-
Python爬虫实战系列:如何爬取某乎热搜榜单
本篇文章将带你通过Python爬虫实战,学习如何爬取某乎平台的热搜榜单。
-
快速上手Python爬虫:网络爬虫基础介绍及示例代码
网络爬虫,又称为 Web 爬虫、网络蜘蛛、网络机器人,在英文中被称为 web crawler,是一种自动化程序,能够在互联网上自动获取数据、抓取信息,并将其存储在本地或远程数据库中。它可以帮助我们自动化处理大量数据,提高工作效率,更好地利用互联网资源。 现代互联网上
-

Python爬虫案例解析:五个实用案例及代码示例(学习爬虫看这一篇文章就够了)
导言: Python爬虫是一种强大的工具,可以帮助我们从网页中抓取数据,并进行各种处理和分析。在本篇博客中,我们将介绍五个实用的Python爬虫案例,并提供相应的代码示例和解析。通过这些案例,读者可以了解如何应用Python爬虫来解决不同的数据获取和处理问题,从而进一
-

python爬虫实战代码(一)
目录 一、程序效果 二、程序代码 三、答疑解惑 四、同步视频讲解 python爬虫爬取豆瓣电影top250数据并存入excel表格 爬虫的效果如下 完整程序代码如下,复制粘贴可直接运行出结果! 有任何问题的小伙伴可以添加我的微信:safeseaa 推荐大家两个相关的视频讲解,有需要的可以
-
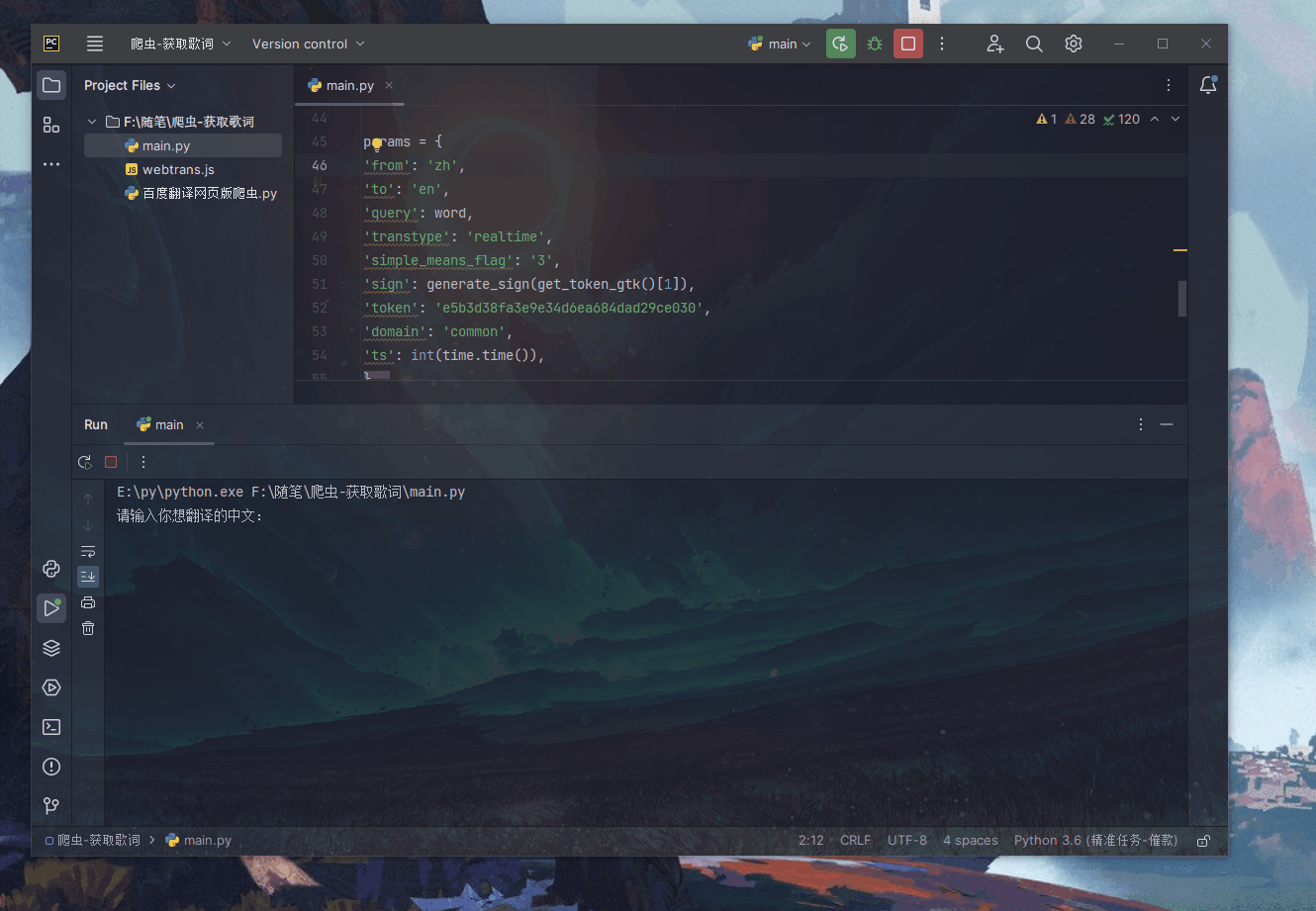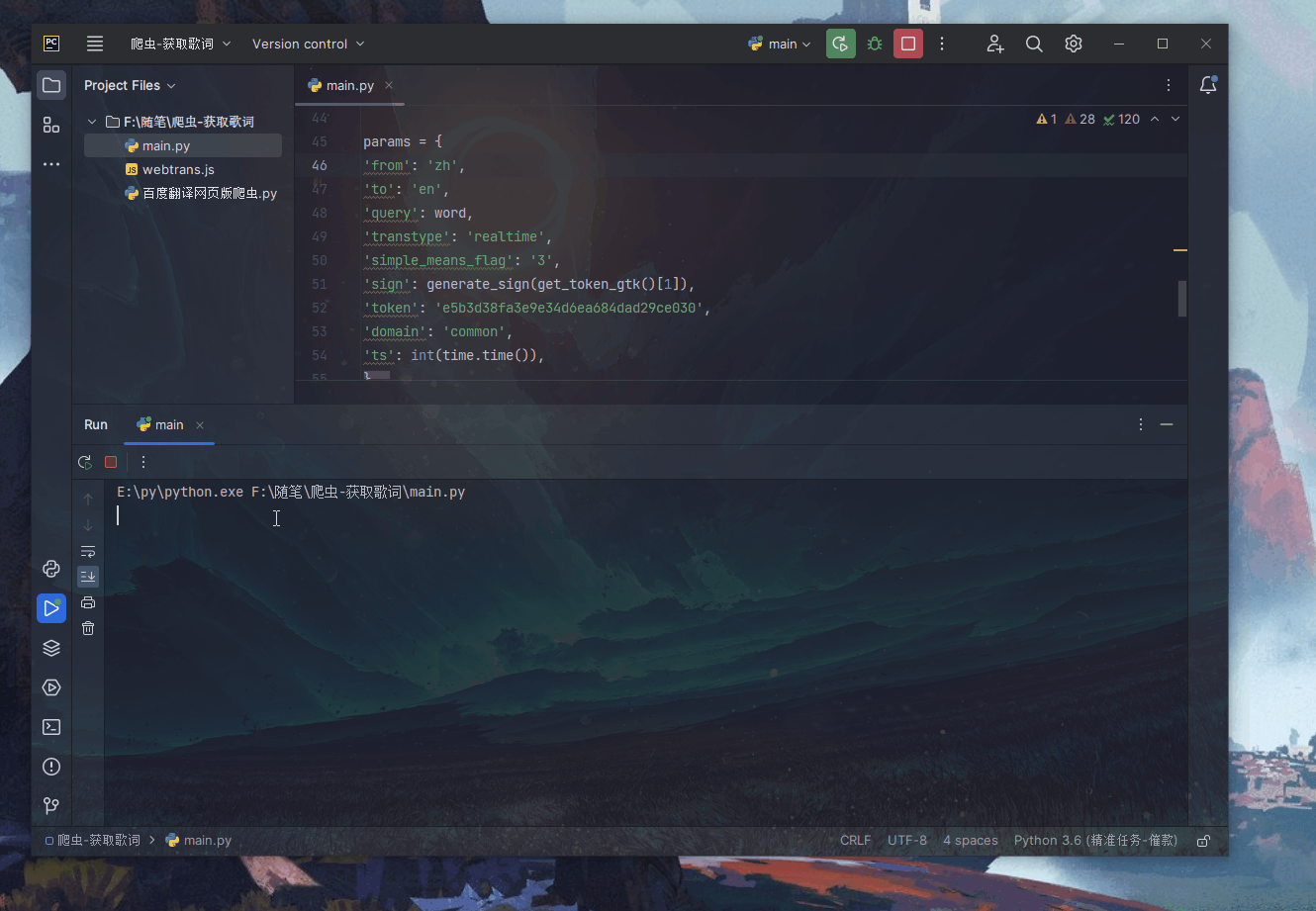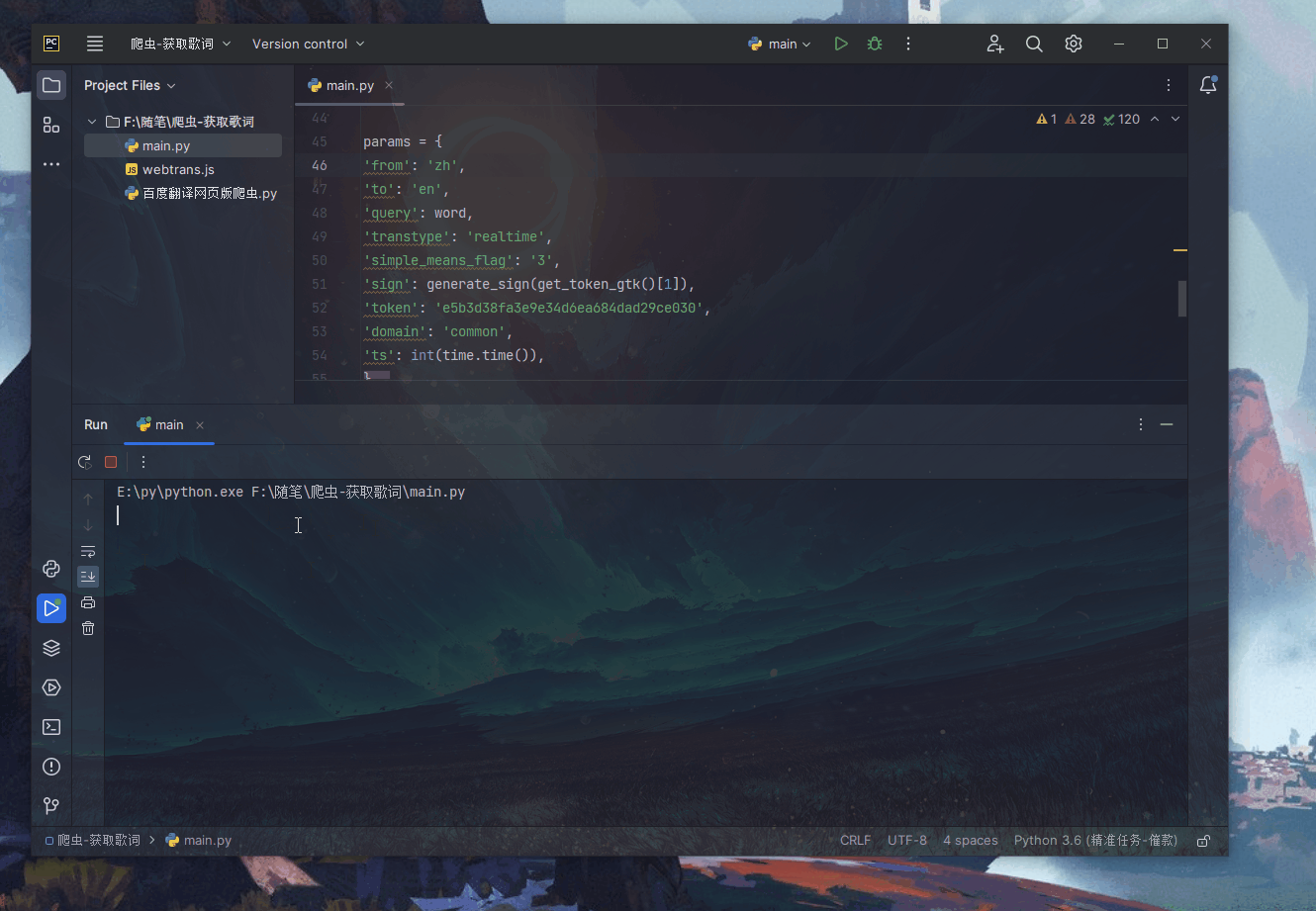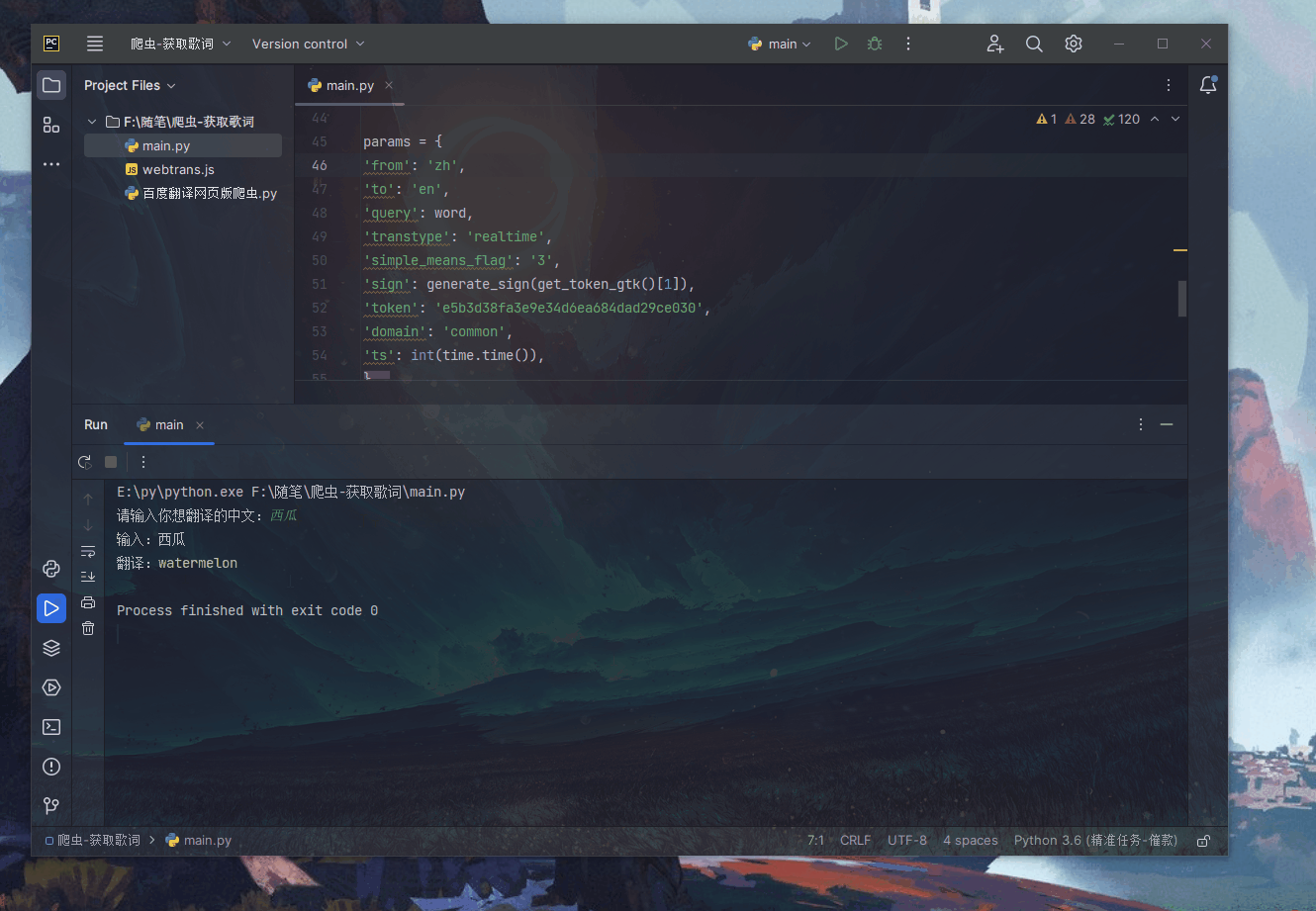
Python爬虫实战(高级篇)—3百度翻译网页版爬虫(附完整代码)
库 安装 js2py pip install js2py requests pip install requests 这里我们发现所需的参数: 1、sign(这是最重要的!!) 2、token 3、ts,时间戳 原帖查看
-
python实战应用讲解-【numpy数组篇】常用函数(八)(附python示例代码)
目录 Python Numpy MaskedArray.cumprod()函数 Python Numpy MaskedArray.cumsum()函数 Python Numpy MaskedArray.default_fill_value()函数 Python Numpy MaskedArray.flatten()函数 Python Numpy MaskedArray.masked_equal()函数 numpy.MaskedArray.cumprod() 返回在给定轴上被屏蔽的数组元素的累积乘积。在计算过程中,被屏蔽的值在内部
-
python实战应用讲解-【numpy数组篇】实用小技巧(五)(附python示例代码)
目录 查找两个NumPy数组的并集 查找NumPy数组中的唯一行 扁平化 一个NumPy数组的列表 使用NumPy在Python中扁平化一个矩阵 从元素上获取NumPy数组值的幂 为了找到两个一维数组的联合,我们可以使用Python Numpy库的函数numpy.union1d()。它返回唯一的、经过排序的数组,其值在两个输
-
python实战应用讲解-【numpy数组篇】实用小技巧(八)(附python示例代码)
目录 如何在NumPy数组上映射一个函数 方法一:numpy.vectorize()方法 方法2:使用lambda函数 方法3:用一个数组作为函数的参数来映射一个NumPy数组 如何使用给定的索引位置重新排列二维NumPy数组的列 如何用NumPy删除只包含0的数组行 如何删除Numpy数组中包含非数字值的列
-
python实战应用讲解-【numpy科学计算】line_profiler模块(附python示例代码)
目录 Numpy 安装line_profiler 准备工作 具体步骤 Numpy 用line_profiler分析代码 具体步骤 攻略小结
-
【100天精通python】Day43:python网络爬虫开发_爬虫基础(urlib库、Beautiful Soup库、使用代理+实战代码)
目录 1 urlib 库 2 Beautiful Soup库 3 使用代理 3.1 代理种类 HTTP、HTTPS 和 SOCKS5
-
【100天精通python】Day44:python网络爬虫开发_爬虫基础(爬虫数据存储:基本文件存储,MySQL,NoSQL:MongDB,Redis 数据库存储+实战代码)
目录 1 数据存储 1.1 爬虫存储:基本文件存储 1.2 爬虫存储:使用MySQL 数据库 1.3 爬虫 NoSQL 数据库使用 1.3.1 MongoDB 简介
-

利用爬虫采集音频信息完整代码示例
以下是一个使用WWW::RobotRules和duoip.cn/get_proxy的Perl下载器程序: 这个程序首先获取一个爬虫IP服务器地址,然后使用WWW::RobotRules模块设置User-Agent和X-Forwarded-For头部。接下来,程序使用LWP::UserAgent和HTTP::Request对象向Walmart网站发送请求,并检查响应状态。如果请求成功,程序将下
-

Scala库用HTTP爬虫IP代码示例
根据提供的引用内容,sttp.client3和sttp.model库是用于HTTP请求和响应处理的Scala库,可以与各种Scala堆栈集成,提供同步和异步,过程和功能接口。这些库可以用于爬虫程序中,用于发送HTTP请求和处理响应。需要注意的是,使用这些库进行爬虫程序开发时,需要遵守相关法律法规
-

用爬虫代码爬取高音质音频示例
目录 一、准备工作 1、安装Python和相关库 2、确定目标网站和数据结构 二、编写爬虫代码 1、导入库 2、设置代理IP 3、发送HTTP请求并解析HTML页面 4、查找音频文件链接 5、提取音频文件名和下载链接 6、下载音频文件 三、完整代码示例 四、注意事项 1、遵守法律法规和网站规
-
python 爬虫入门示例
爬取接口示例,这里以 Get 请求为例,这里请求的接口会返回一个 JSON 字符串。 若接口返回的是 json 字符串,也可以像下面这样,直接使用 result.json() 接收接口返回的数据为字典。 上面的示例是发送一个请求,该请求返回的一个json字符串。有时候我们是想获取某个网址链接