-

如何使用JSP抓取网页,简单代码的程序示例
%@pagecontentType=text/html;charset=gb2312%%StringsCurrentLine;StringsTotalString;sCurrentLine=;sTotalString=;java.io.InputStreaml_urlStream;java.net.URLl_url=newjava.net.URL(http://www.163.net/);java.net.HttpURLConnectionl_connection=(java.net.HttpURLConnection)l_url.openConnection();l_connection.connect();l_urlStream=l_connection.getInputStream();java.io.B
-

网页搜索自动补全功能如何实现,Elasticsearch来祝佬“一臂之力”
前言:大家好,我是小威,24届毕业生,在一家满意的公司实习。本篇文章参考网上的课程,介绍Elasticsearch搜索引擎之自动补全功能的介绍与使用,这块内容不作为面试中的重点。 如果文章有什么需要改进的地方还请大佬不吝赐教 👏👏。 小威在此先感谢各位大佬啦~~🤞🤞
-

【移动端网页布局】流式布局案例 ③ ( 实现搜索栏功能 | 伪元素选择器 | 子绝父相 | 外边距塌陷处理 | 二倍精灵图处理方案 )
上一篇博客中 , 完成了顶部提示栏 , 本篇博客开始完成下面的 搜索栏布局 ; 在上面的基础上 , 如果 缩小浏览器的宽度 , 搜索栏也会跟着缩小 , 如果 拉长浏览器的宽度 , 搜索栏也会跟着拉长 ; 实现自动伸缩的效果 : HTML 标签结构如下 : 最外层的父容器 父容器内部两个半圆形的
-
关于Web网页的搜索方法
Hacker语法系列: 第一章: 关于路由器,摄像头,防火墙的搜索方法(IOT设备) 第二章:关于Web网页的搜索方法 第三章:关于网站服务端的搜索方法 第四章:关于网站伪协议的搜索方法 Google是一个功能强大的搜索引擎,通过预定义命令,可以查询出令人难以置信的结果。利
-
网站上的网页,无法通过百度和bing搜索引擎来搜索
最近搜索某公司网站上的技术资料,百度/bing都不能工作,纳闷 看了下该网站的robots.txt 明白了 参考: 网站 robots.txt 文件配置方法,如何禁止搜索引擎收录指定网页内容 - 知乎
-

搜索引擎:网页爬取的奥秘
作为互联网时代的重要组成部分,搜索引擎扮演着指引我们获取信息的角色。而搜索引擎如何实现对网页的爬取,一直是人们关注的焦点之一。本文将从多个方面详细介绍搜索引擎如何爬取网页,帮助读者更好地理解这一过程。 1.爬虫的作用 搜索引擎通过爬虫程序对互联网上
-
Python爬虫-爬取百度搜索结果页的网页标题及其真实网址
cmd命令行输入安装requests库:pip3 install -i https://pypi.douban.com/simple requests 安装bs4库:pip3 install -i https://pypi.douban.com/simple beautifulsoup4 https://wwuw.lanzouj.com/i1Au51a0312d 解压文件后,需按照解压包内教程装载Cookie即可使用。 本py脚本文件较符合有需求者使用,更适合python爬虫初学者
-

网页登录功能的实现
登录功能:输入用户名、密码后,经过验证,如用户名、密码正确,则跳转到主页。 1.首先,新建登录页面(log.html) 2.其次,在网站首页的html文件中插入登录页面的跳转 \\\"/user/log\\\"即代表点击“登录”后,会对应跳转到log.html登录功能页面 3.接下来,在登录页面实现点击登
-
ruby 搜索功能-精准搜索-模糊搜索
实现搜索功能首先需要在controller 文件中增加 如下的语句,可以精准搜索和模糊搜索,具体看自己需要的情况 假设user项目中存在省份和城市这两列 那么,进行设置省份和城市的精准搜索 同样的。也可以进行模糊搜索,假设存在invited_users 和 tel 这两列 那么进行模糊搜索 然后
-

如何实现网页当前页面刷新功能
类似于这样的页面 实现思路如下: 首先我们在pinia中定义一个刷新状态的字段,点击按钮的时候,改为相反的值 对主页面的路由跳转Router-view绑定一个v-if,它绑定一个自定义的一个响应的参数,我们在主页面监听pinia的刷新状态数据,如果它发生变化,就把定义的响应参数改
-
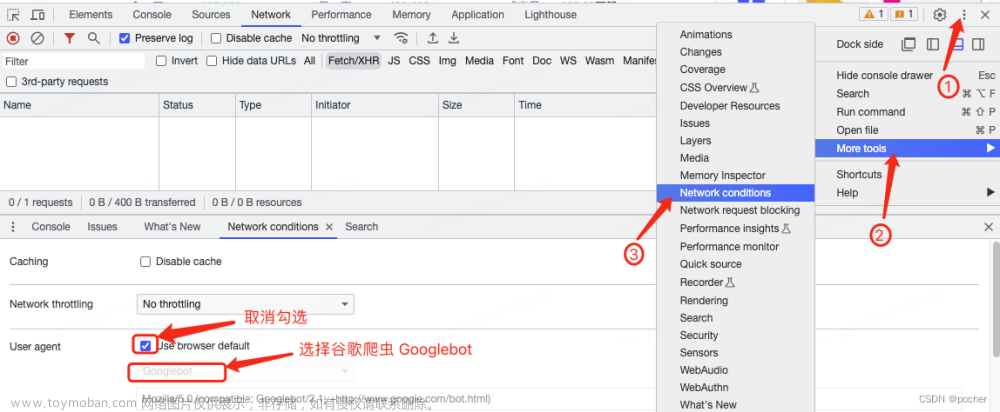
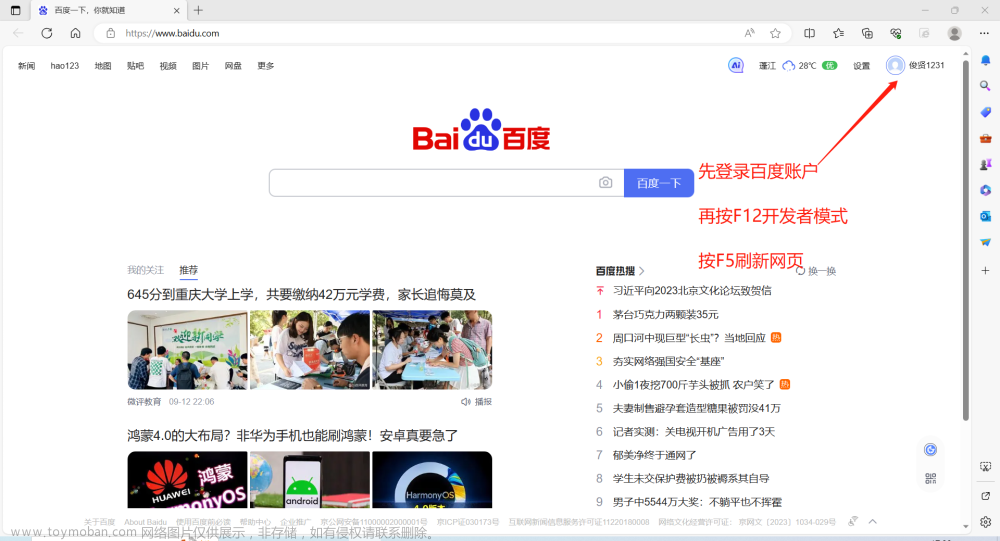
运用谷歌浏览器的开发者工具,模拟搜索引擎蜘蛛抓取网页
第一步:按压键盘上的F12键打开开发这工具,并点击右上角三个小黑点 第二步:选择More tools 第三步:选择Network conditions 第四步:找到User agent一列,取消复选框的勾选 第五步:选择谷歌爬虫agent即Googlebot 第六步:在当前浏览器地址栏中,输入想要访问的网站地址,直接访问
-
利用Selenium轻松实现网页截图功能
引言 对于初涉 Python 编程的开发者来说,自动化工具的使用可以极大地提升工作效率。在众多Python库中, Selenium 是一个强大且易用的 Web 浏览器自动化工具,它不仅可以模拟用户行为进行页面交互,还能方便地实现网页截图功能。本文将一步步教大家如何借助Selenium和ChromeD
-

UE5功能-与网页交互
首先下载WebUI插件,Releases · tracerinteractive/UnrealEngine (github.com). 插件页面 选择相应引擎版本下载,我这里选择的5.1.(ps:如果无法打开相应界面,需要先把Epic账号与Git账号关联,首先登录Epic官网,然后点击头像,点击个人信息,选择左边的连接按钮,在连接页面选择Git
-

Elasticsearch(十四)搜索---搜索匹配功能⑤--全文搜索
不同于之前的term。terms等结构化查询,全文搜索首先对查询词进行分析,然后根据查询词的分词结果构建查询。这里所说的全文指的是文本类型数据(text类型),默认的数据形式是人类的自然语言,如对话内容、图书名称、商品介绍和酒店名称等。结构化搜索关注的是数据是
-

如何使用PHP开发网页定时刷新功能
如何使用PHP开发网页定时刷新功能 随着互联网的发展,越来越多的网站需要实时更新显示数据。而实时刷新页面是一种常见的需求,它可以让用户在不刷新整个页面的情况下获得最新的数据。本文将介绍如何使用PHP开发网页定时刷新功能,并提供代码示例。 1.使用Meta标签定