-
SadTalker:让stable diffusion人物说话的创新工具
SadTalker是一个GitHub项目,能够根据图片和音频合成面部说话的视频。现已支持stable diffusion webui,可以结合音频合成面部说话的视频。本文详细介绍了安装过程和使用教程。
-

SadTalker项目上手教程
最近发现一个很有趣的GitHub项目SadTalker,它能够将一张图片跟一段音频合成一段视频,看起来毫无违和感,如果不仔细看,甚至很难辨别真假,预计未来某一天,一大波网红即将失业。 虽然这个项目目前的主要研究方向还是基于cuda的脸部训练,生成动态的视频,但如果能够
-
让图片说话SadTalker
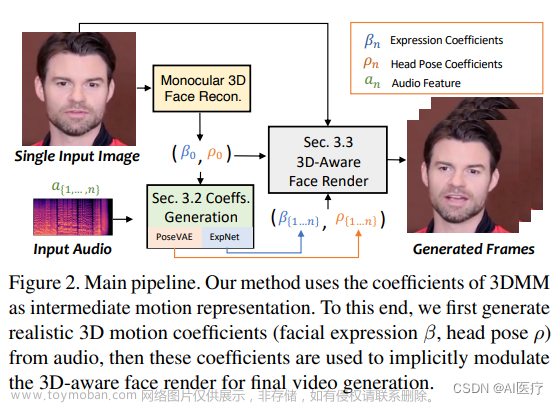
SadTalker:使用一张图片和一段语音来生成口型和头、面部视频. 西安交通大学开源了人工智能SadTalker模型,通过从音频中学习生成3D运动系数,使用全新的3D面部渲染器来生成头部运动,可以实现图片+音频就能生成高质量的视频。 论文地址:Learning Realistic 3D Motion Coefficients 整
-

AI数字人SadTalker实战
AI数字人在营销和品牌推广中扮演着至关重要的角色,许多企业和个人正积极利用数字技术来打造属于自己的财富。有没有一种简单而免费的方式来创建自己的数字人呢?本篇博客笔者将为大家介绍如何搭建属于自己的AI数字人。 生成头部说话视频通过人脸图像和语音音频仍
-
最新嘴型融合模型SadTalker
windows 10 64bit SadTalker torch 1.12.1+cu113 创建一个全新的 python 虚拟环境 然后,拉取源代码,并且安装对应的依赖 找一段音频 test.mp3 和视频 test.mp4 ,进行测试 其中, --source_image 参数可以是视频,也可以是图片, --result_dir 参数指定最后合成后的视频存放位置, --enhancer 指定视频
-

SadTalker(CVPR2023)-音频驱动视频生成
论文: 《SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation》 github: https://github.com/Winfredy/SadTalker 演示效果: https://www.bilibili.com/video/BV1fX4y1675W 利用一张面部图片及一段音频让其变为一段讲话的视频仍然存在许多挑战: 头部运动不自然、
-
AI数字人:sadtalker让照片开口说话
西安交通大学也开源了人工智能SadTalker模型,通过从音频中学习生成3D运动系数,使用全新的3D面部渲染器来生成头部运动,可以实现图片+音频就能生成高质量的视频。 论文地址:Learning Realistic 3D Motion Coefficients 通过人脸图像和一段语音音频
-

如何本地部署虚拟数字克隆人 SadTalker
Win10 SadTalker 如何本地部署虚拟数字克隆人 SadTalker SadTalker:学习逼真的3D运动系数,用于风格化的音频驱动的单图像说话人脸动画 单张人像图像🙎 ♂️+音频🎤=会说话的头像视频🎞 一、底层安装 安装 Anaconda、python 和 git 1.下载安装Anaconda conda是一个开源的软件包管理系统和
-

Stable Diffusion WebUI安装SadTalker插件
AI绘画已经火了有几个月了,不知道大家有没有去体验一下呢? 要说可操作性最强的莫过于Stable Diffusion WebUI,简称SD,下面我们就来介绍一下如何给SD安装上SadTalker插件,记录一下安装和使用过程中踩过的坑~ 通过Stable Diffusion WebUI安装SadTalker插件,有4种方式: 1. web界面通过在
-
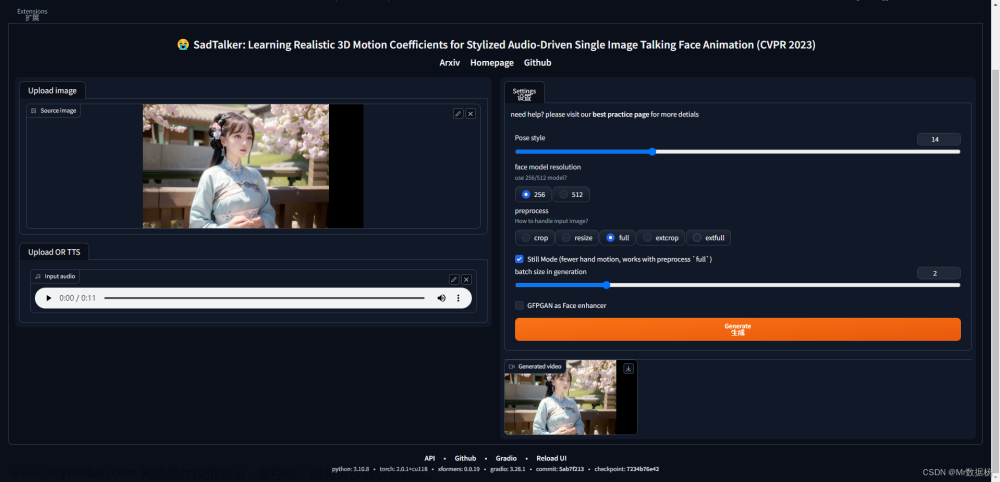
Stable Diffusion 使用 SadTalker 生成图片数字人
Heygen和D-ID等照片转视频的工具,都需要在线付费使用。本次介绍一个SadTalker数字人。SadTalker有多种使用方式,包括完整安装程序和stable diffusion插件模式。安装程序操作较繁琐,因此推荐stable diffusion插件模式。 打开SD进入扩展复制链接 https://github.com/OpenTalker/SadTalker.git 到安装
-

SadTalker:让stable diffusion人物说话的创新工具
SadTalker是一个GitHub项目,能够根据图片和音频合成面部说话的视频。现已支持stable diffusion webui,可以结合音频合成面部说话的视频。本文详细介绍了安装过程和使用教程。
-
GitHub上的SadTalker-Video-Lip-Sync
本项目基于SadTalkers实现视频唇形合成的Wav2lip。视频+语言(MP4+WAV)视频 首先使用Anaconda创建一个虚拟环境SadTalker,然后打开cmd使用命令 conda activate SadTalker 切换环境,在D盘新建一个文件夹SadTalker-Video-Lip-Sync,cmd切换到该文件夹,使用命令 git clone https://github.com/Zz-ww/SadTalker-V
-
打造AI虚拟数字人,Stable Diffusion+Sadtalker教程
站长笔记 2 个月前 1 1k Stable Diffusion是一个能够根据 文本描述生成高质量图片的深度学习模型 ,它使用了一种叫做 潜在扩散模型的生成网络架构 ,可以在普通的GPU上运行。Sadtalker是一个能够根 据图片和音频生成 视频的开源项目 ,它使用了一种叫做 SadNet的神经网络 ,可以
-
如何在windows上本地部署SadTalker,实现AI数字人
设备配置:CPU E3-1240v3, RAM 32G, SSD 1T, GPU0 Nvidia 1080ti,GPU1 Nvidia T4 OS:Windows10专业版 【python安装】 1、下载安装python 3.10.9 https://www.python.org/ftp/python/3.10.9/python-3.10.9-amd64.exe 2、下载安装git https://git-scm.com/downloads 3、下载解压ffmpeg 打开:https://github.com/GyanD/codexffmpeg/releases 下载:
-
基于SadTalker的AI主播,Stable Diffusion也可用
基于之前的AI主播的的学习基础 基于Wav2Lip的AI主播 和 基于Wav2Lip+GFPGAN的高清版AI主播,这次尝试一下VideoRetalking生成效果。 总体来说,面部处理效果要好于Wav2Lip,而且速度相对于Wav2Lip+GFPGAN也提升很多,也支持自由旋转角度,但是如果不修改源码的情况下,视频的部分截取稍