-
TF-VAEGAN:添加潜在嵌入(Latent Embedding)的VAEGAN处理零样本学习
TF-VAEGAN是在VAEGAN架构基础上引入潜在嵌入解码器,并通过反馈模块和判别特征转换来增强特征合成与零样本分类能力的模型。该模型利用语义嵌入重建实现循环一致约束,生成判别性特征,减少类间歧义,从而改善零样本学习的效果。
-

TF-VAEGAN:添加潜在嵌入(Latent Embedding)的VAEGAN处理零样本学习
TF-VAEGAN是在VAEGAN架构基础上引入潜在嵌入解码器,并通过反馈模块和判别特征转换来增强特征合成与零样本分类能力的模型。该模型利用语义嵌入重建实现循环一致约束,生成判别性特征,减少类间歧义,从而改善零样本学习的效果。
-

Bi-VAEGAN:对TF-VAEGAN提出的视觉到语义进一步改进
论文“Bi-directional Distribution Alignment for Transductive Zero-Shot Learning”提出Bi-VAEGAN,它以f-VAEGAN-D2为Baseline,进一步发展了TF-VAEGAN通过利用所见数据和反馈模块增强生成的视觉特征思路。f-VAEGAN-D2的介绍、TF-VAEGAN的介绍 取决于标签是否可用,可以分为无条件分布 (p(v)) 或条件分布
-

传统IO与零拷贝
传统的 I/O 数据传输是指在计算机系统中,使用输入/输出(I/O)操作进行数据传输的一种方式。这种方式通常涉及将数据从内存传输到外部设备(如磁盘、网络等)或从外部设备传输到内存。传统的 I/O 数据传输通常采用阻塞式的方式,即在进行数据传输时会阻塞当前的线程
-
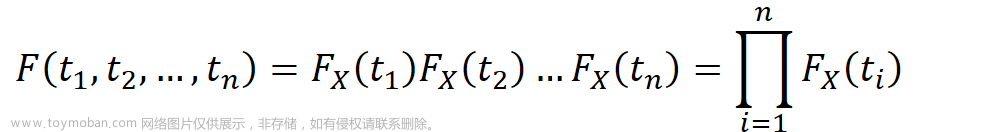
《概率论与数理统计》学习笔记6-样本及样本函数的分布
目录 总体 简单随机样本 直方图 样本分布函数 样本函数及其概率分布 𝜒2分布 𝑡分布 𝐹分布 总体: 研究对象的全体 个体: 总体中的每一个元素 总体容量: 总体
-
APT攻击与零日漏洞
当谈到网络安全时,APT( 高级持续性威胁 )攻击是最为复杂和难以检测的攻击类型之一。APT攻击通常涉及到高度的技术和策略性,而且它们的目标是深入地渗透和长时间地隐藏在目标网络中。 高级持续性威胁 (APT)是一种网络攻击,其中攻击者为了长期目的而非短期益处进
-

小样本学习系列工作(持续更新)
有关小样本学习的各类文章通常会将其方法分成几个大类:基于度量学习的小样本方法、基于数据增强的小样本学习方法和基于模型初始化的小样本学习方法。我觉得这样分类并不好,因为三种方法之间并不是各自独立存在的,大多数情况下都是有交集的,比如一篇工作可能
-

【机器学习】处理样本不平衡的问题
机器学习中,样本不均衡问题经常遇到,比如在金融风险人员二分类问题中,绝大部分的样本均为正常人群,可用的风险样本较少。如果拿全量样本去训练一个严重高准确率的二分类模型,那结果毫无疑问会严重偏向于正常人群,从而导致模型的失效,所以说,训练样本比例
-
如何解决机器学习中样本不平衡问题
样本不平衡问题在机器学习中是一个常见的挑战,下面是一些样本不平衡问题的例子: 欺诈检测:在银行或电商领域的欺诈检测中,正常交易的数量通常远远多于欺诈交易的数量。这导致了一个类别(欺诈交易)的样本数量较少,而另一个类别(正常交易)的样本数量较多。
-
SPSS学习(四)单样本t检验
参考书籍:《SPSS其实很简单》 定义:在假设检验中,通常要陈述两个假设,原假设和对立假设。原假设通常陈述处理没有效果,而对立假设陈述处理有效果。 单边检验(one-tailed test):目的仅仅是调查单一方向。单边检验需要事先确定单一的方向进行调查,能够更大机会发
-

【学习笔记】元学习如何解决计算机视觉少样本学习的问题?
目录 1 计算机视觉少样本学习 2 元学习 3 寻找最优初始参数值方法:MAML 3.1 算法步骤 3.2 代码:使用MAML 和 FO-MAML、任务增强完成Few-shot Classification 4 距离度量方法:Siamese Network,ProtoNet,RN 4.1 孪生网络(Siamese Network) 算法步骤 Siamese Network代码 4.2 原型网络(Prototypical Networks) 算
-

机器学习样本数据划分的典型Python方法
Date Author Version Note 2023.08.16 Dog Tao V1.0 完成文档撰写。 In machine learning and deep learning, the data used to develop a model can be divided into three distinct sets: training data, validation data, and test data. Understanding the differences among them and their distinct roles is crucial for effective model development and evaluation. Trai
-

Instruction Tuning:无/少样本学习新范式
作者 | 太子长琴 整理 | NewBeeNLP 大家好,这里是NewBeeNLP。 今天分享一种简单的方法来提升语言模型的 Zero-Shot 能力—— 指示(或指令)微调(instruction tuning) ,在一组通过指示描述的数据集上对语言模型微调,大大提高了在未见过任务上的 Zero-Shot 能力。 模型 137B,在超
-

【区块链】以太坊L2扩容方案与零知识证明
简要概述以太坊L2层现有解决方案 简要概述以太坊L2未来扩容的方向 简要概述零知识证明的基本概念和零知识证明在以太坊的运用 简要概述stark ware的两个产品,但并不推荐现有使用和研究 简要概述polygon zkEVM,推荐使用和研究 zk-SNARK 和 zk-STARK,是零知识证明底层技术。二者
-

统计学学习笔记:L1-总体、样本、均值、方差
目录 一、总体和样本 二、集中趋势分析 2.1 均值 2.1.1 样本均值 2.1.2 总体均值 2.2 众数,中位数 三、离散趋势分析 3.1 总体方差 3.2 样本方差 3.3 标准差 比如要计算全国男性的平均身高,但是全部调查是不现实的,所有要采取抽样调查,随机抽取一部分男性的身高,全国男性身