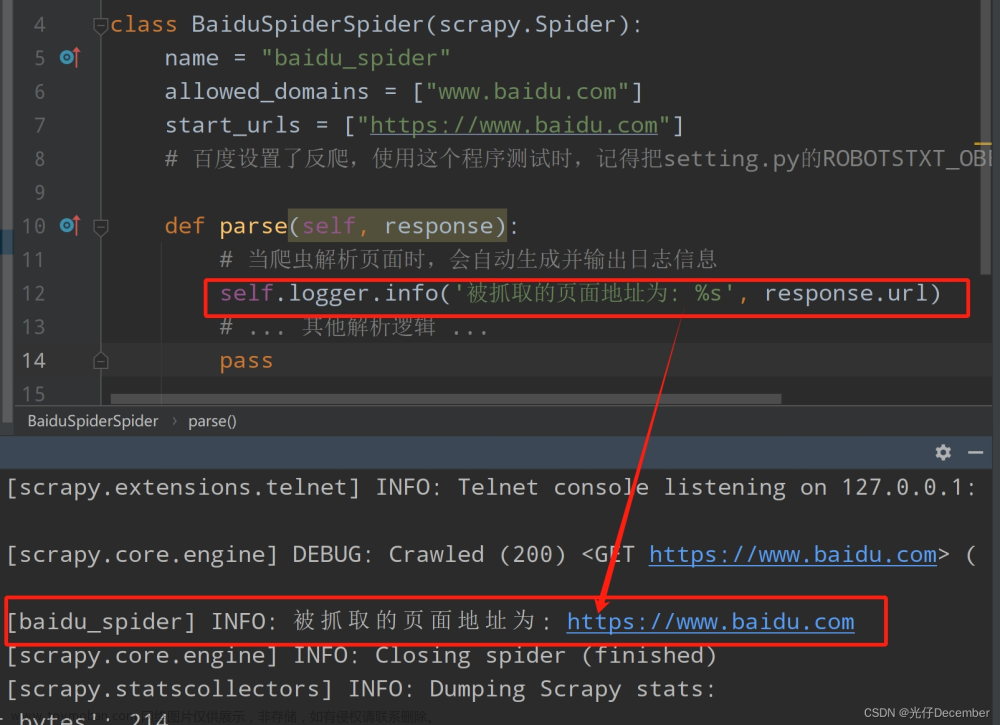
【Python从入门到进阶】53、Scrapy日志信息及日志级别
接上篇《52、CrawlSpider链接提取器的使用》 上一篇我们学习了基于规则进行跟踪和自动爬取网页数据的“特殊爬虫”CrawlSpider。本篇我们来学习Scrapy的日志信息及日志级别。 1、日志在Scrapy中的重要性 在Scrapy框架中,日志扮演着至关重要的角色。日志不仅记录了爬虫在运行过程
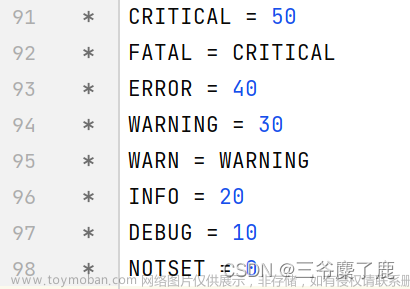
python中如何打印日志信息
日志打印方式 常见的Python日志打印方式为使用内置函数 print() 或者 logging 模块打印日志。 print() 只能将日志打印至控制台,不推荐此方式 logging 模块默认将日志打印至控制台,也可以配置打印到指定日志文件,推荐使用此方式 logging模块 日志等级 logging提供了函数来做日志处
centos7查看日志信息
1、实时查看日志信息 tail -f hadoop-hadoop-resourcemanager-k8s-master.out 2、显示最后20行 tail -n 20 hadoop-hadoop-resourcemanager-k8s-master.log 3、从第5行开始显示文件 tail -n +5 hadoop-hadoop-resourcemanager-k8s-master.log 1、查询10行之后的所有日志 cat -n +10 hadoop-hadoop-resourcemanager-k8s-master.log 2、查询日志尾部
【Android】logcat日志敏感信息泄露
之前会遇到一些应用logcat打印敏感信息,包括但不限于账号密码,cookie凭证,或一些敏感的secretkey之类的,下面客观的记录下起危害性。 1. logcat logcat是Android系统提供的一种记录日志的工具。它可以帮助开发人员诊断应用程序中的问题,例如崩溃、内存泄漏和性能问题。l