-

大容量分布式数据处理中倾斜数据集的处理方法
在现代计算领域,我们在计算领域取得了很多进步和快速发展。市场上有如此多的分布式处理软件,处理模式正在频繁地变化。这些软件提供了强大的功能,可以通过高度可扩展的架构来处理大量数据,从而提供根据处理需求动态扩展和缩小的灵活性。 许多分布式软件被组织
-
数据仓库与数据湖的实时处理与分布式处理
数据仓库和数据湖都是在大数据领域中广泛应用的数据管理方法,它们在数据存储、处理和分析方面有很大的不同。数据仓库是一个用于存储和管理历史数据的系统,通常用于数据分析和报表。数据湖则是一个用于存储和管理大量数据的系统,包括结构化数据、非结构化数据
-
大数据分布式实时大数据处理框架Storm,入门到精通!
介绍:Storm是一个分布式实时大数据处理框架,被业界称为实时版的Hadoop。 首先,Storm由Twitter开源,它解决了Hadoop MapReduce在处理实时数据方面的高延迟问题。Storm的设计目标是保证数据的实时处理,它可以在数据流入系统的同时进行处理,这与传统的先存储后处理的关系型数
-
数据流处理中的分布式存储:保护数据隐私和安全
作者:禅与计算机程序设计艺术 随着数据量的爆炸式增长,如何高效地处理和存储数据成为了当前热门的研究方向。数据流处理作为一种处理数据的方法,能够在实时性、流式性和可扩展性等方面提供优势。在数据流处理中,分布式存储是保障数据隐私和安全的重要手段。本
-
RisingWave分布式SQL流处理数据库调研
RisingWave是一款 分布式SQL流处理数据库 ,旨在帮助用户降低实时应用的的开发成本。作为专为云上分布式流处理而设计的系统,RisingWave为用户提供了与PostgreSQL类似的使用体验,官方宣称具备比Flink高出10倍的性能(指throughput)以及更低的成本。RisingWave开发只需要关注SQL开发
-

Hadoop是一个开源的分布式处理系统,主要用于处理和存储大量数据
Hadoop是一个开源的分布式处理系统,主要用于处理和存储大量数据。它是由Apache软件基金会开发的,现在已经成为大数据领域中广泛使用的技术之一。 Hadoop架构 Hadoop的架构包括以下几个主要组件: Hadoop Distributed File System (HDFS) : HDFS是Hadoop的核心组件之一,它是一个分布式文
-
云计算与大数据处理:分布式系统与集群技术
随着互联网的不断发展,数据的产生和存储量日益庞大,传统的单机计算方式已经无法满足需求。因此,分布式系统和集群技术逐渐成为了解决大数据处理问题的重要手段。 分布式系统是指由多个独立的计算机节点组成的系统,这些节点可以在网络上进行通信和协同工作。集
-

在macOS上安装Hadoop: 从零到分布式大数据处理
要在 macOS 上安装 Hadoop,您可以按照以下步骤进行操作: 前往Hadoop的官方网站下载最新版本的Hadoop。选择一个稳定的发行版本并下载压缩文件(通常是.tar.gz格式)。 将下载的 Hadoop 压缩文件解压缩到您选择的目录中。可以使用终端执行以下命令: 请将 hadoop-version 替换为您下
-
云计算与大数据第15章 分布式大数据处理平台Hadoop习题带答案
1、分布式系统的特点不包括以下的( D )。 A. 分布性 B. 高可用性 C. 可扩展性 D.串行性 2、Hadoop平台中的( B )负责数据的存储。 A. Namenode B. Datanode C. JobTracker D. SecondaryNamenode 3、HDFS中block的默认副本数量是( A )。 A.3
-
分布式计算中的大数据处理:Hadoop与Spark的性能优化
大数据处理是现代计算机科学的一个重要领域,它涉及到处理海量数据的技术和方法。随着互联网的发展,数据的规模不断增长,传统的计算方法已经无法满足需求。因此,分布式计算技术逐渐成为了主流。 Hadoop和Spark是目前最为流行的分布式计算框架之一,它们都提供了高
-
数据存储和分布式计算的实际应用:如何使用Spark和Flink进行数据处理和分析
作为一名人工智能专家,程序员和软件架构师,我经常涉及到数据处理和分析。在当前大数据和云计算的时代,分布式计算已经成为了一个重要的技术方向。Spark和Flink是当前比较流行的分布式计算框架,它们提供了强大的分布式计算和数据分析功能,为数据处理和分析提供了
-
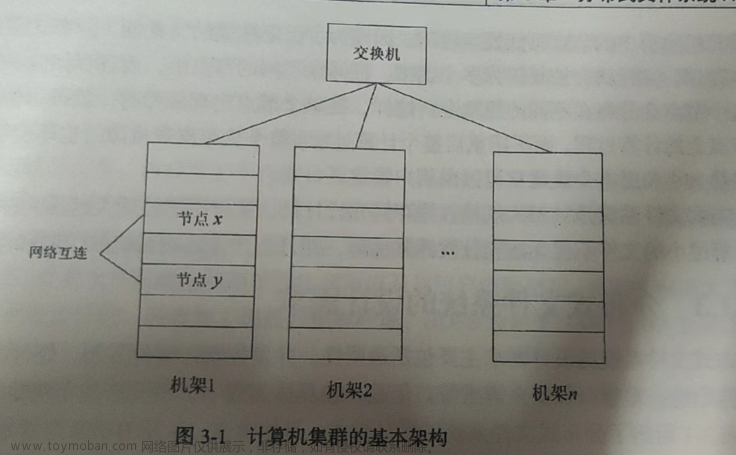
大数据技术原理与应用 概念、存储、处理、分析和应用(林子雨)——第三章 分布式文件系统HDFS
大数据要解决数据存储问题,所以有了分布式文件系统(DFS),但可能不符合当时的一些应用需求,于是谷歌公司开发了GFS(Google file System)。GFS是闭源的,而HDFS是对GFS的开源实现。 1.GFS和DFS有什么区别? GFS(Google File System)和DFS(Distributed File System)都是分布式文件系统,
-
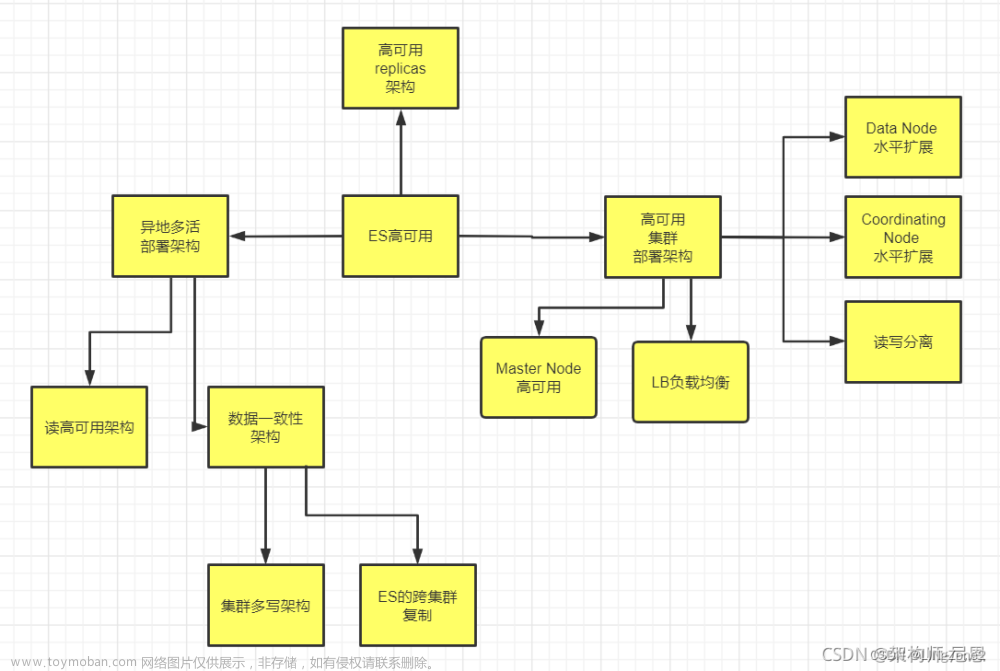
ES是一个分布式全文检索框架,隐藏了复杂的处理机制,核心数据分片机制、集群发现、分片负载均衡请求路由
ES是一个分布式框架,隐藏了复杂的处理机制,核心数据分片机制、集群发现、分片负载均衡请求路由。 ES的高可用架构,总体如下图: 说明:本文会以pdf格式持续更新,更多最新尼恩3高pdf笔记,请从下面的链接获取:语雀 或者 码云 ES基本概念名词 Cluster 代表一个集群,集
-

分布式调用与高并发处理 Zookeeper分布式协调服务
单机架构 一个系统业务量很小的时候所有的代码都放在一个项目中就好了,然后这个项目部署在一台服务器上,整个项目所有的服务都由这台服务器提供。 缺点: 服务性能存在瓶颈,用户增长的时候性能下降等。 不可伸缩性 代码量庞大,系统臃肿,牵一发动全身 单点故障
-

微服务分布式事务处理
当我们向微服务架构迁移时,如何处理好分布式事务是必须考虑的问题。这篇文章介绍了分布式事务处理的两种方案,可以结合实际采用合适的解决方案。原文:Handling Distributed Transactions in the Microservice world [1] 如今每个人(包括我)都在思考、构建微服务,分布式系统是微服