我们将探讨它们的基本用法以及常见的应用场景。
使用Python中的enumerate和zip函数
在Python中,内置的`enumerate`函数允许我们对序列(如列表、元组或字符串)进行迭代,并跟踪当前项的索引。
countries = ['USA', 'UK', 'Canada', 'Australia']
for index, country in enumerate(countries):
print(f"Index: {index}, Country: {country}")以上示例中,`enumerate`函数在`for`循环中用于遍历`countries`列表。在每次迭代中,`enumerate`返回列表中的索引和相应的元素。
自定义起始索引:我们还可以指定枚举的起始索引。
countries = ['USA', 'UK', 'Canada', 'Australia']
for index, country in enumerate(countries, start=2):
print(f"Index: {index}, Country: {country}")使用`enumerate()`函数有以下几个重要原因:
1. 在迭代时访问元素:它简化了同时访问序列中每个项目的索引和值的过程,无需单独计数器变量,使代码更简洁易读。
countries = ['USA', 'UK', 'Canada', 'Australia']
for index, country in enumerate(countries):
print(f"Index: {index}, Country: {country}")2. 更新列表中的元素:使用`enumerate`函数,我们可以迭代列表并更新其中的元素。
numbers = [1, 2, 3, 4, 5] for index, value in enumerate(numbers): numbers[index] = value * 2 print(numbers) # 输出: [2, 4, 6, 8, 10]
3. 创建包含索引的新序列:我们可以使用`enumerate()`函数构造包含原始值及其相应索引的新序列。
countries = ['USA', 'UK', 'Canada', 'Australia'] list(enumerate(countries)) # [(0, 'USA'), (1, 'UK'), (2, 'Canada'), (3, 'Australia')]
4. 逐行处理文件内容:在读取文件并逐行处理其内容时,我们可以使用`enumerate`函数来跟踪行号。
with open('example.txt', 'r') as file:
for line_number, line_content in enumerate(file, start=1):
print(f"Line {line_number}: {line_content.strip()}")`enumerate()`函数在处理Python中的序列和索引时,可以编写干净、简洁且具有表达力的代码。
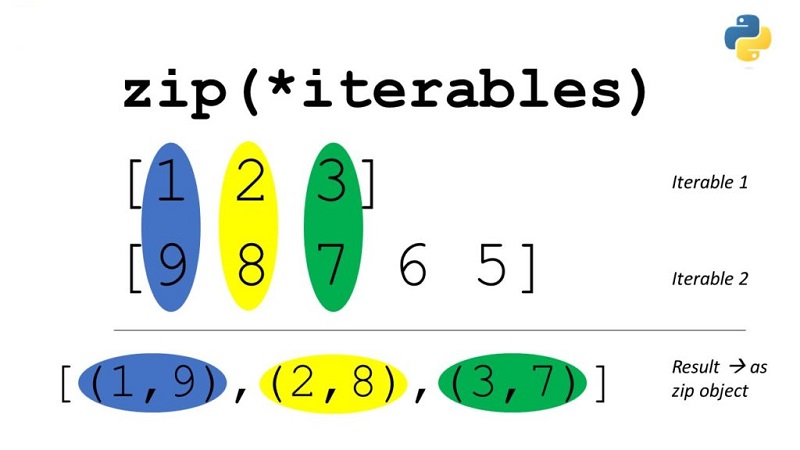
zip函数
`zip`函数也是Python中的一个内置函数,它可以同时处理多个序列中的元素,并确保能够同时访问这些元素。使用`zip`函数可以简化代码,避免嵌套循环或手动基于索引进行追踪。
fruits = ["Apple", "Grape"]
prices = [25, 30]
for fruit, price in zip(fruits, prices):
print(f"Fruit: {fruit}, Price: {price}")使用`zip()`函数有以下几个重要原因:
1. 创建成对或元组:`zip`通常用于将两个或多个列表中的元素进行配对,例如:
list1 = [1,2,3] list2 = ['a', 'b', 'c'] pairs = list(zip(list1, list2)) print(pairs) # [(1, 'a'), (2, 'b'), (3, 'c')]
2. 创建字典:我们可以使用`zip`来将两个单独的列表中的键和值配对,从而创建字典。
keys = ['name', 'age', 'city']
values = ['John', 25, 'New York']
user_info = dict(zip(keys, values))
print(user_info) # {'name': 'John', 'age': 25, 'city': 'New York'}3. 同时迭代多个列表:当你有两个相关的列表(例如姓名和年龄),并且想要同时处理每对元素时,可以使用`zip`函数。
names = ['Alice', 'Bob', 'Charlie']
ages = [25, 30, 35]
for name, age in zip(names, ages):
print(f"Name: {name}, Age: {age}")4. 合并不同来源的数据:使用`zip`函数,我们可以合并来自不同来源的数据并返回一个元组。
list1 = [1,2,3] list2 = ['a', 'b', 'c'] list(zip(list1, list2)) # [(1, 'a'), (2, 'b'), (3, 'c')]
5. 解压列表:我们可以使用`zip`函数将元组序列解压为单独的列表。
tup = [(1, 'a'), (2, 'b'), (3, 'c')]
list1, list2 = zip(*tup)
print(list1) # (1, 2, 3)
print(list2) # ('a', 'b', 'c')处理长度不等的可迭代对象:当我们将不同长度的可迭代对象传递给`zip`函数时,它会在最短的输入可迭代对象用尽时停止创建元组。生成的迭代器将具有与最短输入可迭代对象相同数量的元素,较长的可迭代对象中的任何剩余元素将被忽略。
list1 = [1, 2, 3] list2 = ['a', 'b', 'c', 'd'] result = list(zip(list1, list2)) print(result) # [(1, 'a'), (2, 'b'), (3, 'c')]
`zip()`函数是Python中用于处理多个序列的通用函数,可以编写干净、高效的代码。它的能力使得合并、转置和解压数据在各种编程任务中变得非常有价值。
通过使用`enumerate`和`zip`函数,我们可以更方便地处理序列和索引,同时提高代码的可读性和简洁性。无论是迭代访问元素、更新列表元素还是处理多个序列,这两个函数都是强大且实用的工具文章来源:https://www.toymoban.com/diary/python/672.html
文章来源地址https://www.toymoban.com/diary/python/672.html
到此这篇关于Python中的enumerate和zip函数介绍及应用的文章就介绍到这了,更多相关内容可以在右上角搜索或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!