让我们一起来学习 SQL 基础知识,例如创建表、架构和视图。
SQL:我们都是这方面的专家吗?其实都是假装的,而且多亏了 百度,CSDN等技术分享平台,我们很多问题都是在这上面找到答案的。结合我们在 90 年代学习如何编码的丰富经验,我们对 PHPMyAdmin 和 LAMP 堆栈,集成环境中的现场工作基本上使我们成为专业程序员。如何继续在你的程序简历人生写下更多简历信息?而不是单单的我会某某集成环境下的开发?
SQL 的存在时间比我们的职业生涯还要长,那么为什么现在要开始一个关于它的系列呢?当然有足够多的文档供我们在需要编写查询时通过 百度、360、Bing、Google 搜索具体信息吗?我的朋友们,这正是问题所在。无论我们拥有什么可用的工具,有些技能最好还是熟记于心地学习和练习。SQL 就是其中一项技能。
当然,SQLAlchemy 或类似的 ORM 可能会保护我们不时地编写原始查询。考虑到 SQL 只是我们经常使用的众多查询语言之一(除了 NoSQL、GraphQL、JQL 等),成为 SQL 专家真的那么重要吗?简而言之,是的:关系数据库不仅会继续存在,而且将查询作为第二语言进行思考可以巩固人们对数据细节的理解。Marc Laforet最近发表了一篇 Medium 文章,其中阐述了依赖 SQL 的重要性:
更有趣的是,当这些转换脚本应用于 6.5 GB 数据集时,python 完全失败了。在 3 次尝试中,Python 崩溃了 2 次,而我的计算机在第 3 次完全死机……而 SQL 花了 226 秒。
将逻辑排除在我们的应用程序、管道以及 SQL 之外可以使执行速度呈指数级增长,同时比我们用我们选择的语言编写的任何内容都更具可读性和普遍理解性。我们可以将应用程序逻辑推送到堆栈中的位置越低越好。这就是为什么我更愿意看到数据领域充斥着 SQL 教程,而不是 Pandas 教程。
关系数据库术语
我讨厌信息材料一开始就涵盖明显的术语定义。一般情况下,我觉得这是陈词滥调,毫无帮助,而且有损作者的可信度;但这些都不是正常情况。在 SQL 中,词汇通常具有多种含义,具体取决于上下文,甚至取决于您使用的数据库类型。鉴于这一事实,个人完全有可能(并且很常见)积累关系数据库的经验,同时完全误解基本概念。让我们确保不会发生这种情况:
数据库:每个数据库实例都在最高级别上分为数据库。是的,数据库是数据库的集合 - 我们已经有了一个良好的开端。
模式:在 PostgreSQL(和其他数据库)中,模式是表和其他对象的分组,包括视图、关系等。模式是组织数据的一种方式。模式意味着属于它的所有数据都以某种形式相关,即使只是概念上相关。请注意,术语模式有时根据上下文用于描述其他概念。
表:关系数据库的主要部分。表格由行和列组成,其中保存着我们的甜蜜数据。列最好被视为“属性”,而行是由所述属性的值组成的条目。列中的所有值必须共享相同的数据类型。
主键:每行数据的标识标签。关系数据库中每条记录的主键都是不同的;必须提供值,并且它们在行之间必须是唯一的。
外键:启用主数据库表和其他相关数据库之间的数据搜索和操作。
键:键用于帮助我们组织和优化数据,并对传入的数据施加某些限制(例如,用户帐户的电子邮件地址必须是唯一的)。键还可以帮助我们记录条目的数量,确保自动唯一的值,并提供链接多个数据表的桥梁。
对象:模式(某种程度上特定于 PostgreSQL)中存在的任何事物(包括关系)的总称。
视图(PostgreSQL):视图以类似于表的方式显示数据,不同之处在于视图不存储数据。视图是以查询的形式从其他表中提取数据的快照;考虑视图的一个好方法是将它们视为“虚拟表”。
函数 (PostgreSQL):与为了重用而保存的数据进行交互的逻辑。
在 MySQL 中,模式与数据库同义。这些关键字甚至可以在 MySQL 中互换使用 SCHEMA 和 DATABASE。因此,使用CREATE SCHEMA可以达到与 代替 相同的效果CREATE DATABASE。
导航和创建数据库
我们必须从某个地方开始,所以最好从数据库管理开始。诚然,这将是我们将要介绍的内容中最无用的。浏览数据库的行为最适合 GUI。
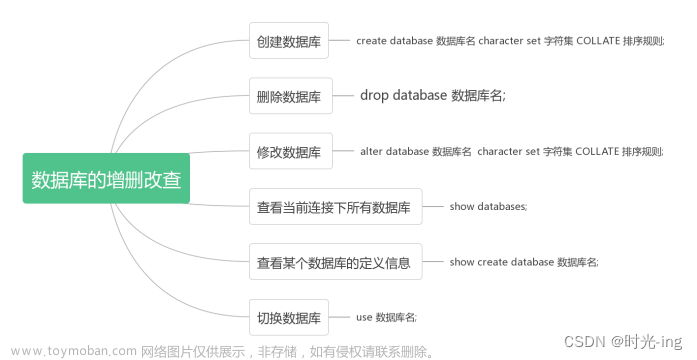
显示数据库
如果您通过命令行 shell 访问数据库(出于某种原因),第一个合乎逻辑的事情就是列出可用的数据库:
SHOW DATABASES; +--------------------+ | Database | +--------------------+ | classicmodels | | information_schema| | mysql | | performance_schema| | sys | +--------------------+ 5 rows in set (0.00 sec)
使用数据库
现在我们已经列出了可以连接的可能数据库,我们可以探索每个数据库包含的内容。为此,我们必须指定要连接到哪个数据库,也称为“使用”。
db> USE database_name; Database changed
创建数据库
创建数据库很简单。创建数据库时一定要注意字符集:这将决定您的数据库能够接受哪些类型的字符。例如,如果我们尝试将特殊编码字符插入到简单的 UTF-8 数据库中,这些字符将不会按照我们的预期显示。
CREATE DATABASE IF NOT EXISTS database_name CHARACTER SET utf-8 [COLLATE collation_name]
奖励:这是创建数据库然后显示结果的简写:
SHOW CREATE DATABASE database_name;
创建和修改表
在自动化数据导入时,通过 SQL 语法创建表非常重要。创建表时,我们还设置列名、类型和键:
CREATE TABLE [IF NOT EXISTS] table_name ( column_name_1 [COLUMN_DATA_TYPE] [KEY_TYPE] [KEY_ATTRIBUTES] DEFAULT [DEFAULT_VALUE], column_name_2 [COLUMN_DATA_TYPE] [KEY_TYPE] [KEY_ATTRIBUTES] DEFAULT [DEFAULT_VALUE], PRIMARY KEY (column_name_1) ) ENGINE=[ENGINE_TYPE];
我们可以在创建表时指定IF NOT EXISTS是否要在查询中包含验证。如果存在,则仅当指定名称的表不存在时才会创建该表。
创建每个列时,我们可以为每个列指定许多内容:
数据类型(必填):该列单元格可以保存的数据(如INTEGER、TEXT等)。
键类型:为列创建键。
键属性:任何与键相关的属性,例如自动递增。
默认值:如果在表中创建行时没有将值传递到当前列,则该值指定为DEFAULT
主键:允许将之前指定的任何列设置为表的主键。
MySQL表可以有一个通过指定的“存储引擎” ENGINE=[engine_type],它决定了表如何解释数据的核心逻辑。将此字段留空默认为 InnoDB,并且几乎可以肯定不用管它。如果您有兴趣,可以在这里(https://dev.mysql.com/doc/refman/8.0/en/storage-engines.html?ref=hackersandslackers.com)找到有关 MySQL 引擎的更多信息。
下面是实际查询的示例CREATE TABLE:
CREATE TABLE IF NOT EXISTS awards ( id INTEGER PRIMARY KEY AUTO_INCREMENT, recipient TEXT NOT NULL, award_name TEXT DEFAULT 'Grammy', PRIMARY KEY (id) ) ENGINE=INNODB;
管理现有表的键
如果我们在创建表时没有指定键,我们总是可以在事后指定键。SQL 表可以接受以下键类型:
主键:唯一标识表中一条记录的一个或多个字段/列。它不能接受空值、重复值。
候选键:候选键类似于一组未提交的主键;这些键只接受唯一值,并且如果需要的话可以用来代替主键,但不是实际的主键。与主键不同,每个表可能存在多个候选键。
备用键:指单个候选键(可以满足主键 id 需要的替代值)。
Composite/Compound Key:通过组合多个列的值来定义;它们的总和总会产生一个独特的价值。一张表中可以有多个候选键。每个候选键都可以作为主键。
唯一键:表的一组一个或多个字段/列,唯一标识数据库表中的记录。与主键类似,但只能接受一个空值,并且不能有重复值。
外键:外键表示充当另一个表的主键的字段。外键对于建立表之间的关系很有用。虽然作为主表的父表中需要外键,但在与其他表相关的表中,外键可以为 null 或为空。
让我们看一个示例查询,其中我们向表添加一个键并剖析各个部分:
ALTER TABLE table_name
ADD FOREIGN KEY foreign_key_name (column_name)
REFERENCES parent_table(columns)
ON DELETE { NO ACTION | CASCADE | SET NULL | SET DEFAULT }
ON UPDATE { NO ACTION | CASCADE | SET NULL | SET DEFAULT }ALTER TABLE用于对表结构进行任何更改,无论是修改列还是键。
在此示例中,我们的ADD键恰好是FOREIGN KEY. 虽然键始终引用列,但键本身必须有自己的名称,以区分列的数据和键的概念逻辑。我们命名我们的键foreign_key_name并指定该键将作用于哪一列(column_name)。因为这是一个外键,所以我们需要指定我们希望它与哪个表的主键关联。REFERENCES parent_table(primary_key_column)表示该表中的外键对应于名为 的表中名为primary_key_column的列中保存的值parent_table。
语句ON DELETE和ON UPDATE是分别在父表的主键被删除或更新时发生的操作。ON DELETE CASCADE如果相应的主键消失,将导致我们的表外键被删除。
添加列
添加列遵循我们创建表时使用的相同语法。一个有趣的附加功能是能够将新列放置在现有列之前或之后:
ALTER TABLE table_name ADD COLUMN column_name [DATA_TYPE] [FIRST|AFTER existing_column];
当引用PostgreSQL数据库中的表时,我们必须指定所属的模式。因此,ALTER TABLE table_name变为ALTER TABLE schema_name.table_name. 这适用于我们引用表的任何时候,包括创建和删除表时。
突击测验
下面的语句使用了我们迄今为止所学到的有关修改和创建表结构的所有元素。你能看出这里发生了什么吗?
CREATE TABLE vendors( vdr_id int not null auto_increment primary key, vdr_name varchar(255) )ENGINE=InnoDB; ALTER TABLE products ADD COLUMN vdr_id int not null AFTER cat_id; ALTER TABLE products ADD FOREIGN KEY fk_vendor(vdr_id) REFERENCES vendors(vdr_id) ON DELETE NO ACTION ON UPDATE CASCADE;
丢弃数据
危险区域:这是我们可能开始把事情搞砸的地方。删除列或表会导致数据完全丢失:每当您看到“删除”一词时,都会感到害怕。
如果您确定知道自己在做什么并且想要删除表列,可以按如下方式完成:
ALTER TABLE tableDROP column;
删除表会破坏表结构及其中的所有数据:
DROP TABLE table_name;
另一方面,截断表将清除表中的数据,但保留表本身:
TRUNCATE TABLE table_name;
删除外键
像表和列一样,我们也可以删除键:
ALTER TABLE table_name DROP FOREIGN KEY constraint_name;
这也可以通过删除 CONSTRAINT 来处理:
ALTER TABLE public.jira_epiccolors DROP CONSTRAINT jira_epiccolors_pkey;
使用视图(特定于 PostgreSQL)
最后,让我们探讨一下创建视图的行为。PostgreSQL 可以处理三种类型的视图:
简单视图:代表基础表数据的虚拟表。简单视图是自动可更新的:系统将允许在视图上使用 INSERT、UPDATE 和 DELETE 语句,就像在常规表上一样。
物化视图:PostgreSQL 将视图概念扩展到了一个新的水平,允许视图“物理”存储数据,我们将这些视图称为物化视图。物化视图缓存复杂查询的结果,然后允许您定期刷新结果。
递归视图:如果不深入研究递归报告的复杂(但很酷!)功能,递归视图有点难以解释。我不会详细介绍,但这些视图能够表示多层深入的关系。如果您好奇的话,可以快速体验一下:
示例RECURSIVE 查询:
WITH RECURSIVE reporting_line AS ( SELECT employee_id, full_name AS subordinates FROM employees WHERE manager_id IS NULL UNION ALL SELECT e.employee_id, ( rl.subordinates || ' > ' || e.full_name ) AS subordinates FROM employees e INNER JOIN reporting_line rl ON e.manager_id = rl.employee_id ) SELECT employee_id, subordinates FROM reporting_line ORDER BY employee_id;
输出:
employee_id | subordinates -------------+-------------------------------------------------------------- 1 | Michael North 2 | Michael North > Megan Berry 3 | Michael North > Sarah Berry 4 | Michael North > Zoe Black 5 | Michael North > Tim James 6 | Michael North > Megan Berry > Bella Tucker 7 | Michael North > Megan Berry > Ryan Metcalfe 8 | Michael North > Megan Berry > Max Mills 9 | Michael North > Megan Berry > Benjamin Glover 10 | Michael North > Sarah Berry > Carolyn Henderson 11 | Michael North > Sarah Berry > Nicola Kelly 12 | Michael North > Sarah Berry > Alexandra Climo 13 | Michael North > Sarah Berry > Dominic King 14 | Michael North > Zoe Black > Leonard Gray 15 | Michael North > Zoe Black > Eric Rampling 16 | Michael North > Megan Berry > Ryan Metcalfe > Piers Paige 17 | Michael North > Megan Berry > Ryan Metcalfe > Ryan Henderson 18 | Michael North > Megan Berry > Max Mills > Frank Tucker 19 | Michael North > Megan Berry > Max Mills > Nathan Ferguson 20 | Michael North > Megan Berry > Max Mills > Kevin Rampling (20 rows)
创建视图
创建简单视图就像编写标准查询一样简单!所需要做的就是在查询之前添加CREATE VIEW view_name AS,这将为我们创建一个保存的位置,以便我们始终返回并引用此查询的结果:
CREATE VIEW comedies AS SELECT * FROM films WHERE kind = 'Comedy';
走出去并开始 SQLing
我强烈鼓励任何人养成手动编写 SQL 查询的习惯。有了正确的 GUI,自动完成功能就可以成为您最好的朋友。
明确地强迫自己编写查询而不是复制和粘贴任何内容迫使我们认识到,例如 SQL 的操作顺序。事实上,这个查询拥有正确的语法......
SELECT *FROM table_nameWHERE column_name = 'Value';
...而这个则没有:文章来源:https://www.toymoban.com/diary/sql/574.html
SELECT *WHERE column_name = 'Value'FROM table_name;
掌握 SQL 的微妙之处是速度极快和几乎一无所知之间的区别。好消息是,您会开始发现这些概念并不像它们曾经看起来那样令人畏惧,因此从“糟糕的数据工程师”到“专家”的道路是一个轻松的胜利,如果不这样做那就太愚蠢了拿。文章来源地址https://www.toymoban.com/diary/sql/574.html
到此这篇关于从零开始学习SQL操作:修改数据库和表的文章就介绍到这了,更多相关内容可以在右上角搜索或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!