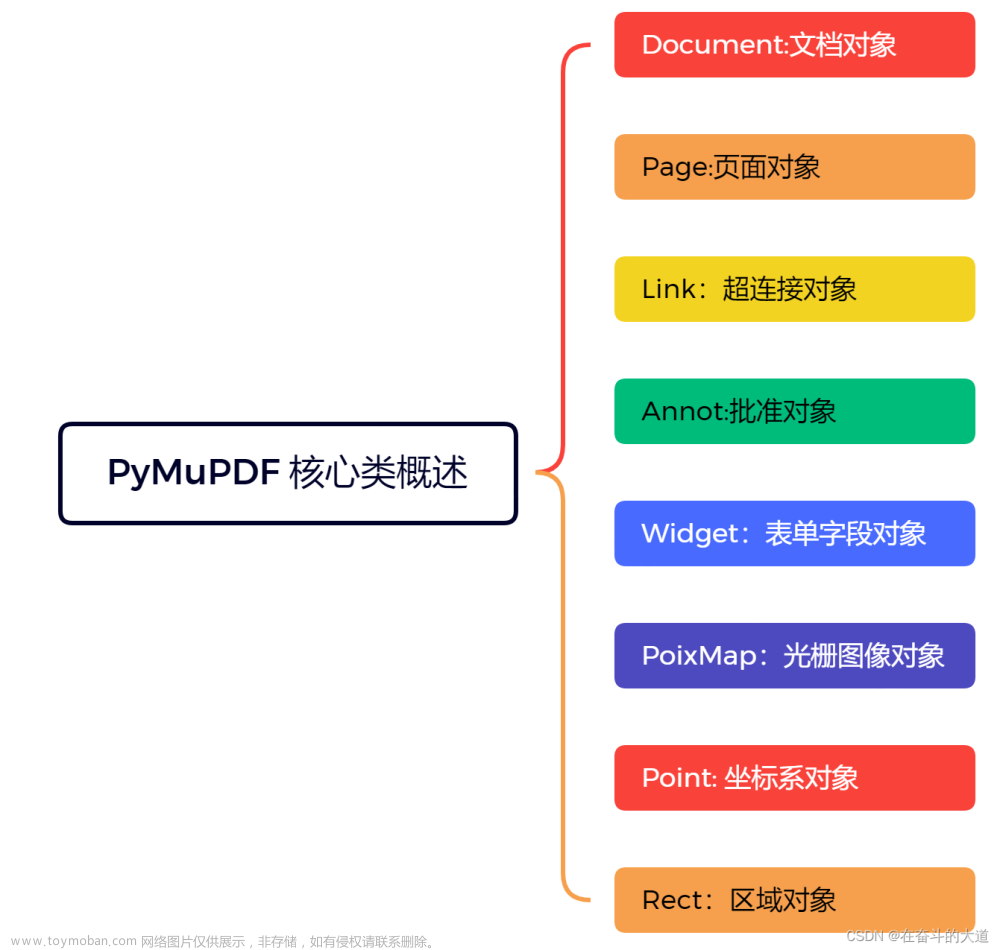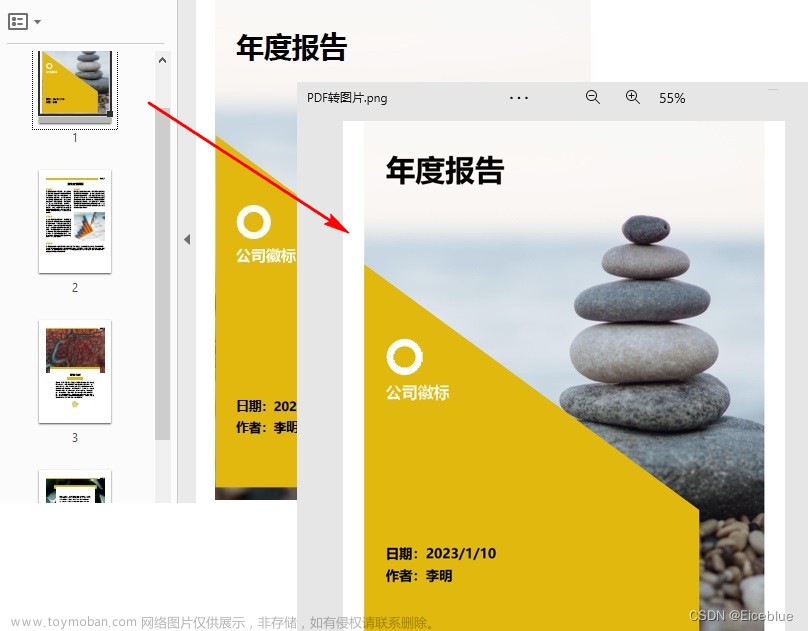
环境准备
在开始之前,确保你的Python环境中安装了正确版本的pymupdf库。推荐使用pymupdf==1.18.16版本,因为其他版本可能会在调用get_pixmap属性时出现异常。你可以通过以下命令进行安装:
pip install pymupdf==1.18.16
转换流程
1.导入库
首先,你需要导入fitz模块,这是pymupdf库的核心组件。
import fitz
2.打开PDF文件
使用fitz.open函数打开你的PDF文件,并指定文件路径。
doc = fitz.open(pdf_path)
3.选择页面
通过指定页面编号,你可以获取PDF中的特定页面。
page = doc[page_number]
4.转换为图片
使用get_pixmap方法将PDF页面转换为图片。你可以通过调整scale参数来控制输出图片的清晰度。增加scale的值不仅可以提高图片质量,但也可能增加转换时间和文件大小。
# 定义清晰度比例 scale = 2.0 # 你可以根据需要调整这个值 # 转换页面为图片 pix = page.get_pixmap(alpha=True, matrix=fitz.Matrix(scale, scale))
5.保存图片
将转换后的图片保存到指定路径。确保你的路径是正确的,并且你有足够的权限来写入文件。
pix.save(output_path)
6.关闭文档
转换完成后,不要忘记关闭PDF文档以释放资源。
doc.close()
注意事项
安装版本 pymupdf==1.18.16
安装其他版本会异常找不到get_pixmap这个属性文章来源:https://www.toymoban.com/diary/python/751.html
完整代码示例
import fitz # 打开PDF文件 pdf_path:pdf文件路径 doc = fitz.open(pdf_path) # 获取指定页面 page_number:根据下标获取页数,或使用循环 page = doc[page_number] # 转换为图片,scale参数可以调整清晰度 # 增加 scale 的值可以提高图片的清晰度,但同时可能会增加转换时间和生成的图片文件大小。 pix = page.get_pixmap(alpha=True, matrix=fitz.Matrix(scale, scale)) # 保存图片 output_path:图片路径 pix.save(output_path) # 关闭PDF文档 doc.close()
文章来源地址https://www.toymoban.com/diary/python/751.html
到此这篇关于使用 Python将pdf转化为图片的文章就介绍到这了,更多相关内容可以在右上角搜索或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!