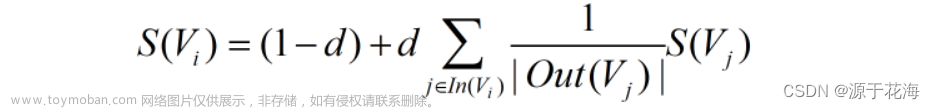前言
要高效地通过一篇文章的内容和标题生成相关关键词和简介,并且这些内容符合搜索引擎的预期,可以使用一些常见的技术和工具:
1、自然语言处理技术
使用自然语言处理技术分析文章内容和标题,以识别出与文章相关的关键词和短语。这些关键词和短语可以用作文章的标签或元数据,以帮助搜索引擎更好地了解文章的主题和内容。
2、自然语言处理技术:
使用自然语言处理技术分析文章内容和标题,以识别出与文章相关的关键词和短语。这些关键词和短语可以用作文章的标签或元数据,以帮助搜索引擎更好地了解文章的主题和内容。
3、TF-IDF算法:
使用TF-IDF算法计算文章中的每个词语的重要性,以便更好地了解文章的主题和内容。这些关键词和短语可以用作文章的标签或元数据。
4、元数据生成工具:
使用元数据生成工具可以自动从文章中提取关键词和短语,并生成符合搜索引擎预期的标题、简介和标签等元数据。这些工具通常基于自然语言处理技术和机器学习算法,可以帮助生成高质量的元数据,提高文章的搜索引擎可见性。
5、搜索引擎优化技巧:
使用搜索引擎优化技巧可以提高文章在搜索引擎中的排名。这些技巧包括在标题、描述和正文中使用关键词和短语,提高文章的可读性和可分享性,增加外部链接等。
文章来源地址https://www.toymoban.com/diary/php/247.html
文章来源:https://www.toymoban.com/diary/php/247.html
示例代码
1、使用 PHP 自然语言处理库 `php-nlp-tools` 进行关键词提取:
use \NlpTools\Tokenizers\WhitespaceTokenizer;
use \NlpTools\Tokenizers\RegexTokenizer;
use \NlpTools\Stemmers\PorterStemmer;
use \NlpTools\Documents\Document;
// 设置需要分析的文章
$doc = new Document("This is an example article about PHP and natural language processing.");
// 使用 WhitespaceTokenizer 或 RegexTokenizer 进行分词
$tokenizer = new WhitespaceTokenizer();
$tokens = $tokenizer->tokenize($doc->getText());
// 对关键词进行词干提取
$stemmer = new PorterStemmer();
$stemmed_tokens = array_map([$stemmer, 'stem'], $tokens);
// 获取前 N 个出现频率最高的关键词
$top_n = 5;
$word_counts = array_count_values($stemmed_tokens);
arsort($word_counts);
$keywords = array_slice(array_keys($word_counts), 0, $top_n);2、使用 TF-IDF 算法计算文章中的每个词语的重要性:
待续中....
到此这篇关于如何使用php提取文章中的关键词的文章就介绍到这了,更多相关内容可以在右上角搜索或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!