-
ChatGPT-PLUS:基于多平台大语言模型的 AI 助手全套开源解决方案
ChatGPT-PLUS是一个基于 AI 大语言模型 API 实现的 AI 助手全套开源解决方案,集成了多个平台的大语言模型,包括 OpenAI、Azure、ChatGLM、讯飞星火、文心一言等。该项目采用 Go + Vue3 + element-plus 实现,提供完整的开源系统,支持各种预训练角色应用、绘画功能集成、支付功能、插件 API 功能等特性。详细功能截图和体验地址可在文章中找到。
-

【大语言模型LLM】-基础语言模型和指令微调的语言模型
🔥 博客主页 : 西瓜WiFi 🎥 系列专栏 : 《大语言模型》 很多非常有趣的模型,值得收藏,满足大家的收集癖! 如果觉得有用,请三连👍⭐❤️,谢谢! 长期不定时更新,欢迎watch和fork!❤️❤️❤️ ❤️ 感谢大家点赞👍 收藏⭐ 评论⭐ 🎥 大语言模型LLM基础-系列文章
-
04 统计语言模型(n元语言模型)
博客配套视频链接: https://space.bilibili.com/383551518?spm_id_from=333.1007.0.0 b 站直接看 配套 github 链接:https://github.com/nickchen121/Pre-training-language-model 配套博客链接:https://www.cnblogs.com/nickchen121/p/15105048.html 预先训练 我们有两个相似的任务 A 和 B,任务 A 已经完成了得到了一个模型 A 任
-

一文解码语言模型:语言模型的原理、实战与评估
在本文中,我们深入探讨了语言模型的内部工作机制,从基础模型到大规模的变种,并分析了各种评价指标的优缺点。文章通过代码示例、算法细节和最新研究,提供了一份全面而深入的视角,旨在帮助读者更准确地理解和评估语言模型的性能。本文适用于研究者、开发者以
-
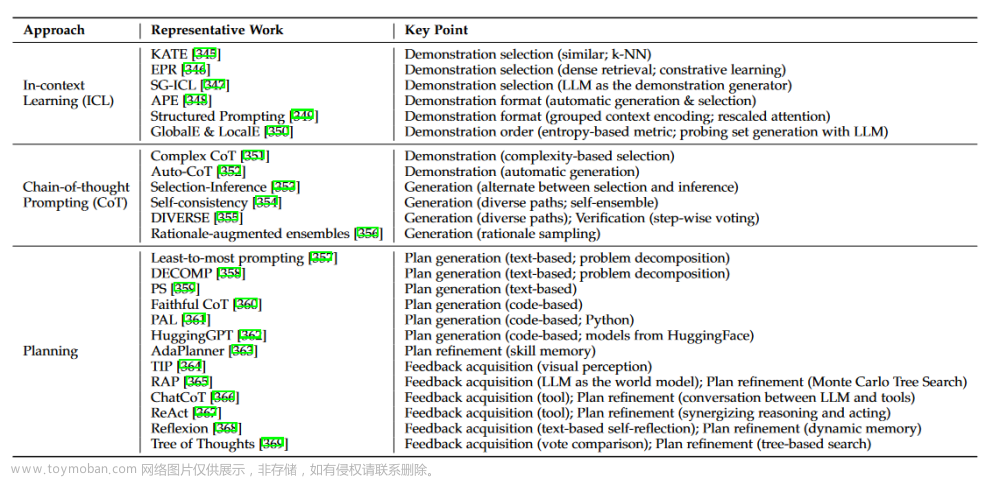
大语言模型(LLM)综述(五):使用大型语言模型的主要方法
随着人工智能和机器学习领域的迅速发展,语言模型已经从简单的词袋模型(Bag-of-Words)和N-gram模型演变为更为复杂和强大的神经网络模型。在这一进程中,大型语言模型(LLM)尤为引人注目,它们不仅在自然语言处理(NLP)任务中表现出色,而且在各种跨领域应用中也展示
-

大语言模型的多模态应用(多模态大语言模型的相关应用)
探索大语言模型在多模态领域的相关研究思路
-
![大语言模型的预训练[1]:基本概念原理、神经网络的语言模型、Transformer模型原理详解、Bert模型原理介绍](https://imgs.yssmx.com/Uploads/2024/02/580122-1.png)
大语言模型的预训练[1]:基本概念原理、神经网络的语言模型、Transformer模型原理详解、Bert模型原理介绍
预训练属于迁移学习的范畴。现有的神经网络在进行训练时,一般基于反向传播(Back Propagation,BP)算法,先对网络中的参数进行随机初始化,再利用随机梯度下降(Stochastic Gradient Descent,SGD)等优化算法不断优化模型参数。而预训练的思想是,模型参数不再是随机初始化的
-

大语言模型(LLM)综述(四):如何适应预训练后的大语言模型
随着人工智能和机器学习领域的迅速发展,语言模型已经从简单的词袋模型(Bag-of-Words)和N-gram模型演变为更为复杂和强大的神经网络模型。在这一进程中,大型语言模型(LLM)尤为引人注目,它们不仅在自然语言处理(NLP)任务中表现出色,而且在各种跨领域应用中也展示
-

大模型语言模型:从理论到实践
《大规模语言模型:从理论到实践》、复旦大学课件 链接/提取码:x7y6 大规模语言模型(Large Language Models,LLM),也称大语言模型或大型语言模型,是一种由包含数百亿以上参数的深度神经网络构建的语言模型,通常使用自监督学习方法通过大量无标注文本进行训练。 自2
-

《大型语言模型自然语言生成评估》综述
在快速发展的自然语言生成(NLG)评估领域中,引入大型语言模型(LLMs)为评估生成内容质量开辟了新途径,例如,连贯性、创造力和上下文相关性。本综述旨在提供一个关于利用LLMs进行NLG评估的全面概览,这是一个缺乏系统分析的新兴领域。 我们提出了一个连贯的分类体
-
自然语言处理:大语言模型入门介绍
随着自然语言处理(Natural Language Processing, NLP)的发展,此技术现已广泛应用于文本分类、识别和总结、机器翻译、信息提取、问答系统、情感分析、语音识别、文本生成等任务。 研究人员发现扩展模型规模可以提高模型能力,由此创造了术语——大语言模型(Large Language
-
LLM大语言模型算法特训,带你转型AI大语言模型算法工程师
LLM(大语言模型)是指大型的语言模型,如GPT(Generative Pre-trained Transformer)系列模型。以下是《LLM大语言模型算法特训,带你转型AI大语言模型算法工程师》课程可能包含的内容: 课程可能会介绍大语言模型的原理、架构和训练方法,包括Transformer架构、自注意力机制、预训
-

【AI链接】 大模型语言模型网站链接
https://chat.openai.com/ https://groq.com/ https://aistudio.google.com/app/prompts https://www.moonshot.cn/ Kimi.ai 可以将图片,pdf,或者网址等作为输入 https://kimi.moonshot.cn/ https://www.txyz.ai/ https://code.fittentech.com/
-
大模型一、大语言模型的背景和发展
本文系大模型专栏文章的第一篇文章,后续将陆续更新相关模型的技术,在 finetune、prompt、SFT、PPO等方向进行逐步更新,欢迎关注,也可私密需要实现的模型。 LLM全称Large Language Model(中文翻译,大型语言模型) 随着ChatGPT等大型语言模型的出现,自然语言处理领域掀起了新
-
【大模型】二 、大语言模型的基础知识
大型语言模型是近年来机器学习和自然语言处理领域的一个重要发展趋势。以GPT模型为例,阐述其发展 GPT系列基于Transformer架构,进行构建,旨在理解和生成人类语言。它们通常通过在大量文本数据上进行预训练,学习到语言的各种模式和结构,然后可以进行微调,以适应各