上一篇:yolo v5-release6.0转rknn
下一篇:yolo v8 转rknn
一、训练
1.切换版本
git clone https://github.com/WongKinYiu/yolov7.git
cd yolov7
git checkout 44d8ab41780e24eba563b6794371f29db0902271
2.训练
v7的训练可以参考v5训练:yolov5 初识(ubuntu版)、yolov5 初识(win版)
二、pt2onnx
注意一下,opset_version=12
python export.py --weights="runs/train/exp/weights/best.pt" --simplify
三、onnx2rknn
1.RK356X虚拟环境配置
git clone https://github.com/rockchip-linux/rknn-toolkit2.git
cd rknn-toolkit2
conda create -n rknn-toolkit2 python=3.6
conda activate rknn-toolkit2
pip install doc/requirements_cp36-*.txt
# if install bfloat16 failed, please install numpy manually first. "pip install numpy==1.16.6"
pip install doc/requirements_cp36-*.txt
pip install packages/rknn_toolkit2-*-cp36-*.whl
2.rknn-toolkit2/example/onnx下创建自己的项目,例如myyolov7,如下:
(样式照搬官方已有实例:test.jpg为任意一张测试集里的数据,dataset.txt为量化数据集的路径(200~500张?我也不太确定,这里只用了1张),test.py为转换代码,需修改。)
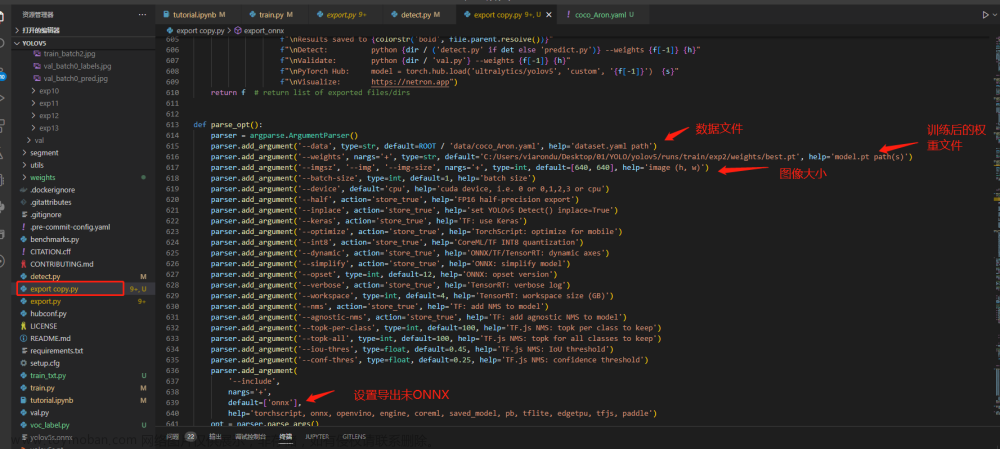
3.修改test.py
直接上图:
1.输入的一些设置

2.输出的一些设置

由来:
用这个网站打开转换的onnx模型
然后找到模型的三个输出,进行如下图的操作:

另外2个节点相同操作方法。
3.后处理的一些设置
anchors用yolov7训练的:
由来: 文章来源:https://www.toymoban.com/news/detail-400357.html
文章来源:https://www.toymoban.com/news/detail-400357.html
4.显示
 文章来源地址https://www.toymoban.com/news/detail-400357.html
文章来源地址https://www.toymoban.com/news/detail-400357.html
四、 完整代码:
import os
import urllib
import traceback
import time
import sys
import numpy as np
import cv2
from rknn.api import RKNN
ONNX_MODEL = '/home/tm1/win/E/workspace/yolo/yolov7/runs/train/exp/weights/best.onnx'
RKNN_MODEL = 'yolov7.rknn'
IMG_PATH = './test.jpg'
DATASET = './dataset.txt'
QUANTIZE_ON = True
BOX_THESH = 0.45
NMS_THRESH = 0.25
IMG_SIZE = 640
CLASSES = ["EarTag"]
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def xywh2xyxy(x):
# Convert [x, y, w, h] to [x1, y1, x2, y2]
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def process(input, mask, anchors):
anchors = [anchors[i] for i in mask]
grid_h, grid_w = map(int, input.shape[0:2])
box_confidence = sigmoid(input[..., 4])
box_confidence = np.expand_dims(box_confidence, axis=-1)
box_class_probs = sigmoid(input[..., 5:])
box_xy = sigmoid(input[..., :2]) * 2 - 0.5
col = np.tile(np.arange(0, grid_w), grid_w).reshape(-1, grid_w)
row = np.tile(np.arange(0, grid_h).reshape(-1, 1), grid_h)
col = col.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
row = row.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
grid = np.concatenate((col, row), axis=-1)
box_xy += grid
box_xy *= int(IMG_SIZE / grid_h)
box_wh = pow(sigmoid(input[..., 2:4]) * 2, 2)
box_wh = box_wh * anchors
box = np.concatenate((box_xy, box_wh), axis=-1)
return box, box_confidence, box_class_probs
def filter_boxes(boxes, box_confidences, box_class_probs):
"""Filter boxes with box threshold. It's a bit different with origin yolov5 post process!
# Arguments
boxes: ndarray, boxes of objects.
box_confidences: ndarray, confidences of objects.
box_class_probs: ndarray, class_probs of objects.
# Returns
boxes: ndarray, filtered boxes.
classes: ndarray, classes for boxes.
scores: ndarray, scores for boxes.
"""
box_classes = np.argmax(box_class_probs, axis=-1)
box_class_scores = np.max(box_class_probs, axis=-1)
pos = np.where(box_confidences[..., 0] >= BOX_THESH)
boxes = boxes[pos]
classes = box_classes[pos]
scores = box_class_scores[pos]
return boxes, classes, scores
def nms_boxes(boxes, scores):
"""Suppress non-maximal boxes.
# Arguments
boxes: ndarray, boxes of objects.
scores: ndarray, scores of objects.
# Returns
keep: ndarray, index of effective boxes.
"""
x = boxes[:, 0]
y = boxes[:, 1]
w = boxes[:, 2] - boxes[:, 0]
h = boxes[:, 3] - boxes[:, 1]
areas = w * h
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x[i], x[order[1:]])
yy1 = np.maximum(y[i], y[order[1:]])
xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]])
yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]])
w1 = np.maximum(0.0, xx2 - xx1 + 0.00001)
h1 = np.maximum(0.0, yy2 - yy1 + 0.00001)
inter = w1 * h1
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= NMS_THRESH)[0]
order = order[inds + 1]
keep = np.array(keep)
return keep
def yolov5_post_process(input_data):
masks = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
yolov5_anchors = [[10, 13], [16, 30], [33, 23],
[30, 61], [62, 45], [59, 119],
[116, 90], [156, 198], [373, 326]]
yolov7_anchors = [[12, 16], [19, 36], [40, 28],
[36, 75], [75, 55], [72, 146],
[142, 110], [192, 243], [459, 401]]
boxes, classes, scores = [], [], []
for input, mask in zip(input_data, masks):
b, c, s = process(input, mask, yolov5_anchors)
b, c, s = filter_boxes(b, c, s)
boxes.append(b)
classes.append(c)
scores.append(s)
boxes = np.concatenate(boxes)
boxes = xywh2xyxy(boxes)
classes = np.concatenate(classes)
scores = np.concatenate(scores)
nboxes, nclasses, nscores = [], [], []
for c in set(classes):
inds = np.where(classes == c)
b = boxes[inds]
c = classes[inds]
s = scores[inds]
keep = nms_boxes(b, s)
nboxes.append(b[keep])
nclasses.append(c[keep])
nscores.append(s[keep])
if not nclasses and not nscores:
return None, None, None
boxes = np.concatenate(nboxes)
classes = np.concatenate(nclasses)
scores = np.concatenate(nscores)
return boxes, classes, scores
def draw(image, boxes, scores, classes):
"""Draw the boxes on the image.
# Argument:
image: original image.
boxes: ndarray, boxes of objects.
classes: ndarray, classes of objects.
scores: ndarray, scores of objects.
all_classes: all classes name.
"""
for box, score, cl in zip(boxes, scores, classes):
top, left, right, bottom = box
print('class: {}, score: {}'.format(CLASSES[cl], score))
print('box coordinate left,top,right,down: [{}, {}, {}, {}]'.format(top, left, right, bottom))
top = int(top)
left = int(left)
right = int(right)
bottom = int(bottom)
cv2.rectangle(image, (top, left), (right, bottom), (255, 0, 0), 2)
cv2.putText(image, '{0} {1:.2f}'.format(CLASSES[cl], score),
(top, left + 10),
cv2.FONT_HERSHEY_SIMPLEX,
0.6, (0, 0, 255), 2)
def letterbox(im, new_shape=(640, 640), color=(0, 0, 0)):
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (dw, dh)
if __name__ == '__main__':
# Create RKNN object
rknn = RKNN(verbose=True)
# pre-process config
print('--> Config model')
rknn.config(mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]])
print('done')
# Load ONNX model
print('--> Loading model')
ret = rknn.load_onnx(model=ONNX_MODEL, outputs=['495', '515', '535'])
# ret = rknn.load_onnx(ONNX_MODEL)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET)
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# Export RKNN model
print('--> Export rknn model')
ret = rknn.export_rknn(RKNN_MODEL)
if ret != 0:
print('Export rknn model failed!')
exit(ret)
print('done')
# Init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime()
# ret = rknn.init_runtime('rk3566')
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
# Set inputs
img = cv2.imread(IMG_PATH)
# img, ratio, (dw, dh) = letterbox(img, new_shape=(IMG_SIZE, IMG_SIZE))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (IMG_SIZE, IMG_SIZE))
# Inference
print('--> Running model')
outputs = rknn.inference(inputs=[img])
# np.save('./onnx_yolov5_0.npy', outputs[0])
# np.save('./onnx_yolov5_1.npy', outputs[1])
# np.save('./onnx_yolov5_2.npy', outputs[2])
print('done')
# post process
input0_data = outputs[0]
input1_data = outputs[1]
input2_data = outputs[2]
input0_data = input0_data.reshape([3, -1] + list(input0_data.shape[-2:]))
input1_data = input1_data.reshape([3, -1] + list(input1_data.shape[-2:]))
input2_data = input2_data.reshape([3, -1] + list(input2_data.shape[-2:]))
input_data = list()
input_data.append(np.transpose(input0_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input1_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input2_data, (2, 3, 0, 1)))
boxes, classes, scores = yolov5_post_process(input_data)
img_1 = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
if boxes is not None:
draw(img_1, boxes, scores, classes)
# show output
cv2.imshow("post process result", img_1)
cv2.waitKey(0)
cv2.destroyAllWindows()
rknn.release()
到了这里,关于yolo v7 转rknn的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!