-
PySpark大数据教程:深入学习SparkCore的RDD持久化和Checkpoint
本教程详细介绍了PySpark中SparkCore的RDD持久化和Checkpoint功能,重点讲解了缓存和检查点的作用、如何进行缓存、如何设置检查点目录以及它们之间的区别。还提供了join操作的示例和Spark算子补充知识。
-
9、Flink四大基石之Checkpoint容错机制详解及示例(checkpoint配置、重启策略、手动恢复checkpoint和savepoint)
一、Flink 专栏 Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。 2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。 3、
-
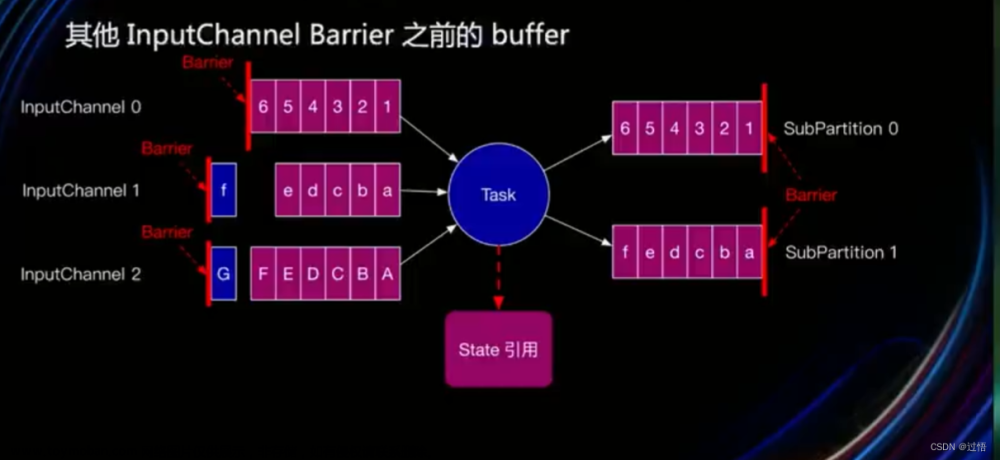
Flink非对齐checkpoint原理(Flink Unaligned Checkpoint)
为什么提出Unaligned Checkpoint(UC)? 因为反压严重时会导致Checkpoint失败,可能导致如下问题 恢复时间长-服务效率低 非幂等和非事务会导致数据重复 持续反压导致任务加入死循环(可能导致数据丢失,例如超过kafka的过期时间无法重置offset) UC的原理 UC有两个阶段(UC主要是
-
【Flink状态管理(六)】Checkpoint的触发方式(1)通过CheckpointCoordinator触发算子的Checkpoint操作
Checkpoint的触发方式有两种 一种是数据源节点中的Checkpoint操作触发,通过CheckpointCoordinator组件进行协调和控制。 CheckpointCoordinator通过注册定时器的方式按照 配置的时间间隔触发数据源节点的Checkpoint操作 。数据源节点会向下游算子发出Checkpoint Barrier事件,供下游节点使用。
-
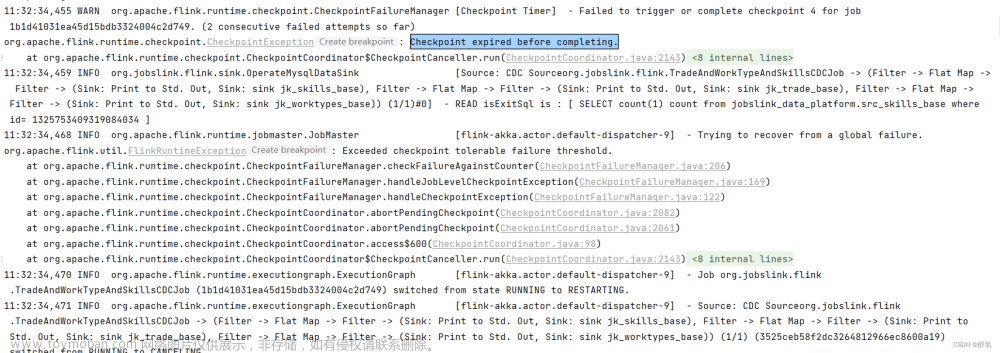
【flink】Checkpoint expired before completing. 使用flink同步数据出现错误Checkpoint expired before completing.
任务超时了: 重新把任务配置参数,配置如下: 或者修改 flink的 配置文件flink-conf.yaml
-
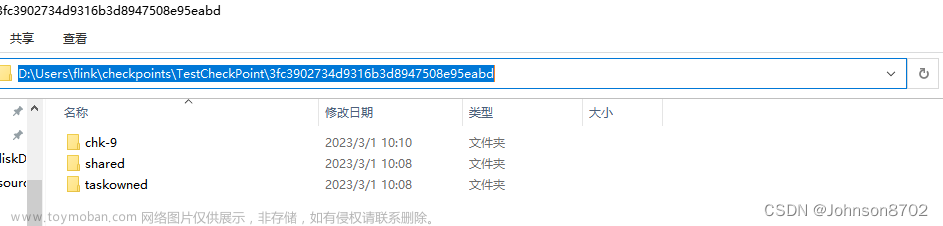
Flink本地checkpoint测试
在本地IDEA测试中,使用本地文件存储系统,作为checkpoint的存储系统,将备份数据存储到本地文件中,作业停止后,从本地备份数据启动Flink程序。 主要分为两步: 1)备份数据 2)从备份数据启动 备份数据的配置,和使用HDFS文件体统类似,只不过路径填写成本地文件系统的
-
Flink: checkPoint
依据1.17.1 最新版本的内容研究下期运作原理,总的来说其实就是设置一些参数,这些参数就会影响到如何存储checkpoint的问题.用起来没什么难的,参数配置的组合到是挺多cuiyaonan2000@163.com 参考资料: Checkpointing | Apache Flink State Backends | Apache Flink Flink 中的每个方法或算子都能够是 有
-

Pytorch 中的 checkpoint
当我们在谈论 Pytorch checkpoint 时,我们可能在说两件不同的事情。 第一个是 General checkpoint ,用它保存模型的参数、优化器的参数,以及 Epoch, loss 等任何你想要保存的东西。我们可以利用它进行断点续训,以及后续的模型推理。长时间训练大模型时,在代码中定期保存 check
-
Spark 检查点(checkpoint)
Checkpointing可以将RDD从其依赖关系中抽出来,保存到可靠的存储系统(例如HDFS,S3等), 即它可以将数据和元数据保存到检查指向目录中。 因此,在程序发生崩溃的时候,Spark可以恢复此数据,并从停止的任何地方开始。 Checkpointing分为两类: 高可用checkpointing,容错性优先。这
-

MySQL笔记之Checkpoint机制
CheckPoint是MySQL的WAL和Redolog的一个优化技术。 CheckPoint做了什么事情?将缓存池中的脏页刷回磁盘。 checkpoint定期将db buffer的内容刷新到data file,当遇到内存不足、db buffer已满等情况时,需要将db buffer中的内容/部分内容(特别是脏数据)转储到data file中。 在转储时,会记录
-
[spark] DataFrame 的 checkpoint
在 Apache Spark 中,DataFrame 的 checkpoint 方法用于强制执行一个物理计划并将结果缓存到分布式文件系统,以防止在计算过程中临时数据丢失。这对于长时间运行的计算过程或复杂的转换操作是有用的。 具体来说, checkpoint 方法执行以下操作: 将 DataFrame 的物理计划执行,并将结
-
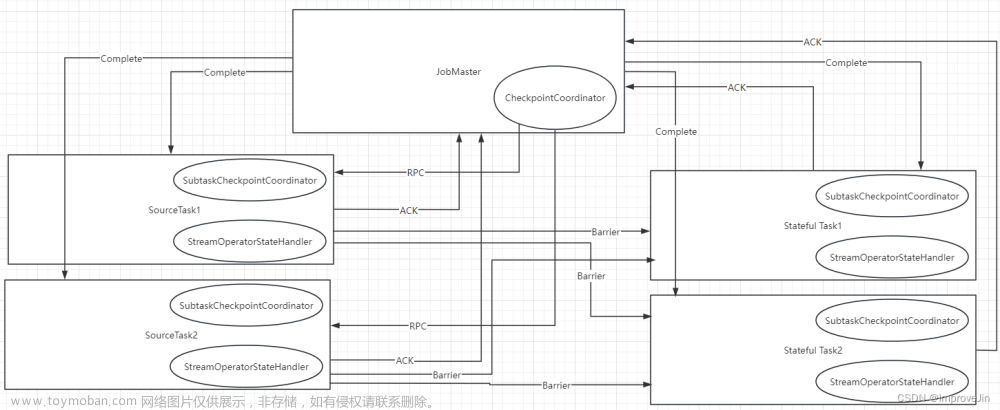
Flink源码之Checkpoint执行流程
Checkpoint完整流程如上图所示: JobMaster的CheckpointCoordinator向所有SourceTask发送RPC触发一次CheckPoint SourceTask向下游广播CheckpointBarrier SouceTask完成状态快照后向JobMaster发送快照结果 非SouceTask在Barrier对齐后完成状态快照向JobMaster发送快照结果 JobMaster保存SubTask快照结果 JobMaster收到所
-

如何排查 Flink Checkpoint 失败问题?
这是 Flink 相关工作中最常出现的问题,值得大家搞明白。 1. 先找到超时的subtask序号 图有点问题,因为都是成功没失败的,尴尬了。 借图: 2. 找到对应的机器和任务 方法很多,这里看自己习惯和公司提供的系统。 3. 根据日志排查问题 netstat -nap| grep 端口号 就找到对应的p
-
Flink状态容错savepoint与checkpoint
本文目录 Checkpoints State Backends Savepoints Checkpoints 与 Savepoints区别 Flink可以保证exactly once,与其容错机制checkpoint和savepoint分不开的。本文主要讲解两者的机制与使用,同时会对比两者的区别。 Checkpoint 使 Flink 的状态具有良好的容错性,通过 checkpoint 机制,Flink 可以对作业的状态
-
flink sql checkpoint 调优配置
- `execution.checkpointing.interval`: 检查点之间的时间间隔(以毫秒为单位)。在此间隔内,系统将生成新的检查点 SET execution.checkpointing.interval = 6000; - `execution.checkpointing.tolerable-failed-checkpoints`: 允许的连续失败检查点的最大数量。如果连续失败的检查点数量超过此值,作业将失败