
Java应用程序的优化方法:如何实现并行处理和结果聚合?
了解如何通过并行处理和结果聚合来优化Java应用程序的性能和可伸缩性。探索Java的并发API、Stream API以及结果聚合技术,同时遵循最佳实践和注意事项。

Elasticsearch聚合学习之四:结果排序,阿里云java面试
返回结果如下,已经按照key的大小从大到小排序: … “aggregations” : { “price” : { “buckets” : [ { “key” : 80000.0, “doc_count” : 1 }, { “key” : 60000.0, “doc_count” : 0 }, { “key” : 40000.0, “doc_count” : 0 }, { “key” : 20000.0, “doc_count” : 4 }, { “key” : 0.0, “doc_count” : 3 } ] } } }

原生语言操作和spring data中RestHighLevelClient操作Elasticsearch,索引,文档的基本操作,es的高级查询.查询结果处理. 数据聚合.相关性系数打分
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasti
Java Stream对象并行处理方法parallel()
Stream.parallel() 方法是 Java 8 中 Stream API 提供的一种并行处理方式。在处理大量数据或者耗时操作时,使用 Stream.parallel() 方法可以充分利用多核 CPU 的优势,提高程序的性能。本文将从以下几个方面对 Stream.parallel() 进行详解。 什么是 Stream.parallel() 方法
Java使用线程池异步处理并返回结果
1.1、@Bean注入的线程池 1.2、注入线程池处理异步任务

Jmeter压测结果分析之聚合报告
当我们进行压压力测试完后,最关心就是测试数据了。 1、聚合报告参数 在分析聚合报告之前,我们先来了解聚合报告都包含了什么内容 Aggregate Report(聚合报告)参数: 平均值:平均响应时间,所有请求的平均响应时间。 中位数:50%的用户响应时间不超过这个值。 99% Line: 9
使用 Java 流进行分组和聚合,高效处理大量数据不再是梦!
了解使用 Java Streams 解决问题的直接途径,Java Streams 是一个允许我们快速有效地处理大量数据的框架。 当我们对列表中的元素进行分组时,我们可以随后聚合分组元素的字段以执行有意义的操作,帮助我们分析数据。一些示例是加法、平均值或最大值/最小值。这些单个字段

Elasticsearch 聚合数据结果不精确问题解决方案
近期我们项目中出现使用ES聚合某个索引的数据取TOP 10的数据和相同条件下查询所有数据然后按数据量排序取的TOP 10的数据不一致的问题。 下面我们简单分析一下这个问题,列出一些常见的解决方案。 Elasticsearch分片机制 Elasticsearch索引(index)有一个主分片(primary shard)和
ES 使用 Bucket Sort 对聚合结果分页
在 Elasticsearch 中,Bucket Sort 是一种聚合操作,用于对桶(bucket)进行排序。它可以根据指定的字段对聚合结果中的桶进行排序,以便按照特定的顺序呈现数据。 Bucket Sort 和 Top Hits 有相似之处,他们之间的区别是:Bucket 是对聚合分桶的排序和分页,而 Top Hits 是对分桶聚合中每
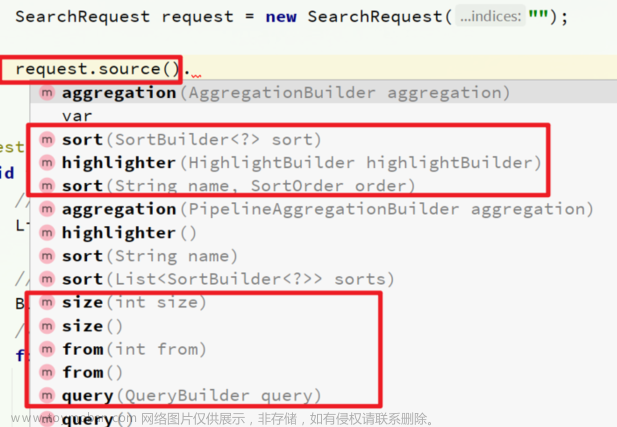
【ElasticSearch】使用 Java 客户端 RestClient 实现对文档的查询操作,以及对搜索结果的排序、分页、高亮处理
在 Elasticsearch 中,通过 RestAPI 进行 DSL 查询语句的构建通常是通过 HighLevelRestClient 中的 resource() 方法来实现的。该方法包含了查询、排序、分页、高亮等所有功能,为构建复杂的查询提供了便捷的接口。 RestAPI 中构建查询条件的核心部分是由一个名为 QueryBuilders 的工具类提供
ES中使用 Top Hits 查询分桶聚合结果的每个桶的详细数据
Top hits(顶部命中)是一个聚合功能,用于在查询结果中返回每个桶(bucket)中的顶部 N 个文档。这对于需要在聚合结果中查看每个桶中的最相关或最高评分文档的情况非常有用。 简单来说,Top Hits 就是对聚合结果中相关文档的详细展示,它不同于 Post Filter,Post Filter 是基于

java: JPS 增量注解进程已禁用。部分重新编译的编译结果可能不准确。使用构建进程“jps.track.ap.dependencies”VM 标志启用/禁用增量注解处理环境
idea运行报错: JPS 增量注解进程已禁用。部分重新编译的编译结果可能不准确。使用构建进程“jps.track.ap.dependencies”VM 标志启用/禁用增量注解处理环境 1、运行时,后续引用的jar包、Maven依赖都不能用,提示“不存在xxxxx” 2、并不影响打包和包的使用 同事的开发工具和我的不

C#中的并行处理、并行查询的方法你用对了吗?
Parallel.ForEach 是一个用于在集合上并行执行迭代操作的强大工具。它通过有效地利用多核处理器的能力来提高性能。Parallel.ForEach 不仅能够简化并行编程,而且它在执行简单循环时可以提供比传统迭代更好的性能。 下面是一个简单的示例,演示了如何使用 Parallel.ForEach 并行
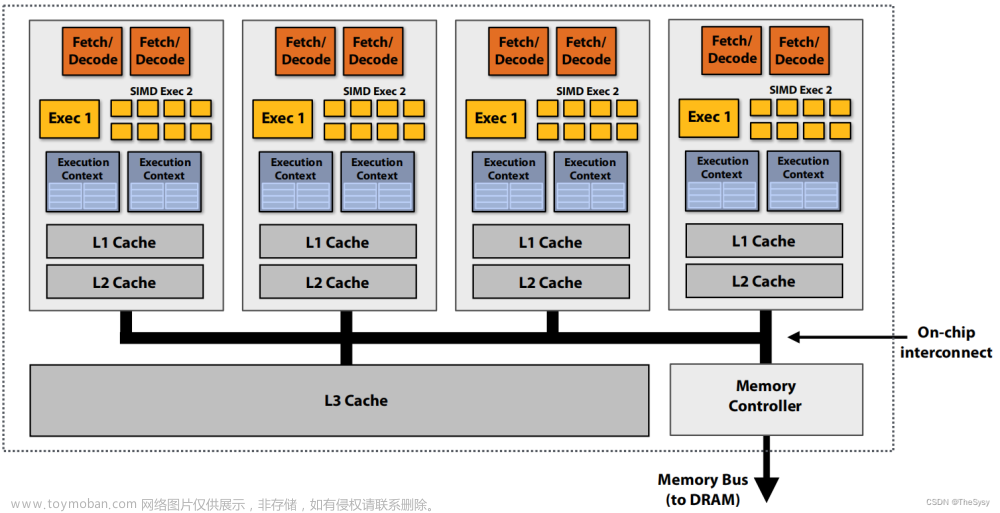
【并行计算】多核处理器
这张图连接了几个并行计算的思想。 从上往下。 1.两个fetch/decode部件,是 superscalar 技术,每个cycle可以发射多个指令。 2.多个执行单元,支持乱序执行,是ILP, 指令级并行 。 3.每个执行单元里还支持 SIMD 操作。 4.有多个execution context,就相当于是有多套线程的状态,类似寄
第17 章 并行处理
在微操作层面上,多个控制信号同时产生。 指令流水线已经存在很长一段时间,至少在取指和执行是重叠的。对于超标量计算机,在一个处理器中多个执行单元,它们并行执行一个程序中多条指令。 计算机设计人员寻求越来越多的并行机会,一般都是为了提高性能,有时是