-
机器学习周刊 第4期:动手实战人工智能、计算机科学热门论文、免费的基于ChatGPT API的安卓端语音助手、每日数学、检索增强 (RAG) 生成技术综述
机器学习周刊第4期聚焦了AI实战教程、热门计算机科学论文、基于ChatGPT的安卓端语音助手、数学定理分享以及前沿的检索增强(RAG)生成技术综述。
-
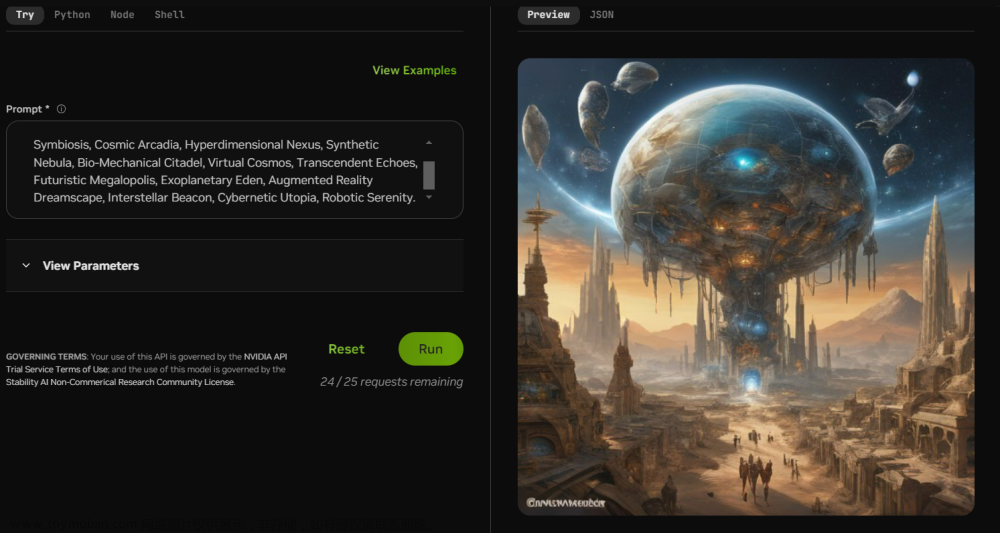
AI之LLM/MLM:Nvidia官网人工智能大模型工具合集(大语言模型/多模态模型,文本生成/图像生成/视频生成)的简介、使用方法、案例应用之详细攻略
AI之LLM/MLM:Nvidia官网人工智能大模型工具合集(大语言模型/多模态模型,文本生成/图像生成/视频生成)的简介、使用方法、案例应用之详细攻略 目录 Nvidia官网人工智能大模型工具合集的简介 1、网站主要功能包括: Nvidia官网人工智能大模型工具合集的使用方法 1、SDXL-Turbo的使
-

使用CLIP和LLM构建多模态RAG系统
在本文中我们将探讨使用开源大型语言多模态模型(Large Language Multi-Modal)构建检索增强生成(RAG)系统。本文的重点是在不依赖LangChain或LLlama index的情况下实现这一目标,这样可以避免更多的框架依赖。 在人工智能领域,检索增强生成(retrieve - augmented Generation, RAG)作为一种变革性
-
LLM、AGI、多模态AI 篇二:Prompt编写技巧
系列 LLM、AGI、多模态AI 篇一:开源大语言模型简记 LLM、AGI、多模态AI 篇二:Prompt编写技巧 LLM、AGI、多模态AI 篇三:微调模型
-

LLM之RAG实战(八)| 使用Neo4j和LlamaIndex实现多模态RAG
人工智能和大型语言模型领域正在迅速发展。一年前,没有人使用LLM来提高生产力。时至今日,很难想象我们大多数人或多或少都在使用LLM提供服务,从个人助手到文生图场景。由于大量的研究和兴趣,LLM每天都在变得越来越好、越来越聪明。不仅如此,他们的理解
-

LLM量化、高保真图生视频、多模态肢体运动生成、高分辨率图像合成、低光图像/视频增强、相机相对姿态估计
本文首发于公众号:机器感知 LLM量化、高保真图生视频、多模态肢体运动生成、高分辨率图像合成、低光图像/视频增强、相机相对姿态估计 EasyQuant: An Efficient Data-free Quantization Algorithm for LLMs Large language models (LLMs) have proven to be very superior to conventional methods in various tasks. Howev
-

大语言模型的多模态应用(多模态大语言模型的相关应用)
探索大语言模型在多模态领域的相关研究思路
-

【前沿技术杂谈:多模态文档基础模型】使用多模态文档基础模型彻底改变文档 AI
您是否曾经被包含不同信息(如应付账款、日期、商品数量、单价和金额)的发票所淹没?在处理重要的商业合同时,您是否担心小数点后点错误,造成无法估量的经济损失?您是否在寻找顶尖人才时阅读过大量简历?商务人士必须处理所有这些任务和各种各样的文件,包括
-
多模态大型语言模型综述
Authors: Davide Caffagni ; Federico Cocchi ; Luca Barsellotti ; Nicholas Moratelli ; Sara Sarto ; Lorenzo Baraldi ; Lorenzo Baraldi ; Marcella Cornia ; Rita Cucchiara Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are bei
-
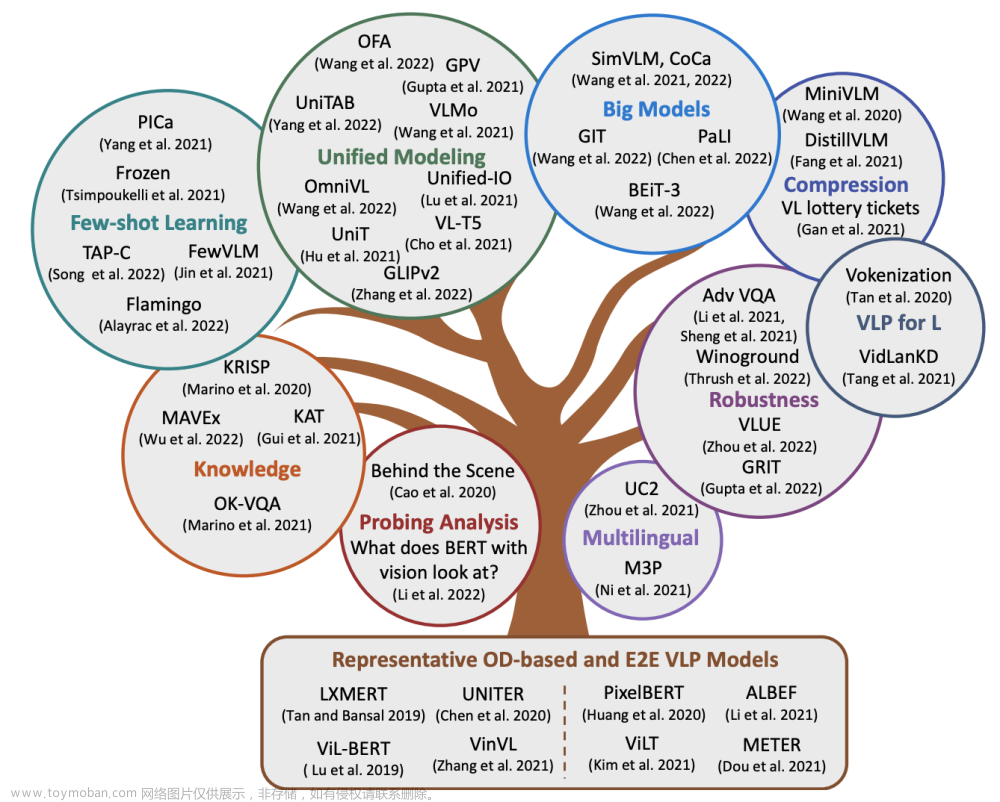
多模态预训练模型综述
经典预训练模型还未完成后续补上 预训练模型在NLP和CV上取得巨大成功,学术届借鉴预训练模型==下游任务finetune==prompt训练==人机指令alignment这套模式,利用多模态数据集训练一个大的多模态预训练模型(跨模态信息表示)来解决多模态域各种下游问题。 多模态预训练大模型
-

多模态模型技术综述
多模态学习是指从不同输入模态学习表示的过程,例如图像数据、文本或语音。由于自然语言处理(NLP)和计算机视觉(CV)领域的方法学突破,多模态模型因其能够增强预测和更好地模拟人类学习的方式而受到越来越多的关注。本文重点讨论图像和文本作为输入数据。该文
-
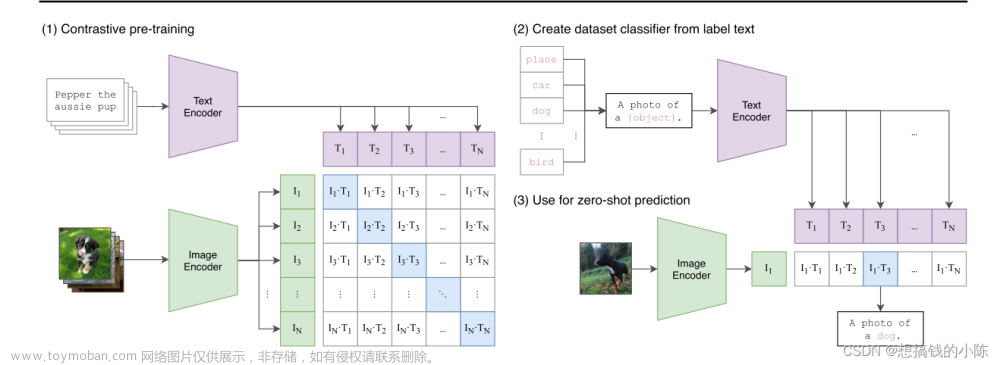
【多模态】CLIP模型
Title : Learning transferable visual models from natural language supervision 作者 :Alec Radford * 1 Jong Wook Kim * 1 Chris Hallacy 1 Aditya Ramesh 1 Gabriel Goh 1 Sandhini Agarwal Girish Sastry 1 Amanda Askell 1 Pamela Mishkin 1 Jack Clark 1 Gretchen Krueger 1 Ilya Sutskever 1 发表单位 :OpenAI, San Francisco :clip、多模态 论文:
-

图-文多模态,大模型,预训练
参考老师的无敌课程 多模态任务是指需要同时处理两种或多种不同类型的数据(如图像、文本、音频等)的任务。例如,图像描述(image captioning)就是一种典型的多模态任务,它需要根据给定的图像生成相应的文本描述。多模态任务在人工智能领域具有重要的意义和应用价