-
Flink单机版安装教程 - 步骤详解
本教程详细介绍了如何在单机环境下安装和启动Apache Flink 1.16.0版本。包括下载稳定版安装包,使用tar命令解压,以及通过start-cluster.sh脚本启动Flink集群。
-

【Flink-1.17-教程】-【二】Flink 集群搭建、Flink 部署、Flink 运行模式
集群规划: 具体安装部署步骤如下: 1、下载并解压安装包 (1)下载安装包 flink-1.17.0-bin-scala_2.12.tgz,将该 jar 包上传到 hadoop102 节点服务器的 /opt/software 路径上。 (2)在 /opt/software 路径上解压 flink-1.17.0-bin-scala_2.12.tgz 到 /opt/module 路径上。 2、修改集群配置 (1)进入 conf 路
-

Flink 学习七 Flink 状态(flink state)
流式计算逻辑中,比如sum,max; 需要记录和后面计算使用到一些历史的累计数据, 状态就是 :用户在程序逻辑中用于记录信息的变量 在Flink 中 ,状态state 不仅仅是要记录状态;在程序运行中如果失败,是需要重新恢复,所以这个状态也是需要持久化;一遍后续程序继续运行 1.1 row state 我
-

Flink|《Flink 官方文档 - 概念透析 - Flink 架构》学习笔记
学习文档:概念透析 - Flink 架构 学习笔记如下: 客户端(Client):准备数据流程序并发送给 JobManager(不是 Flink 执行程序的进程) JobManager:协调 Flink 应用程序的分布式执行 ResourceManager:负责 Flink 集群中的资源提供、回收、分配 Dispatcher:提供了用来提交 Flink 应用程序执行
-

【Flink-1.17-教程】-【一】Flink概述、Flink快速入门
在准备好所有的开发环境之后,我们就可以开始开发自己的第一个 Flink 程序了。首先我们要做的,就是在 IDEA 中搭建一个 Flink 项目的骨架。我们会使用 Java 项目中常见的 Maven 来进行依赖管理。 1、创建工程 (1)打开 IntelliJ IDEA,创建一个 Maven 工程。 (2)将这个 Maven 工程命
-

大数据Flink(五十一):Flink的引入和Flink的简介
文章目录 Flink的引入和Flink的简介 一、Flink的引入 1、第1代——Hadoop MapReduce
-

Flink on Kubernetes (flink-operator) 部署Flink
https://nightlies.apache.org/flink/flink-kubernetes-operator-docs-release-1.1/docs/try-flink-kubernetes-operator/quick-start/ 我的部署脚本和官网不一样,有些地方官网不够详细 注意,按照默认配置至少有两台worker https://helm.sh/zh/docs/intro/install/ 安装完成后,资源如下 此时k8s集群就可以支持我们按照fli
-
![[Flink01] 了解Flink](https://imgs.yssmx.com/Uploads/2024/02/827570-1.png)
[Flink01] 了解Flink
Flink入门系列文章主要是为了给想学习Flink的你建立一个大体上的框架,助力快速上手Flink。学习Flink最有效的方式是先入门了解框架和概念,然后边写代码边实践,然后再把官网看一遍。 Flink入门分为四篇,第一篇是《了解Flink》,第二篇《架构和原理》,第三篇是《DataStre
-
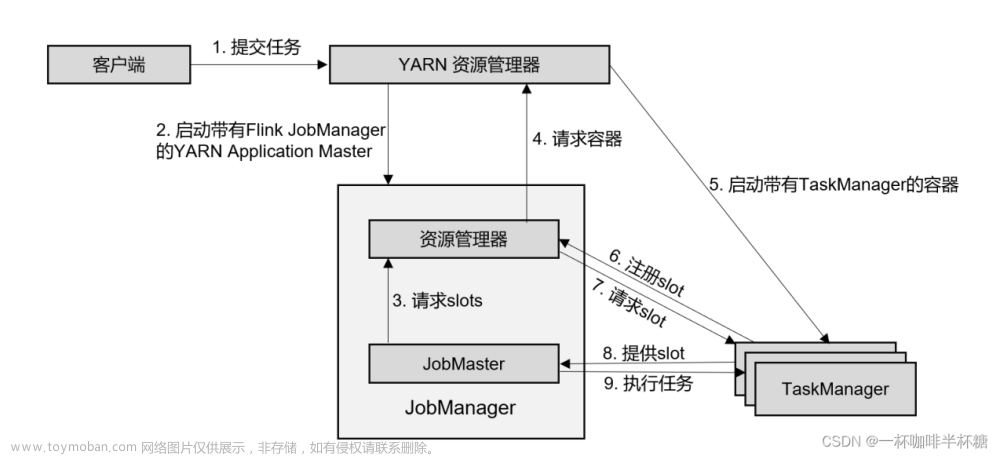
【Flink】Flink提交流程
我们通常在学习的时候需要掌握大数据组件的原理以便更好的掌握这个大数据组件,Flink实际生产开发过程中最常见的就是提交到yarn上进行调度,模式使用的 Per-Job模式,下面我们就给大家讲下Flink提交Per-Job任务到yarn上的流程,流程图如下 (1)客户端将作业提交给 YARN 的资
-

深入理解 Flink(六)Flink Job 提交和 Flink Graph 详解
深入理解 Flink 系列文章已完结,总共八篇文章,直达链接: 深入理解 Flink (一)Flink 架构设计原理 深入理解 Flink (二)Flink StateBackend 和 Checkpoint 容错深入分析 深入理解 Flink (三)Flink 内核基础设施源码级原理详解 深入理解 Flink (四)Flink Time+WaterMark+Window 深入分析 深入
-

【Flink】Flink架构及组件
我们学习大数据知识的时候,需要知道大数据组件如何安装以及架构组件,这将帮助我们更好的了解大数据组件 对于大数据Flink,架构图图下: 整个架构图有三种关键组件 1、Client:负责作业的提交。调用程序的 main 方法,将代码转换成“数据流图“(DataflowGraph),并最终
-

【Flink】1.Flink集群部署
Flink可以部署于各种各样的集群之中,比如Flink自己的standalone集群(不依赖于其他资源调度框架,是Flink自带的),flink on yarn集群等。而不管是standalone还是flink on yarn都属于集群,还有一种特殊的单机flink——local。 Flink真正用来做执行操作的叫做worker,进程在不同的环境模式
-

Flink理论—Flink架构设计
Flink 是一个分布式系统,需要有效分配和管理计算资源才能执行流应用程序。它集成了所有常见的集群资源管理器,例如Hadoop YARN,但也可以设置作为独立集群甚至库运行,例如Spark 的 Standalone Mode 本节概述了 Flink 架构,并且描述了其主要组件如何交互以执行应用程序和从故障
-

Flink实战(1)-了解Flink
😄伙伴们,好久不见!这里是 叶苍ii ❀ 作为一名大数据博主,我一直致力于分享最新的技术趋势和实战经验。近期,我在参加Flink的顾客营销项目,使用了PyFlink项目进行数据处理和分析。 ❀ 在这个文章合集中,我将与大家分享我的实战
-
![[Flink04] Flink部署实践](https://imgs.yssmx.com/Uploads/2024/02/828151-1.png)
[Flink04] Flink部署实践
Flink部署支持三种模式:本地部署、Standalone部署、Flink on Yarn部署。 独立(Standalone)模式由Flink自身提供资源,无需其他框架,这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但Flink 是大数据计算框架,不是资源调度框架,这并不是它的强项;所以