-

如何使用Python抓取网页数据,最好的网页抓取Python库
网络抓取已成为当今数据驱动世界中不可或缺的工具。Python 是最流行的抓取语言之一,拥有一个由强大的库和框架组成的庞大生态系统。在本文中,我们将探索用于网络抓取的最佳Python 库,每个库都提供独特的特性和功能来简化从网站提取数据的过程。 本文还将介绍最佳库
-
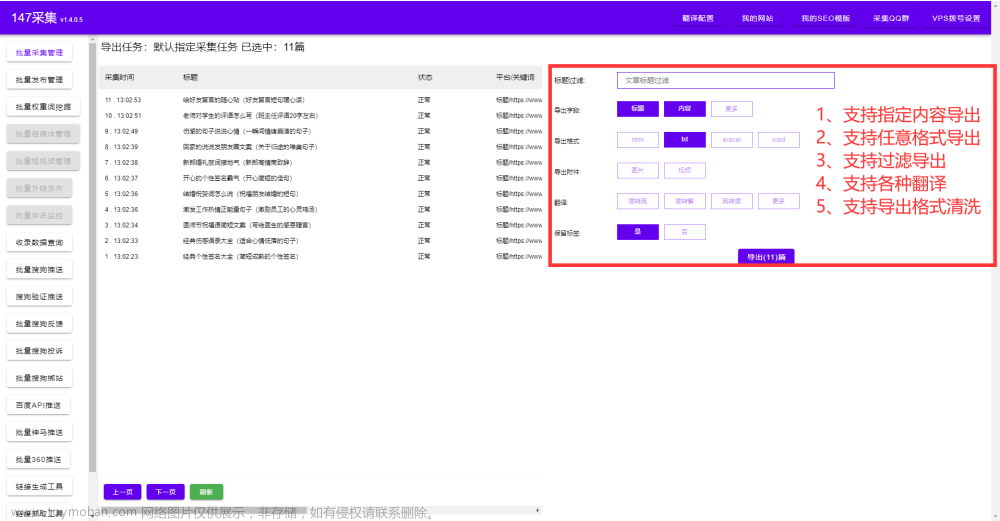
如何抓取网页数据
如何抓取网页数据,每当我们在网上找到自己想到的数据,都需要复制粘贴或下载然后一步一步地整理。 今天教大家如何快速地免费获取网页数据信息,只需要输入域名点选你需要的数据,软件全自动抓取。支持导出各种格式并且已整理归类。详细参考图片教程。 SEO是一种
-

学会XPath,轻松抓取网页数据
XPath(XML Path Language)是一种用于在 XML 文档中定位和选择节点的语言。XPath的选择功能非常强大,可以通过简单的路径选择语法,选取文档中的任意节点或节点集。学会XPath,可以轻松抓取网页数据,提高数据获取效率。 节点(Nodes): XML 文档的基本构建块,可以是元素、属
-
如何使用 Python 爬虫抓取动态网页数据
随着 Web 技术的不断发展,越来越多的网站采用了动态网页技术,这使得传统的静态网页爬虫变得无能为力。本文将介绍如何使用 Python 爬虫抓取动态网页数据,包括分析动态网页、模拟用户行为、使用 Selenium 等技术。 在进行动态网页爬取之前,我们需要先了解动态网页和静
-

Puppeteer让你网页操作更简单(2)抓取数据
Puppeteer让你网页操作更简单(1)屏幕截图】 现在您已经了解了Headless Chrome和Puppeteer的工作原理基础知识,让我们看一个更复杂的示例,其中我们实际上可以抓取一些数据。 首先,请查看此处的Puppeteer API文档。如您所见,有大量不同的方法我们可以使用不仅可以在网站上点击,还可以
-
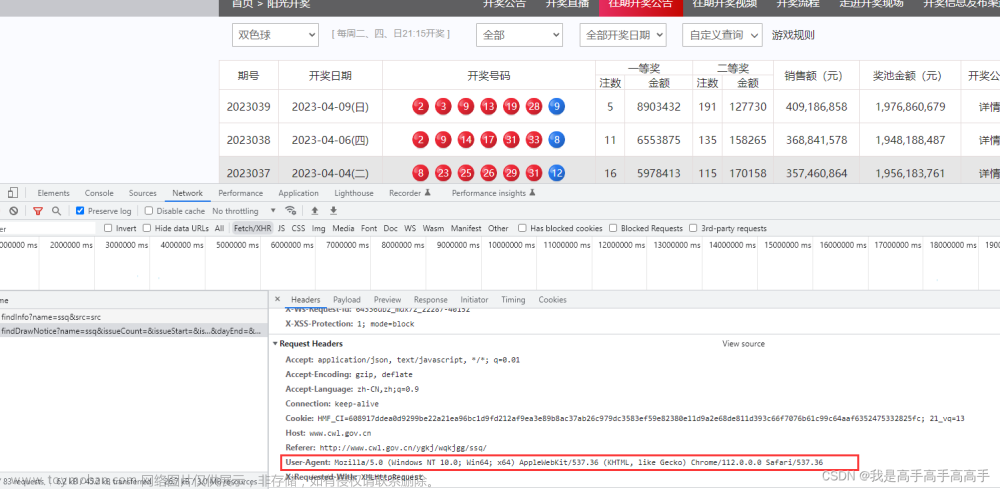
小白用chatgpt编写python 爬虫程序代码 抓取网页数据(js动态生成网页元素)
jS动态生成,由于呈现在网页上的内容是由JS生成而来,我们能够在浏览器上看得到,但是在HTML源码中却发现不了 如果不加,如果网站有防爬技术,比如频繁访问,后面你会发现什么数据都取不到 User-Agent获取地方: 网页获取位置: 使用代理IP解决反爬。(免费代理
-
简单的用Python抓取动态网页数据,实现可视化数据分析
一眨眼明天就周末了,一周过的真快! 今天咱们用Python来实现一下动态网页数据的抓取 最近不是有消息说世界首富马上要变成中国人了吗,这要真成了,可就是历史上首位中国世界首富了! 那我们就以富豪排行榜为例,爬取一下2023年国内富豪五百强,最后实现一下可视化分
-

『爬虫四步走』手把手教你使用Python抓取并存储网页数据!
爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取我们想要的数据,**本文将基于爬取B站视频热搜榜单数据并存储为例,详细介绍Python爬虫的基本流程。**如果你还在入门爬虫阶段或者不清楚爬虫的具体工作流程,那么应该仔细阅读本文! 第一步:
-

网页视频抓取插件-自动网页视频抓取插件
网页视频抓取插件 ,什么是网页视频抓取插件。相信很多朋友在互联网上都遇到很多比较好的视频,但是视频又没有下载链接,自己有很想保存视频。怎么办呢?今天给大家分享一款免费的网页视频插件。只需要输入域名,软件自动抓取视频,支持批量抓取下载。导出到本地
-
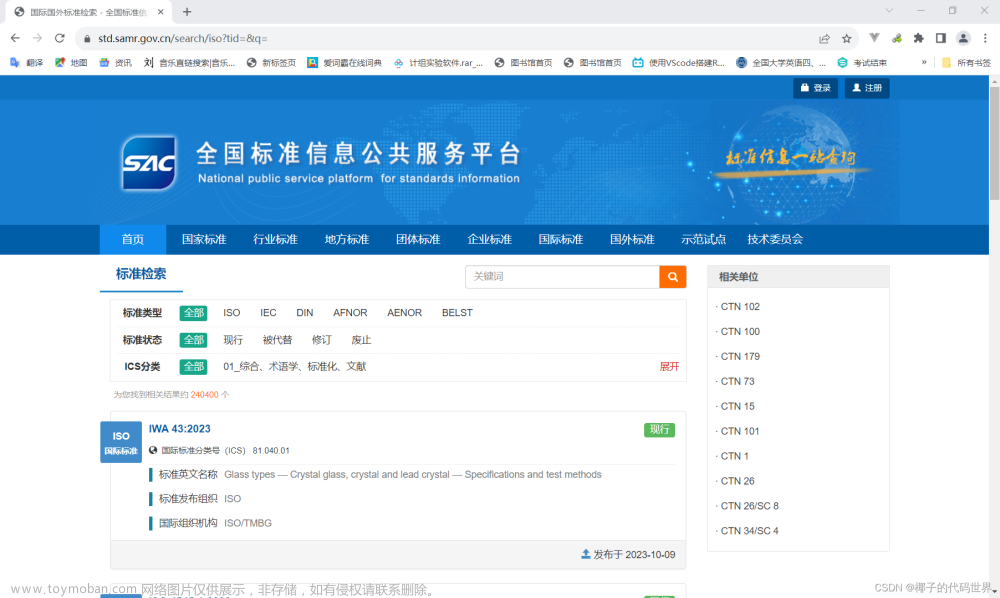
用UiPath实现网页抓取——表格数据提取-1-单击选择分类-ISO标准化-01-综合、术语、标准化、文献目录获取
准备获取目录的链接是 全国标准信息公告服务平台链接: https://std.samr.gov.cn/search/iso?tid=q= 第一步,标注啊类型选择——ISO 第二步,标准化状态选择——现行 第三步,ICS分类选择——01_综合、术语标准化、文献 将数据分别复制到excel文件中,如下图。 由于国际标准分类号在
-
Python爬虫抓取网页
本节讲解第一个 Python 爬虫实战案例:抓取您想要的网页,并将其保存至本地计算机。 首先我们对要编写的爬虫程序进行简单地分析,该程序可分为以下三个部分: 拼接 url 地址 发送请求 将照片保存至本地 明确逻辑后,我们就可以正式编写爬虫程序了。 本节内容使用 urll
-
使用Selenium抓取网页动态内容
Selenium 是一个自动化测试工具,支持多种浏览器,包括 Chrome、Firefox、Edge 等,具有强大的浏览器自动化能力,可以用于Web应用程序的自动化测试、数据挖掘等领域。Selenium的主要特点有: 支持多种浏览器 Selenium支持多种浏览器,包括Chrome、Firefox、Edge、Safari等,可以满足不同
-
爬虫项目(五):抓取网页所有图片
推荐本人书籍《Python网络爬虫入门到实战》 ,详细介绍见👉: 《Python网络爬虫入门到实战》 书籍介绍 原理:抓取该链接中所有的图片格式。基于selenium来获取,自动下载到output文件夹中。
-

绕过 IP 封锁:有效的网页抓取策略
代理服务器已成为希望克服 IP 封锁并有效收集数据的网络抓取爱好者不可或缺的工具。 随着越来越多的网站实施反抓取措施,采用这些策略以确保抓取操作成功至关重要。 在本指南中,我们将探索经过验证的技术来绕过 IP 阻止,并在代理服务器的帮助下最大限度地提高网络
-

使用Python和Selenium抓取网页内容
采集动态网页是困扰许多人的难题,不妨使用 Python 和 Selenium抓取网页数据。 微信搜索关注《Python学研大本营》,加入读者群,分享更多精彩 你是否对从网站提取数据感兴趣,但发现自己被网络抓取的复杂性所困扰?不要害怕,我们在这篇文章中将展示如何利用 Selenium 和