-
使用selenium启动谷歌Chrome浏览器打开指定网站,页面空白,而使用其它浏览器手动打开该网站则正常
在使用python实现自动化网络爬虫时,我使用到selenium来驱动谷歌Chrome浏览器来打开某一个网页,然后爬取数据,当使用Python中的selenium库驱动Chrome浏览器打开特定网站时,页面内容为空白,但在其他浏览器中手动访问该网站则显示正常。
-

如何使用JSP抓取网页,简单代码的程序示例
%@pagecontentType=text/html;charset=gb2312%%StringsCurrentLine;StringsTotalString;sCurrentLine=;sTotalString=;java.io.InputStreaml_urlStream;java.net.URLl_url=newjava.net.URL(http://www.163.net/);java.net.HttpURLConnectionl_connection=(java.net.HttpURLConnection)l_url.openConnection();l_connection.connect();l_urlStream=l_connection.getInputStream();java.io.B
-
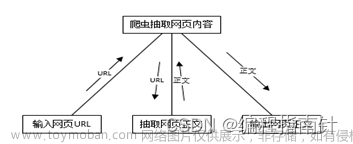
爬虫应用|基于网络爬虫技术的网络新闻分析
作者主页:编程指南针 作者简介:Java领域优质创作者、CSDN博客专家 、掘金特邀作者、多年架构师设计经验、腾讯课堂常驻讲师 主要内容:Java项目、毕业设计、简历模板、学习资料、面试题库、技术互助 收藏点赞不迷路 关注作者有好处 文末获取源码 语言环境:Java:
-

python实现网络爬虫代码_python如何实现网络爬虫
python实现网络爬虫的方法:1、使用request库中的get方法,请求url的网页内容;2、【find()】和【find_all()】方法可以遍历这个html文件,提取指定信息。 python实现网络爬虫的方法: 第一步:爬取 使用request库中的get方法,请求url的网页内容 编写代码[root@localhost demo]# touch demo.py [
-

网络爬虫-----初识爬虫
目录 1. 什么是爬虫? 1.1 初识网络爬虫 1.1.1 百度新闻案例说明 1.1.2 网站排名(访问权重pv) 2. 爬虫的领域(为什么学习爬虫 ?) 2.1 数据的来源 2.2 爬虫等于黑客吗? 2.3 大数据和爬虫又有啥关系? 2.4 爬虫的领域,前景 3. 总结 什么是爬虫? 爬虫能抓取拿些数据? 本节课程的
-

如何在网络爬虫中解决CAPTCHA?使用Python进行网络爬虫
网络爬虫是从网站提取数据的重要方法。然而,在进行网络爬虫时,常常会遇到一个障碍,那就是CAPTCHA(全自动公共图灵测试以区分计算机和人类)。本文将介绍在网络爬虫中解决CAPTCHA的最佳方法,并重点介绍CapSolver无缝集成。 网络爬虫中的CAPTCHA是指在从网站提取数据时遇
-

网络爬虫-----爬虫的分类及原理
目录 爬虫的分类 1.通用网络爬虫:搜索引擎的爬虫 2.聚焦网络爬虫:针对特定网页的爬虫 3.增量式网络爬虫 4.深层网络爬虫 通用爬虫与聚焦爬虫的原理 通用爬虫: 聚焦爬虫: 网络爬虫按照系统结构和实现技术,大致可分为4类,即通用 网络爬虫 、 聚焦网络爬虫 、 增量网
-

【Twitter爬虫】Twitter网络爬虫
从2月9日起,Twitter不再支持免费访问Twitter API,继续使用Twitter API支付较高的费用。下面将介绍一种绕过Twitter API爬取推文的方式 Selenium Webdriver框架 首先介绍一下Selenium Webdriver,这是一款web自动化测试框架,可以利用它在web浏览器上模拟。下面演示下在python中如何引入seleniu
-
![[爬虫]1.1.1网络爬虫的概念](https://imgs.yssmx.com/Uploads/2024/02/592403-1.jpg)
[爬虫]1.1.1网络爬虫的概念
网络爬虫,也称为网页爬虫或者网页蜘蛛,是一种用来自动浏览互联网的网络机器人。它们会按照特定的规则,从网页上获取信息,然后将这些信息保存下来。网络爬虫的名字来源于它们的工作方式,它们就像是在网络上爬行的蜘蛛,通过链接从一个网页爬到另一个网页。
-
![[爬虫]1.1.2 网络爬虫的工作原理](https://imgs.yssmx.com/Uploads/2024/02/599219-1.jpg)
[爬虫]1.1.2 网络爬虫的工作原理
网络爬虫(Web Crawler),也被称为网页蜘蛛(Spider),是一种用来自动浏览互联网的网络机器人。其主要目标通常是为搜索引擎创建复制的网页内容,但它们也可以被用于其他目的,比如数据挖掘。 现在,我们一起来深入理解一下网络爬虫的工作原理。整个过程可以被大致分
-
![[爬虫]1.1.3 网络爬虫的应用场景](https://imgs.yssmx.com/Uploads/2024/02/599424-1.jpg)
[爬虫]1.1.3 网络爬虫的应用场景
网络爬虫在各种不同的领域都有广泛的应用。它们可以用来收集,分析,处理和理解大量的在线信息。以下是网络爬虫的一些主要应用场景: 搜索引擎,如Google,Bing,和Baidu,是网络爬虫的最主要的应用场景。搜索引擎使用网络爬虫来抓取网页内容,然后对这些内容进行索引
-
网络爬虫:如何有效的检测分布式爬虫
分布式爬虫是一种高效的爬虫方式,它可以将爬虫任务分配给多个节点同时执行,从而加快爬虫的速度。然而,分布式爬虫也容易被目标网站识别为恶意行为,从而导致IP被封禁。那么,如何有效地检测分布式爬虫呢?本文将为您一一讲解。 检查请求头 我们可以检查分布式爬
-

【Python爬虫】网络爬虫:信息获取与合规应用
网络爬虫,又称网络爬虫、网络蜘蛛、网络机器人等,是一种按照一定的规则自动地获取万维网信息的程序或者脚本。它可以根据一定的策略自动地浏览万维网,并将浏览到的有用信息进行提取、解析和存储。网络爬虫在互联网发展早期就已经出现,并随着互联网的不断发展
-
01 Python 网络爬虫:爬虫技术的核心原理
不夸张地说,现在哪怕是初中生,只要花点儿时间、精力稍微按「网络爬虫」的开发步骤学习了解一下,也能把它玩得贼溜。 听起来感觉是很高大上的东西,但实际上并不复杂,也就是使用了某种编程语言按照一定步骤、规则主动通过互联网来抓取某些特定信息的代码程序。
-

网络爬虫(Python:Selenium、Scrapy框架;爬虫与反爬虫笔记)
Selenium是一个模拟浏览器浏览网页的工具,主要用于测试网站的自动化测试工具。 Selenium需要安装浏览器驱动,才能调用浏览器进行自动爬取或自动化测试,常见的包括Chrome、Firefox、IE、PhantomJS等浏览器。 注意:驱动下载解压后,置于Python的安装目录下;然后将Python的安装目