
如何使用Python抓取网页的结果并保存到 Excel 文件?
本文将介绍如何通过Python中的Selenium和BeautifulSoup库在循环中获取网页数据,并将结果保存到Excel文件中。我们将提供一段简化的代码示例,强调使用Pandas数据框架以便于数据处理和保存。
python简单网页爬虫
正则匹配:难度较大,不建议 BeautifulSoup或者xpath:文档结构清晰【推荐】 实际使用常常是:BeautifulSoup或者xpath匹配到对应的dom节点,然后正则提取想要的数据 (1)BeautifulSoup : 安装: pip install lxml pip install bs4 使用: 爬取国家重点保护野生植物的信息,网站:中国珍稀濒危
Python爬虫抓取网页
本节讲解第一个 Python 爬虫实战案例:抓取您想要的网页,并将其保存至本地计算机。 首先我们对要编写的爬虫程序进行简单地分析,该程序可分为以下三个部分: 拼接 url 地址 发送请求 将照片保存至本地 明确逻辑后,我们就可以正式编写爬虫程序了。 本节内容使用 urll
Python网页爬虫代码
网页爬虫是一种自动化程序,可以自动地访问网页并提取其中的信息。它可以用于各种目的,例如搜索引擎的索引、数据挖掘、价格比较、舆情监测等。网页爬虫通常使用编程语言编写,例如Python、Java等。 以下是一个简单的示例,使用 Python 和 requests 库进行网页爬取: 在这
python爬虫 爬取网页图片
目录 一:爬虫基础 二:安装html解析的python工具 三:爬取网页图片 爬虫基本过程: 1.请求标头 headers 2.创建一个会话 requests.Session 3.确定请求的路径 4.根据路径获取网页资源(HTML文件) 5.解析html文件BeautifulSoup div a 标签 获取对应的图片 6.建立网络连接进行下载 创建出下载的图

Python爬虫学习笔记(一)————网页基础
目录 1.网页的组成 2.HTML (1)标签 (2)比较重要且常用的标签: ①列表标签 ②超链接标签 (a标签) ③img标签:用于渲染,图片资源的标签 ④div标签和span标签 (3)属性 (4)常用的语义化标签 (5)元素的分类及特点 ①块元素 ②行内元素 ③行内块元素 (6)文件路径 (

Python网页爬虫爬取起点小说——re解析网页数据
!!注意:我们获取到的网页响应数据,可能会与网页源代码中呈现的格式不同。因为有些网页文件是用JavaScript加载的,浏览器会自动将其解析成html文档格式,而我们获取到的内容是JavaScript格式的文档。所以获取到响应数据之后先要查看内容是否与网页源码中的一致,不一
【Python】【进阶篇】五、Python爬虫的抓取网页
Python 爬虫应用案例:爬取目标的网页,并将其保存到本地。 对要编写的爬虫程序进行分析,可以简单分为为以下三个部分: 目标 url 地址 发送请求 将响应数据保存至本地 明确逻辑后,我们就可以正式编写爬虫程序了。 在这里我们使用标准库 urllib 库来编写爬虫,导入所需
如何使用 Python 爬虫抓取动态网页数据
随着 Web 技术的不断发展,越来越多的网站采用了动态网页技术,这使得传统的静态网页爬虫变得无能为力。本文将介绍如何使用 Python 爬虫抓取动态网页数据,包括分析动态网页、模拟用户行为、使用 Selenium 等技术。 在进行动态网页爬取之前,我们需要先了解动态网页和静
Python 网页爬虫的原理是怎样的?
网页爬虫是一种自动化工具,用于从互联网上获取和提取信息。它们被广泛用于搜索引擎、数据挖掘、市场研究等领域。 网页爬虫的工作原理可以分为以下几个步骤: URL调度、页面下载、页面解析和数据提取。 URL调度: 网页爬虫首先需要一个初始的URL作为起点,然后根据
Python 爬虫网页图片下载到本地
您可以使用Python的requests库来获取网页的源码,使用BeautifulSoup库来解析HTML,并使用urllib库来下载图片到本地。下面是一个示例代码: 请注意,上述代码中的URL和文件名是示例,您需要根据实际情况进行替换。另外,这段代码只能下载图片类型为JPEG的文件,如果想要下载其他
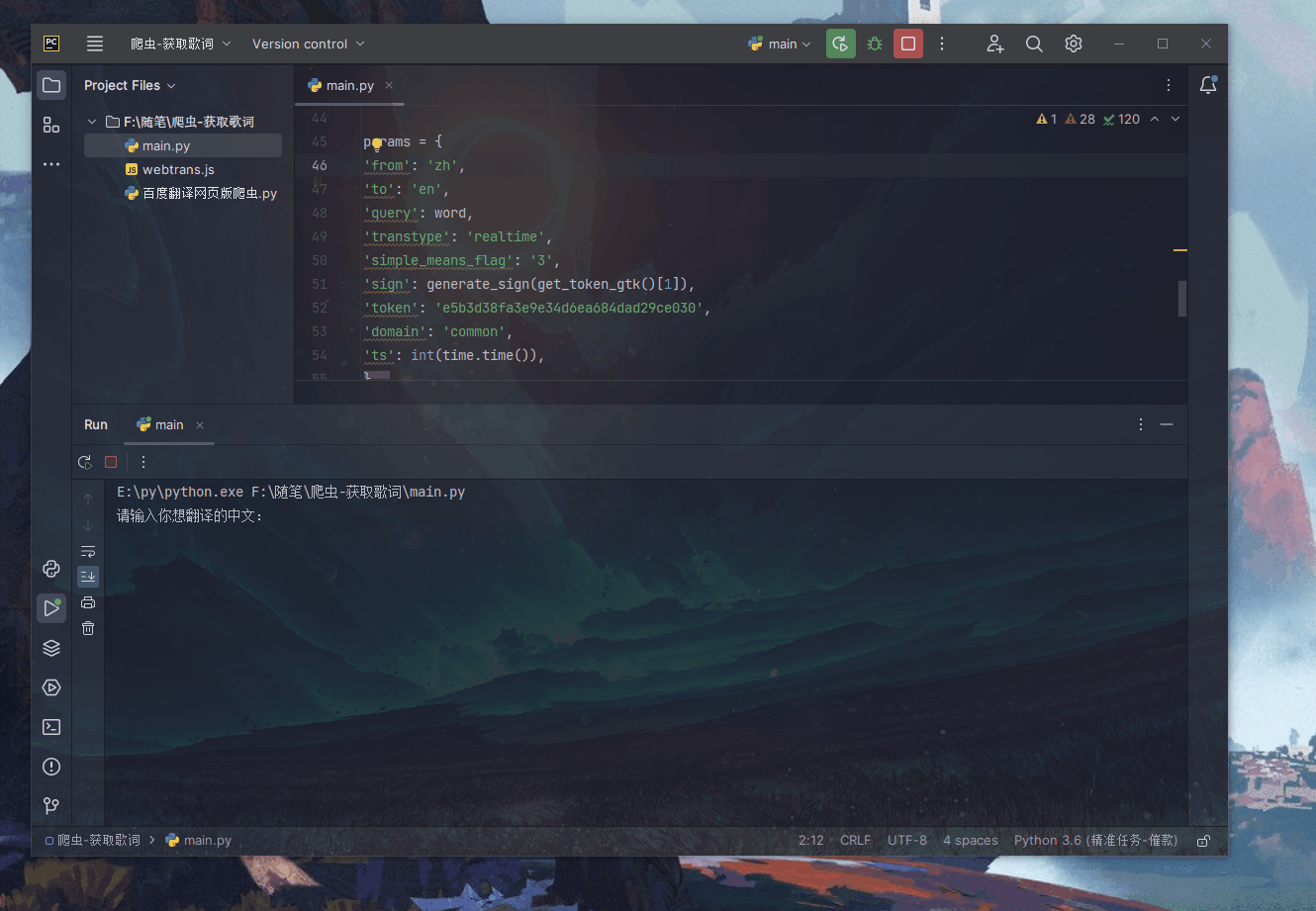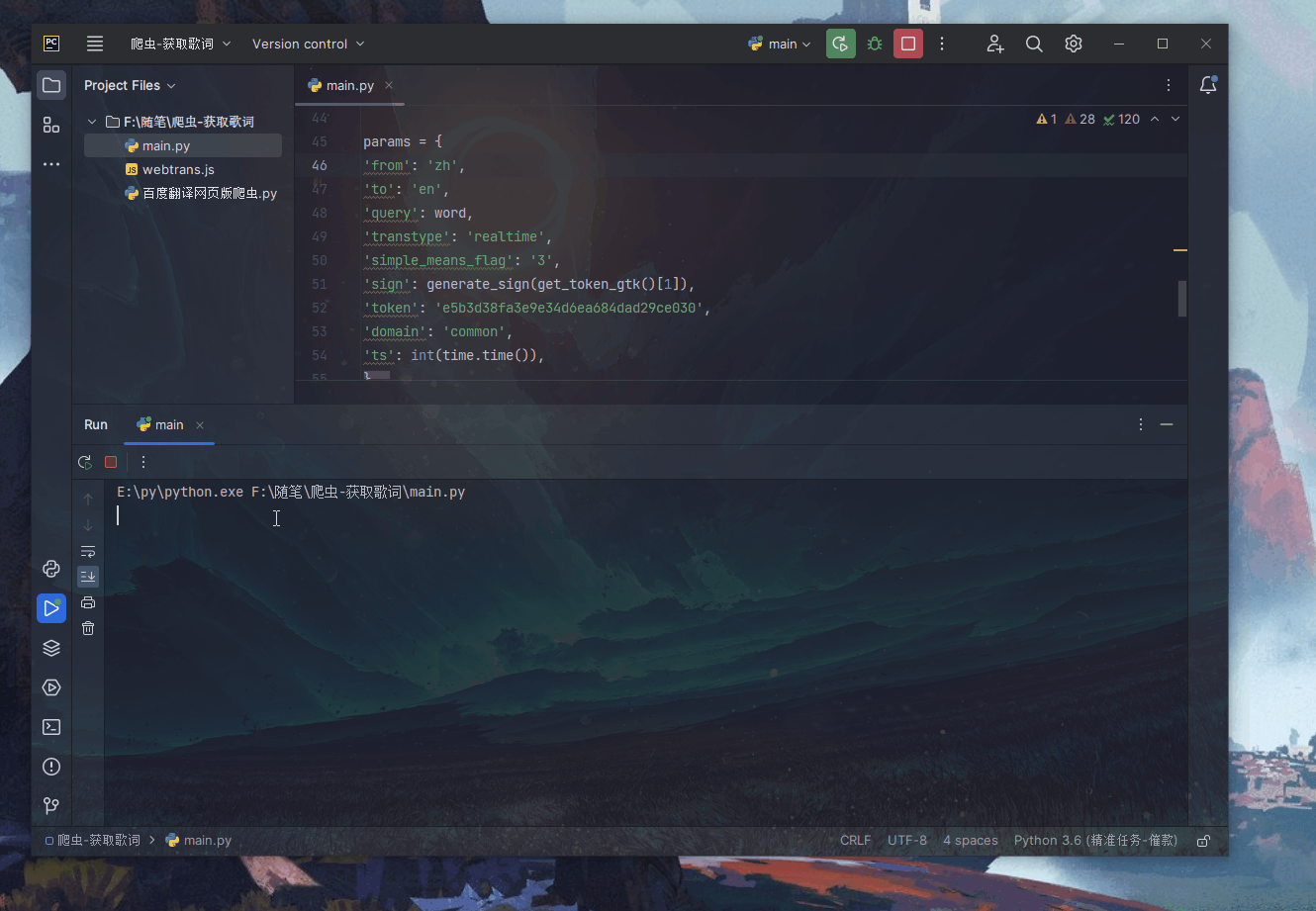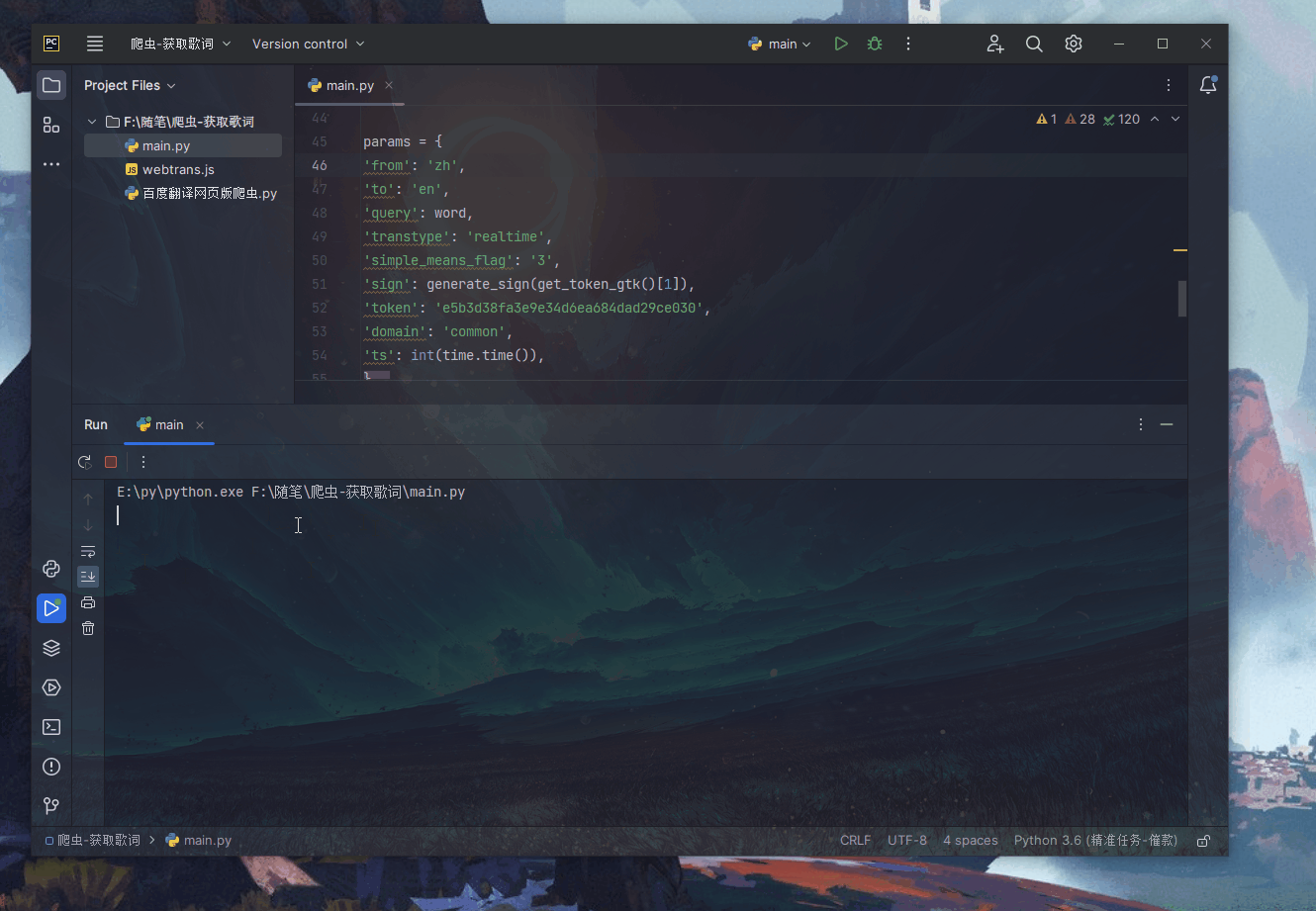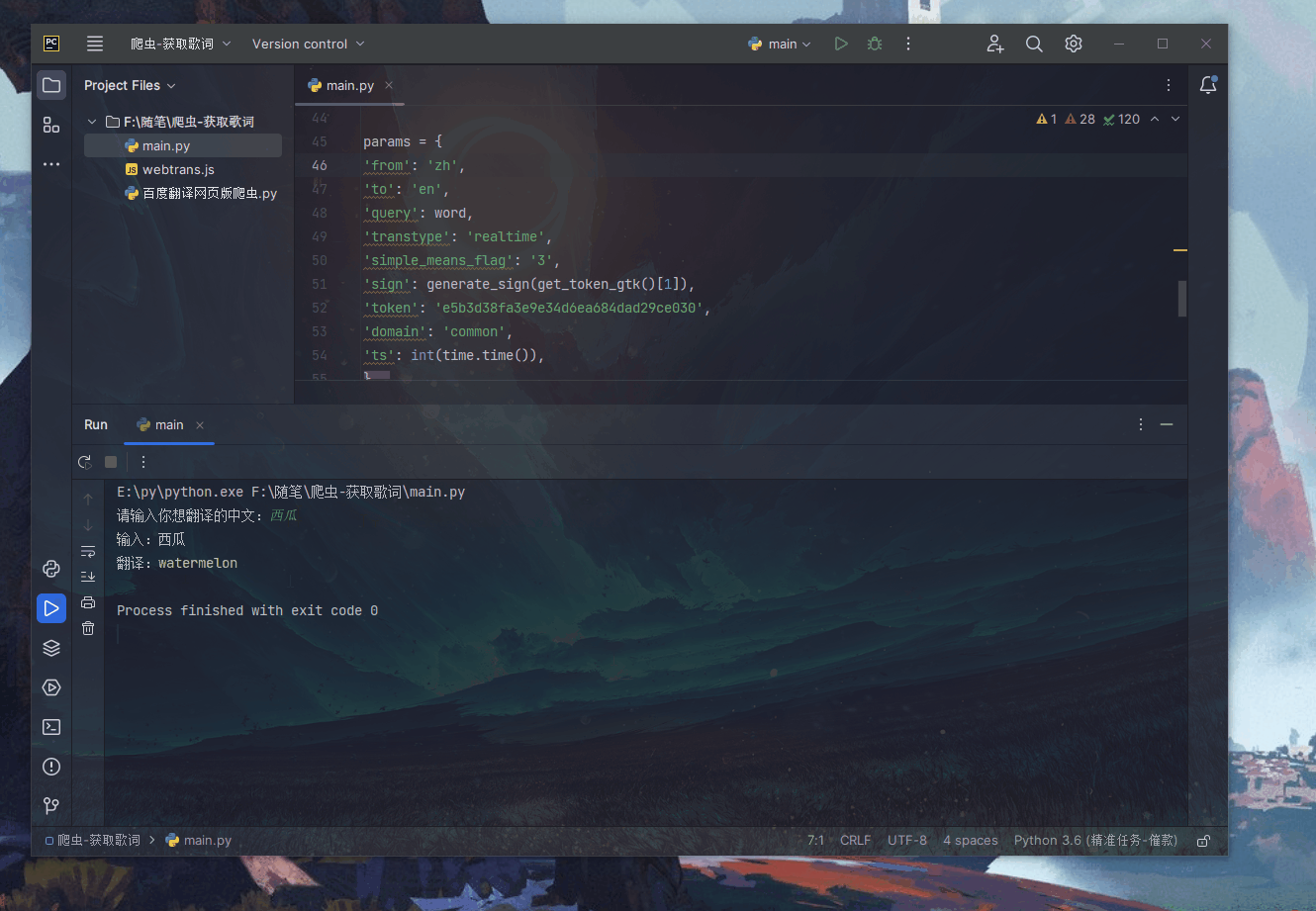
Python爬虫实战(高级篇)—3百度翻译网页版爬虫(附完整代码)
库 安装 js2py pip install js2py requests pip install requests 这里我们发现所需的参数: 1、sign(这是最重要的!!) 2、token 3、ts,时间戳 原帖查看

Python爬虫教程:解析网页中的元素
嗨喽~大家好呀,这里是魔王呐 ❤ ~! python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取 在我们理解了网页中标签是如何嵌套,以及网页的构成之后, 我们就是可以开始学习使用python中的第三方库BeautifulSoup筛选出一个网页中我们想要得到的数据。 接下来我们了
python爬虫之selenium嵌套网页示例讲解
Selenium是一款非常流行的Web自动化测试框架,它可以模拟用户在浏览器上执行的各类操作,如:点击链接,填写表单,滚动页面等。这使得Selenium成为了一个非常强大的爬虫工具。在爬取网页时,Selenium可以通过模拟用户的操作来解决一些常见的爬虫难题,如JavaScript渲染或需要

Python 网页爬虫原理及代理 IP 使用
目录 前言 一、Python 网页爬虫原理 二、Python 网页爬虫案例 步骤1:分析网页 步骤2:提取数据 步骤3:存储数据 三、使用代理 IP 四、总结 前言 随着互联网的发展,网络上的信息量变得越来越庞大。对于数据分析人员和研究人员来说,获取这些数据是一项重要的任务。Python