-
PySpark大数据教程:深入学习SparkCore的RDD持久化和Checkpoint
本教程详细介绍了PySpark中SparkCore的RDD持久化和Checkpoint功能,重点讲解了缓存和检查点的作用、如何进行缓存、如何设置检查点目录以及它们之间的区别。还提供了join操作的示例和Spark算子补充知识。
-

【Python】PySpark 数据处理 ② ( 安装 PySpark | PySpark 数据处理步骤 | 构建 PySpark 执行环境入口对象 )
执行 Windows + R , 运行 cmd 命令行提示符 , 在命令行提示符终端中 , 执行 命令 , 安装 PySpark , 安装过程中 , 需要下载 310 M 的安装包 , 耐心等待 ; 安装完毕 : 命令行输出 : 如果使用 官方的源 下载安装 PySpark 的速度太慢 , 可以使用 国内的 镜像网站 https://pypi.tuna.tsinghua.edu.cn/simple
-

Python大数据之PySpark(二)PySpark安装
1-明确PyPi库,Python Package Index 所有的Python包都从这里下载,包括pyspark 2-为什么PySpark逐渐成为主流? http://spark.apache.org/releases/spark-release-3-0-0.html Python is now the most widely used language on Spark. PySpark has more than 5 million monthly downloads on PyPI, the Python Package Index. 记住如果安装特定的版本
-

pyspark笔记:读取 & 处理csv文件 (pyspark DataFrame)
pyspark cmd上的命令 pyspark中是惰性操作,所有变换类操作都是延迟计算的,pyspark只是记录了将要对数据集进行的操作 只有需要数据集将数据返回到 Driver 程序时(比如collect,count,show之类),所有已经记录的变换操作才会执行 注意读取出来的格式是Pyspark DataFrame,不是DataFr
-

Pyspark综合案例(pyspark安装和java运行环境配置)
一、RDD对象 PySpark支持多种数据的输入,在输入完成后,都会得到一个:RDD类的对象 RDD全称为:弹性分布式数据集(Resilient Distributed Datasets) PySpark针对数据的处理,都是以RDD对象作为载体,即: 数据存储在RDD内 各类数据的计算方法,也都是RDD的成员方法 RDD的数据计算方法
-

PySpark数据分析基础:PySpark Pandas创建、转换、查询、转置、排序操作详解
目录 前言 一、Pandas数据结构 1.Series 2.DataFrame 3.Time-Series 4.Panel 5.Panel4D 6.PanelND 二、Pyspark实例创建 1.引入库 2.转换实现 pyspark pandas series创建 pyspark pandas dataframe创建 from_pandas转换 Spark DataFrame转换 三、PySpark Pandas操作 1.读取行列索引 2.内容转换为数组 3.DataFrame统计描述 4.转
-
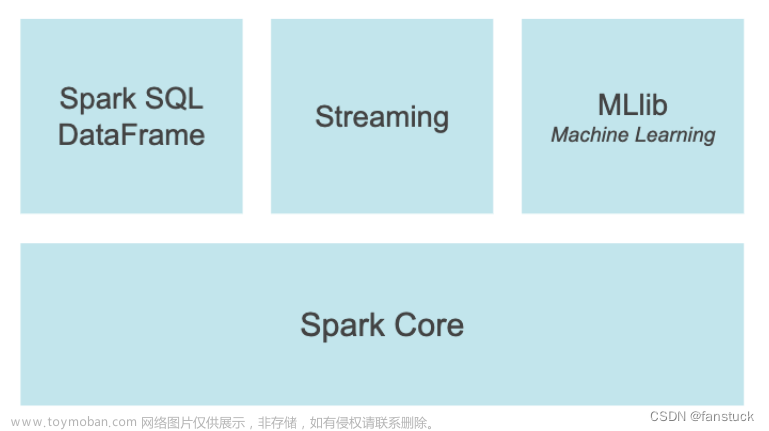
PySpark数据分析基础:PySpark基础功能及DataFrame操作基础语法详解
目录 前言 一、PySpark基础功能 1.Spark SQL 和DataFrame 2.Pandas API on Spark 3.Streaming 4.MLBase/MLlib 5.Spark Core 二、PySpark依赖 Dependencies 三、DataFrame 1.创建 创建不输入schema格式的DataFrame 创建带有schema的DataFrame 从Pandas DataFrame创建 通过由元组列表组成的RDD创建 2.查看 DataFrame.show() spark.sql.
-
Pyspark交互式编程
Pyspark交互式编程 有该数据集Data01.txt 该数据集包含了某大学计算机系的成绩,数据格式如下所示: 根据给定的数据集,在pyspark中通过编程来完成以下内容: 该系总共有多少学生; (提前启动好pyspark) 该系共开设了多少门课程; Tom同学的总成绩平均分是多少; 求每名同学的
-

Pyspark 基础知识
PySpark 是Spark官方提供的一个Python类库,内置了完全的Spark API,可以通过PySpark类库来编写Spark应用程序,并将其提交到Spark集群中运行。在安装好的Spark集群中,bin/pyspark 是一个交互式的程序,可以提供交互式编程并执行Spark计算。 PySpark和Spark框架对比: Spark集群(Yarn)角色
-
PySpark完美安装
一、hadoop版本号确认 1. hadoop == 2.7.2 [root@dm46 TDH-Client]# hadoop version Hadoop 2.7.2-transwarp-6.2.0 Subversion http://xxxx:10080/hadoop/hadoop-2.7.2-transwarp.git -r f31230971c2a36e77e4886e0f621366826cec3a3 Compiled by jenkins on 2019-07-27T11:33Z Compiled with protoc 2.5.0 二、下载spark 注意:选择 Pre-built for Apache Hadoop 2.7 http
-

【Python】PySpark
前言 Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。 简单来说,Spark是一款分布式的计算框架,用于调度成百上千的服务器集群,计算TB、PB乃至EB级别的海量数据。 Spark对Python语言的支持,重点体现在Python第三方库:PySpark PySpark是由Spark官方开发
-
Pyspark特征工程--MinHashLSH
MinHashLSH class pyspark.ml.feature.MinHashLSH ( inputCol=None , outputCol=None , seed=None , numHashTables=1 ) Jaccard 距离的 LSH 类 输入可以是密集或稀疏向量,但如果是稀疏的,则效率更高。 例如 Vectors.sparse(10, [(2, 1.0), (3, 1.0), (5, 1.0)]) 表示空间中有 10 个元素。 该集合包含元素 2、3 和 5。此外,任何
-

PySpark-核心编程
gitee仓库:gitee仓库 觉得有用的话,点个赞,点个收藏呗 给人点赞,手留余香 Spark RDD 编程的程序入口对象是 SparkContext 对象(不论何种编程语言) 只有构建出 SparkContext , 基于它才能执行后续的API调用和计算 本质上, SparkContext 对编程来说, 主要功能就是创建第一个RDD出来 代码演
-

PySpark入门
1,通过pyspark进入pyspark单机交互式环境。 这种方式一般用来测试代码。 也可以指定jupyter或者ipython为交互环境。 2,通过spark-submit提交Spark任务到集群运行。 这种方式可以提交Python脚本或者Jar包到集群上让成百上千个机器运行任务。 这也是工业界生产中通常使用spark的方式。
-
PySpark 线性回归
Spark ML 是 Spark 提供的一个机器学习库,用于构建和训练机器学习模型。它提供了一系列常用的机器学习算法和工具,包括分类、回归、聚类、模型评估等。我们可以使用 PySpark 中的 Spark ML 来训练和评估我们的机器学习模型。 在使用 PySpark 进行模型训练之前,我们首先需要准