-
Stable Diffusion 新手入门手册
探索Stable Diffusion的无限可能:本手册为新手提供详细的入门指导,包括提示词权重调整技巧、Prompt Editing语法、Token理解以及Controlnet图像控制方法。
-
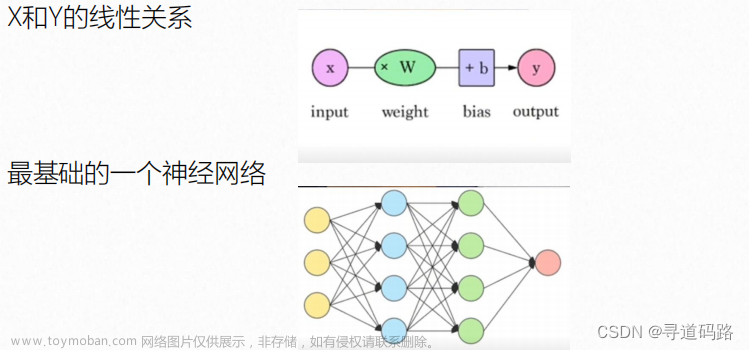
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
在人工智能的宏伟蓝图中,大语言模型(LLM)的预训练是构筑智慧之塔的基石。预训练过程通过调整庞大参数空间以吸纳数据中蕴含的知识,为模型赋予从语言理解到文本生成等多样化能力。本文将深入探讨预训练过程中的技术细节、所面临的挑战、通信机制、并行化策略以
-
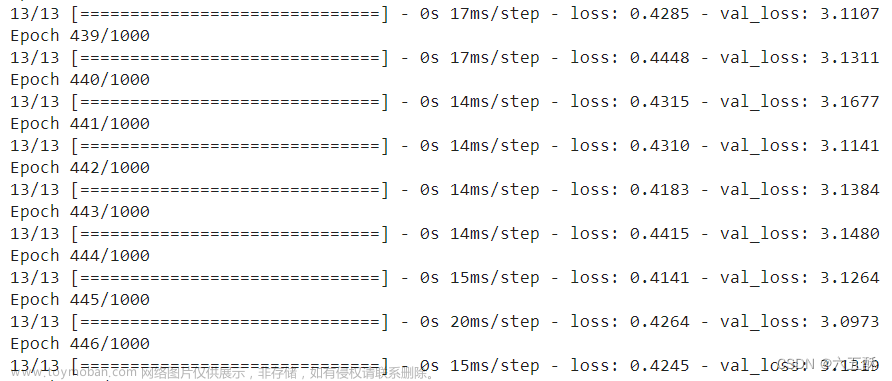
【如何训练一个中英翻译模型】LSTM机器翻译模型训练与保存(二)
【如何训练一个中英翻译模型】LSTM机器翻译seq2seq字符编码(一) 【如何训练一个中英翻译模型】LSTM机器翻译模型训练与保存(二) 【如何训练一个中英翻译模型】LSTM机器翻译模型部署(三) 【如何训练一个中英翻译模型】LSTM机器翻译模型部署之onnx(python)(四) 基于
-

【3】使用YOLOv8训练自己的目标检测数据集-【收集数据集】-【标注数据集】-【划分数据集】-【配置训练环境】-【训练模型】-【评估模型】-【导出模型】
云服务器训练YOLOv8-新手教程-哔哩哔哩 🍀2023.11.20 更新了划分数据集的脚本 在自定义数据上训练 YOLOv8 目标检测模型的步骤可以总结如下 6 步: 🌟收集数据集 🌟标注数据集 🌟划分数据集 🌟配置训练环境 🌟训练模型 🌟评估模型 随着深度学习技术在计算机视觉领域的广泛
-
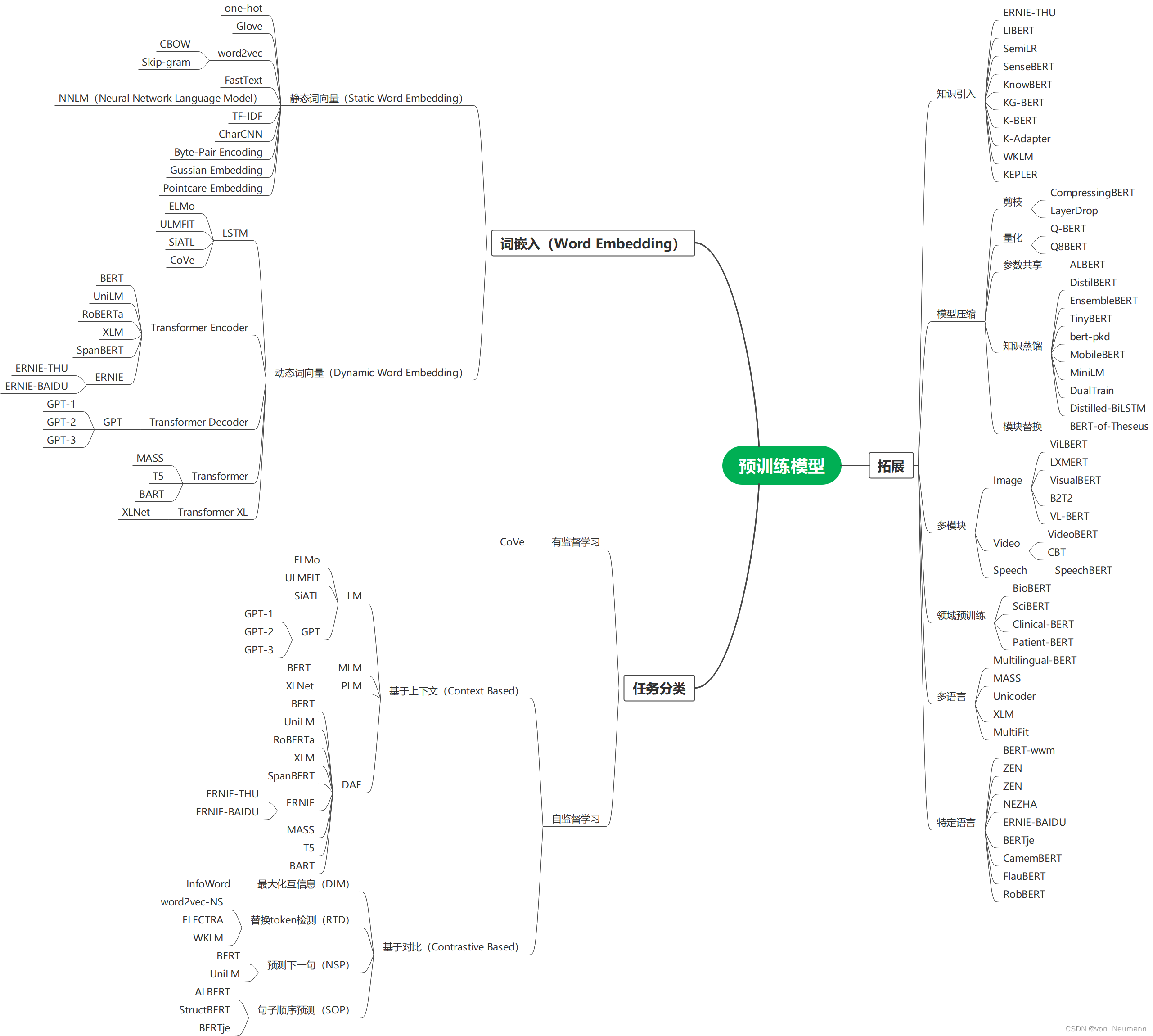
自然语言处理从入门到应用——预训练模型总览:预训练模型的拓展
分类目录:《自然语言处理从入门到应用》总目录 相关文章: · 预训练模型总览:从宏观视角了解预训练模型 · 预训练模型总览:词嵌入的两大范式 · 预训练模型总览:两大任务类型 · 预训练模型总览:预训练模型的拓展 · 预训练模型总览:迁移学习与微调 · 预训练模型
-
Tensorflow实现训练数据的加载—模型搭建训练保存—模型调用和加载全流程
将tensorflow的训练数据数组(矩阵)保存为.npy的数据格式。为后续的模型训练提供便捷的方法。例如如下: 加载.npy训练数据和测试数组(矩阵),加载后需要调整数据的形状以满足设计模型的输入输出需求,不然无法训练模型。 这里可以采用自定义层和tensorflow的API搭建
-

AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化
AI大模型探索之路-训练篇1:大语言模型微调基础认知 AI大模型探索之路-训练篇2:大语言模型预训练基础认知 AI大模型探索之路-训练篇3:大语言模型全景解读 AI大模型探索之路-训练篇4:大语言模型训练数据集概览 在自然语言处理领域,大语言模型预训练数据准备是一个重
-
Llama中文大模型-模型预训练
Atom系列模型包含Atom-7B和Atom-13B,基于Llama2做了中文能力的持续优化。Atom-7B和Atom-7B-Chat目前已完全开源,支持商用,可在Hugging Face仓库获取模型: https://huggingface.co/FlagAlpha 大规模的中文数据预训练 原子大模型Atom在Llama2的基础上,采用大规模的中文数据进行持续预训练,包含百
-
一文看懂预训练和自训练模型
说到预训练模型,不得不提 迁移学习 了,由于很多数据不是标签数据,人工标注非常耗时,神经网络在很多场景下受到了限制。但是迁移学习和自学习的出现,在一定程度上缓解甚至解决了这个问题。我们可以在标签丰富的场景下进行有监督的训练,或者在无标签
-

GPT模型训练实践(3)-参数训练和代码实践
GPT模型参数的训练过程宏观上有两个大环节,先从上往下进行推理,再从下往上进行训练,具体过程为: 1、模型初始化参数随机取得; 2、计算模型输出与真实数据的差距(损失值和梯度) 3、根据损失值,反向逐层调整权重参数; 如下图: 参数的生命周期分
-
![[玩转AIGC]LLaMA2训练中文文章撰写神器(数据准备,数据处理,模型训练,模型推理)](https://imgs.yssmx.com/Uploads/2024/01/799326-1.png)
[玩转AIGC]LLaMA2训练中文文章撰写神器(数据准备,数据处理,模型训练,模型推理)
好久没更新这个专栏的文章了,今天抽空写了一篇。————2023.12.28 摘要:文体包括新闻,法律文书,公告,广告等,每种文体的书写风格不一样,如果拥有自己的数据集,想针对特定文体来训练一个内容生成的工具,来帮助自己写点文章,如果没接触过AIGC,可能一开始会
-

第四章 模型篇:模型训练与示例
在pytorch_tutorial中给出了一个训练流程的简要介绍: Training a model is an iterative process;训练模型是一个迭代的过程。 in each iteration the model makes a guess about the output, calculates the error in its guess (loss), 在每次迭代中,模型会对输出结果做一个猜测,并且计算这个结果和目标结果之间的
-

【AI大模型】训练Al大模型
前言 洁洁的个人主页 我就问你有没有发挥! 知行合一,志存高远。 目前所指的大模型,是“大规模深度学习模型”的简称,指具有大量参数和复杂结构的机器学习模型,可以处理大规模的数据和复杂的问题,多应用于自然语言处理、计算机视觉、语音识别等领域。大模型具
-
[大模型] 搭建llama主流大模型训练环境
:大模型,LLAMA,CUDA,模型训练 OS: Ubuntu 18.04 GPU: 4*A100(40G) (单机4卡A100 40G) CUDA: 11.7 cuDNN: 8.4.1 (需要登录官网后下载) nccl: 2.12.12 (需要登录官网后下载) python: 3.10 ( conda create -n vllm python=3.10 ) pytorch: 2.0.0+cu117 离线安装包地址 LLaMA-7B/13B/30B/65B模型: 下载地址,需要
-

【深度学习】训练模型结果同时显示,模型结果对比
码字不易,如果各位看官感觉该文章对你有所帮助,麻烦点个关注,如果有任何问题,请留言交流。如需转载,请注明出处,谢谢。 文章链接:【深度学习】训练模型结果同时显示,模型结果对比_莫克_Cheney的博客-CSDN博客 目录 目录 一、问题描述 二、解决方案 三、实验结果