卷积可视化解释:
YJango的卷积神经网络——介绍 - 知乎
NCHW/NHWC到NC1HWC0数据格式图解
C1=C/C0,不足的部分补0。C0通常为4、8、16等。

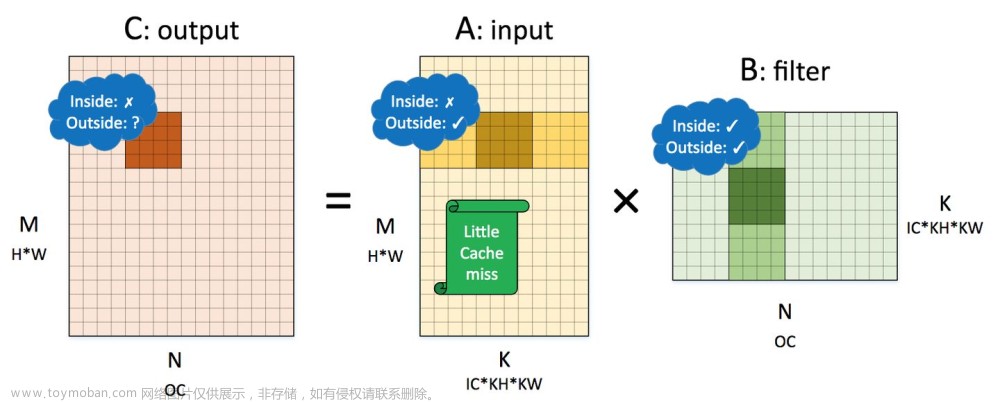
im2col原理
滑窗卷积和im2col后二维矩阵数据保存的关系如下图(filter im2col转矩阵相对比较简单,直接每个通道的卷积核展开成一个列向量和padding即可)。
这里演示的卷积filter大小为2x2,stride=1。特殊情况filter大小为1x1时最简单,每个channel数据直接就对应于im2col后矩阵的一行。
第一步滑窗filter覆盖的4个pixel数据对应于黑色条带覆盖的部分。第二步滑窗filter覆盖的4个pixel数据对应于蓝色条带覆盖的部分。然后黄色和青色条带对应于第三步和第四步滑窗。

实际内存读取的方式如下图,从内存连续读取从而充分利用cache。
图中黑色条带显示了从起始地址连续读取3个c0通道元素,这相当于读取了3步(0-2步)滑窗卷积对应于filter(0,0)位置的数据。这相当于是批处理读取了3步滑窗的数据。蓝色条带显示了从黑色条带往后移动一个c0位置再连续读取3个c0通道元素,这相当于读取了0-2步滑窗卷积对应于filter(0,1)位置的数据。
但是,对于2x2大小的filter下一步则不是继续往后移动一个c0位置再读取。这时候可以考虑进行横向移动,按黄色条带所示连续读取3个c0通道元素,相当于读取与前面相同3步(0-2步)滑窗卷积对应于filter(1,0)位置的数据。然后再从黄色条带位置往后移动一个c0位置,按青色条带显示方式读取3个c0通道元素,相当于读取0-2步滑窗卷积对应于filter(1,1)位置的数据。
当然,在前面蓝色条带读取后,也可以考虑直接往后移动到黑色条带的结束位置,按绿色条带显示的方式连续读取3个c0通道元素,这相当于读取了新的3步(3-5步)滑窗卷积对应于filter(0,0)位置的数据。然后再往后移动一个c0位置,按橘色条带读取3个c0通道元素,这相当于读取了新的3步(3-5步)滑窗卷积对应于filter(0,1)位置的数据。这样相比直接跳转到黄色条带部分读取应该能更好的利用cache数据。当然这里应该要综合考虑矩阵乘法分块大小和double buffer数据准备的方式。如果一个处理线程本来就要处理2n*批处理滑窗步数卷积的元素,则可以考虑这样读取。
这两种方式的区别一种是优先读取每个批处理滑窗在每个filter元素覆盖的数据,另一种是先读取分块范围内所有滑窗steps的filter第1行像素覆盖的数据,再读取所有滑窗steps的filter第2行像素覆盖的数据。同样的方式也适用于处理不同c0的元素(图中红色和橙色矩阵的元素),一种是读取了第一个批处理滑窗在c0的元素然后直接切换到第二个c0继续读取第一个批处理滑窗位于第二个c0的元素。也可以在分块范围内读取了所有批处理滑窗在c0的元素后再切换到第二个c0读取。

im2col实现方案
方案1:把im2col是做成一个单独的算子,把卷积拆分为im2col+MatMul两个算子,也被称为显式矩阵乘卷积(explicit GEMM convolution)。
方案2:把im2col做成矩阵乘数据读取的部分,并与真正矩阵乘实现double buffer,从而避免中间数据的读写global mem,也被称为隐式矩阵乘卷积(implicit GEMM convolution)。
方案1实施起来更加简单,但是存在中间数据的写回和读取和矩阵乘读取global mem,占用内存空间大,性能差。方案2基于一个整体算子来实施,实现过程相对比较复杂,但是性能更高,内存占用更少。
todo:
如何基于矩阵分块等方法进行并行加速,基于GPU实现细节。
REF
图解NC4HW4使用im2col+gemm计算卷积 - 知乎
Tensor中数据摆放顺序NC4HW4是什么意思,只知道NCHW格式,能解释以下NC4HW4格式吗? - 知乎
【模型推理】谈谈为什么卷积加速更喜欢 NHWC Layout - 知乎
im2col方法实现卷积算法 - 知乎
im2col矩阵卷积原理_damonlearning的博客-CSDN博客_im2col 卷积文章来源:https://www.toymoban.com/news/detail-400082.html
OpenPPL 中的卷积优化技巧 - 知乎文章来源地址https://www.toymoban.com/news/detail-400082.html
到了这里,关于im2col+gemm实现卷积基础的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!