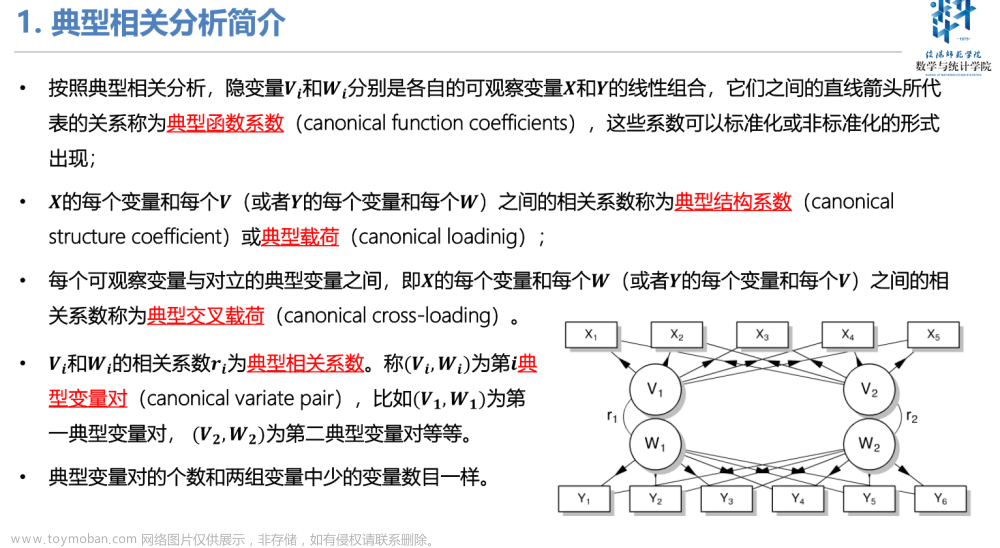
随着对CCA的深入研究,是时候对CCA进行一下总结了。
本菜鸡主要研究方向为故障诊断,故会带着从应用角度进行理解。

典型相关分析
基本原理
从字面意义上理解CCA,我们可以知道,简单说来就是对不同变量之间做相关分析。较为专业的说就是,一种度量两组变量之间相关程度的多元统计方法。
关于相似性度量距离问题,在这里有一篇Blog可以参考参考。
首先,从基本的入手。
当我们需要对两个变量 X , Y X,Y X,Y进行相关关系分析时,则常常会用到相关系数来反映。学过概率统计的小伙伴应该都知道的吧。还是解释一下。
相关系数:是一种用以反映变量之间相关关系密切程度的统计指标。相关系数是按积差方法计算,同样以两变量与各自平均值的离差为基础,通过两个离差相乘来反映两变量之间相关程度;着重研究线性的单相关系数。
R ( X , Y ) = Cov ( X , Y ) Var [ X ] Var [ Y ] R(X, Y)=\frac{\operatorname{Cov}(X, Y)}{\sqrt{\operatorname{Var}[X] \operatorname{Var}[Y]}} R(X,Y)=Var[X]Var[Y]Cov(X,Y)
其中, C o v ( X , Y ) Cov(X,Y) Cov(X,Y)表示 X , Y X,Y X,Y的协方差矩阵, V a r [ X ] Var[X] Var[X]为 X X X的方差, V a r [ Y ] Var[Y] Var[Y]为 Y Y Y的方差.
复习了一下大学本科概率统计知识,那么,如果我们需要分析的对象是两组或者多组向量,又该怎么做呢?
CCA的数学表达
这里举例两组变量
A
(
a
1
,
a
2
,
.
.
.
,
a
n
)
,
B
(
b
1
,
b
2
,
.
.
.
,
b
m
)
A(a_1,a_2,...,a_n),B(b_1,b_2,...,b_m)
A(a1,a2,...,an),B(b1,b2,...,bm),那么我们的公式会是这样:
R
(
X
i
,
Y
j
)
=
∑
i
=
1
,
j
=
1
n
,
m
C
o
v
(
X
i
,
Y
j
)
V
a
r
[
X
i
]
V
a
r
[
Y
j
]
R(X_i,Y_j)=\sum_{i=1,j=1}^{n,m} \frac{Cov(X_i,Y_j)}{\sqrt{Var[X_i]Var[Y_j]}}
R(Xi,Yj)=i=1,j=1∑n,mVar[Xi]Var[Yj]Cov(Xi,Yj)
我们会得到一个这样的矩阵:
[
R
(
X
1
,
Y
1
)
.
.
.
R
(
X
1
,
Y
m
−
1
)
R
(
X
1
,
Y
m
)
R
(
X
2
,
Y
1
)
.
.
.
R
(
X
2
,
Y
m
−
1
)
R
(
X
2
,
Y
m
)
.
.
.
.
.
.
.
.
.
.
.
.
R
(
X
n
,
Y
1
)
.
.
.
.
.
.
R
(
X
n
,
Y
m
)
]
\begin{bmatrix} R(X_1,Y_1) &... & R(X_1,Y_{m-1}) & R(X_1,Y_m)\\R(X_2,Y_1) & ...& R(X_2,Y_{m-1})& R(X_2,Y_m)\\ ...& ...& ...&... \\ R(X_n,Y_1) & ...& ...&R(X_n,Y_m) \end{bmatrix}
⎣⎢⎢⎡R(X1,Y1)R(X2,Y1)...R(Xn,Y1)............R(X1,Ym−1)R(X2,Ym−1)......R(X1,Ym)R(X2,Ym)...R(Xn,Ym)⎦⎥⎥⎤
这样的话,我们把每个变量的相关系数都求了出来,不知道会不会和我一样觉得这样很繁琐呢。如果我们能找到两组变量之间的各自的线性组合,那么我们就只分析讨论线性组合之间的相关分析。
典型相关系数:是先对原来各组变量进行主成分分析,得到新的线性关系的综合指标,再通过综合指标之间的线性相关系数来研究原各组变量间相关关系。
现在我们利用主成分分析(PCA)的思想,可以把多个变量与多个变量之间的相关转化成两个变量之间的相关。
先得到两组变量
(
A
T
,
B
T
)
(A^T,B^T)
(AT,BT)的协方差矩阵
Σ
=
[
Σ
11
Σ
12
Σ
21
Σ
22
]
\Sigma=\left[\begin{array}{l} \Sigma_{11} \ \Sigma_{12} \\ \Sigma_{21} \ \Sigma_{22} \end{array}\right]
Σ=[Σ11 Σ12Σ21 Σ22]
其中,
Σ
11
=
C
o
v
(
A
)
,
Σ
22
=
C
o
v
(
B
)
,
Σ
12
=
Σ
12
T
=
C
o
v
(
A
,
B
)
\Sigma_{11} = Cov(A),\Sigma_{22} = Cov(B),\Sigma_{12}=\Sigma_{12}^T = Cov(A,B)
Σ11=Cov(A),Σ22=Cov(B),Σ12=Σ12T=Cov(A,B).
把上面两组变量
A
(
a
1
,
a
2
,
.
.
.
,
a
n
)
,
B
(
b
1
,
b
2
,
.
.
.
,
b
m
)
A(a_1,a_2,...,a_n),B(b_1,b_2,...,b_m)
A(a1,a2,...,an),B(b1,b2,...,bm)分别组合成两个变量U、V,则用线性表示
U
=
t
1
a
1
+
t
2
a
2
+
.
.
.
+
t
n
a
n
,
V
=
h
1
b
1
+
h
2
b
2
+
.
.
.
+
h
m
b
m
\begin{matrix} U=t_1a_1+t_2a_2+...+t_na_n,\\ \\V=h_1b_1+h_2b_2+...+h_mb_m \end{matrix}
U=t1a1+t2a2+...+tnan,V=h1b1+h2b2+...+hmbm
然后,找出最大可能的相关系数 t k = ( t 1 , t 2 , . . . , t n ) T , h k = ( h 1 , h 2 , . . . , h m ) T {t_k}=(t_1,t_2,...,t_n)^T,{h_k}=(h_1,h_2,...,h_m)^T tk=(t1,t2,...,tn)T,hk=(h1,h2,...,hm)T,
使得, R ( U , V ) ⟶ M a x R(U,V)\longrightarrow Max R(U,V)⟶Max,这样,就得到了典型相关系数;而其中的 U , V U,V U,V 为典型相关变量。
典型相关分析最朴素的思想:首先分别在每组变量中找出第一对典型变量,使其具有最大相关性,然后在每组变量中找出第二对典型变量,使其分别与本组内的第一对典型变量不相关,第二对本身具有次大的相关性。如此下去,直到进行到K步,两组变量的相关系被提取完为止,可以得到K组变量。
So,
注意:此时的 ( U , V ) (U,V) (U,V)若不能反映两组变量之间的相关关系,我们需要继续构造下一组关系变量来表示,具体可构造 K K K对这样的关系
直到
R
(
U
,
V
)
⟶
M
a
x
R(U,V)\longrightarrow Max
R(U,V)⟶Max为止
U
k
=
t
k
T
A
=
t
1
k
a
1
+
t
2
k
a
2
+
.
.
.
+
t
n
k
a
n
V
k
=
h
k
T
B
=
h
1
k
b
1
+
h
2
k
b
2
+
.
.
.
+
h
m
k
b
m
\begin{matrix} U_k={t_k^T}{A}=t_{1k}a_1+t_{2k}a_2+...+t_{nk}a_n\\ \\ V_k={h_k^T}{B}=h_{1k}b_1+h_{2k}b_2+...+h_{mk}b_m \end{matrix}
Uk=tkTA=t1ka1+t2ka2+...+tnkanVk=hkTB=h1kb1+h2kb2+...+hmkbm
其中,我们需要一个约束条件满足,使得 R ( U , V ) ⟶ M a x R(U,V)\longrightarrow Max R(U,V)⟶Max
V
a
r
(
U
k
)
=
V
a
r
(
t
k
T
A
)
=
t
k
T
Σ
11
t
k
=
1
V
a
r
(
V
k
)
=
V
a
r
(
h
k
T
A
)
=
h
k
T
Σ
22
h
k
=
1
C
o
v
(
U
k
,
U
i
)
=
C
o
v
(
U
k
,
V
i
)
=
C
o
v
(
V
i
,
U
k
)
=
C
o
v
(
V
k
,
V
i
)
=
0
(
1
<
=
i
<
k
)
\begin{matrix} Var(U_k)=Var({t_k^T}{A})={t_k^T}\Sigma_{11}t_k=1\\ \\ Var(V_k)=Var({h_k^T}{A})={h_k^T}\Sigma_{22}h_k=1\\ \\ Cov(U_k,U_i)=Cov(U_k,V_i)=Cov(V_i,U_k)=Cov(V_k,V_i)=0(1<=i<k) \end{matrix}
Var(Uk)=Var(tkTA)=tkTΣ11tk=1Var(Vk)=Var(hkTA)=hkTΣ22hk=1Cov(Uk,Ui)=Cov(Uk,Vi)=Cov(Vi,Uk)=Cov(Vk,Vi)=0(1<=i<k)
典型相关系数公式
R
(
U
,
V
)
R_{(U,V)}
R(U,V)
R
(
U
,
V
)
=
Cov
(
U
,
V
)
Var
[
U
]
Var
[
V
]
=
C
o
v
(
U
,
V
)
=
t
k
T
C
o
v
(
A
,
B
)
h
k
=
t
k
T
Σ
12
h
k
R_{(U,V)}=\frac{\operatorname{Cov}(U, V)}{\sqrt{\operatorname{Var}[U] \operatorname{Var}[V]}}=Cov(U,V)={t_k}^TCov(A,B)h_k={t_k}^T\Sigma_{12} h_k
R(U,V)=Var[U]Var[V]Cov(U,V)=Cov(U,V)=tkTCov(A,B)hk=tkTΣ12hk
在此约束条件下, t k , h k t_k,h_k tk,hk系数得到最大,则使得 R ( U , V ) R_{(U,V)} R(U,V)最大。
典型相关系数及变量的求法
下面一起来求 t 1 , h 1 t_1,h_1 t1,h1(这里只例举第一典型相关系数)
(一起来复习高数–拉格朗日乘数法)
前提条件,我们有个计算公式,约束条件也有了,故这是一个求解条件极值题呀!!!
列出我们的拉格朗日函数:
ϕ
(
t
1
,
h
1
)
=
t
1
T
Σ
12
h
1
−
λ
2
(
t
1
T
Σ
11
t
1
−
1
)
−
v
2
(
h
1
T
Σ
22
h
1
−
1
)
\phi\left(t_{1}, h_{1}\right)=t_{1}^T \Sigma_{12} h_{1}-\frac{\lambda}{2}\left(t_{1}^T \Sigma_{11} t_{1}-1\right)-\frac{v}{2}\left(h_{1}^T \Sigma_{22} h_{1}-1\right)
ϕ(t1,h1)=t1TΣ12h1−2λ(t1TΣ11t1−1)−2v(h1TΣ22h1−1)
其中,
λ
,
v
\lambda,v
λ,v表示拉格朗日乘子参数。
由上述典型相关系数公式 R ( U , V ) R_{(U,V)} R(U,V)可知,我们只需求其系数 t 1 , h 1 t_1,h_1 t1,h1的最大值,即可
对
ϕ
(
t
1
,
h
1
)
\phi(t_1,h_1)
ϕ(t1,h1)做一阶偏导运算:
{
∂
ϕ
∂
t
1
=
∑
12
h
1
−
λ
∑
11
t
1
=
0
∂
ϕ
∂
h
1
=
∑
21
t
1
−
v
∑
22
h
1
=
0
\left\{\begin{array}{l} \frac{\partial \phi}{\partial t_{1}}=\sum_{12} h_{1}-\lambda \sum_{11} t_{1}=0 \\ \\ \frac{\partial \phi}{\partial h_{1}}=\sum_{21} t_{1}-v \sum_{22} h_{1}=0 \end{array}\right.
⎩⎨⎧∂t1∂ϕ=∑12h1−λ∑11t1=0∂h1∂ϕ=∑21t1−v∑22h1=0
也就是
{
∑
12
h
1
−
λ
∑
11
t
1
=
0
∑
21
t
1
−
v
∑
22
h
1
=
0
\left\{\begin{array}{l} \sum_{12} h_{1}-\lambda \sum_{11} t_{1}=0 \\ \\ \sum_{21} t_{1}-v \sum_{22} h_{1}=0 \end{array}\right.
⎩⎨⎧∑12h1−λ∑11t1=0∑21t1−v∑22h1=0
将上式分别左乘
t
1
,
h
1
t_1,h_1
t1,h1得,
{
t
1
Σ
12
h
1
−
λ
t
1
Σ
11
t
1
=
0
h
1
Σ
21
t
1
−
v
h
1
Σ
22
h
1
=
0
\left\{\begin{array}{l} \ t_{1}\Sigma_{12} h_{1}-\lambda t_{1}\Sigma_{11} t_{1}=0 \\ \\ \ h_{1}\Sigma_{21} t_{1}-v h_{1} \Sigma_{22} h_{1}=0 \end{array}\right.
⎩⎨⎧ t1Σ12h1−λt1Σ11t1=0 h1Σ21t1−vh1Σ22h1=0
由于约束条件可知
V
a
r
(
U
1
)
=
V
a
r
(
V
1
)
=
1
Var(U_1)=Var(V_1)=1
Var(U1)=Var(V1)=1,解得,
{
t
1
Σ
12
h
1
=
λ
h
1
Σ
21
t
1
=
v
\left\{\begin{array}{l} \ t_{1}\Sigma_{12} h_{1}=\lambda \\ \\ \ h_{1}\Sigma_{21} t_{1} =v \end{array}\right.
⎩⎨⎧ t1Σ12h1=λ h1Σ21t1=v
此时,我们来对比一下上面列出的求解
R
(
U
,
V
)
R_{(U,V)}
R(U,V)公式,有没有,是不是,一模一样,我们的拉格朗日乘子
λ
,
v
=
t
1
Σ
12
h
1
=
R
(
U
,
V
)
\lambda,v=t_{1}\Sigma_{12} h_{1}=R_{(U,V)}
λ,v=t1Σ12h1=R(U,V),也就是说,
λ
,
v
\lambda,v
λ,v即为我们要求解的典型相关系数。
我们由式
{
∑
12
h
1
−
λ
∑
11
t
1
=
0
∑
21
t
1
−
v
∑
22
h
1
=
0
\left\{\begin{array}{l} \sum_{12} h_{1}-\lambda \sum_{11} t_{1}=0 \\ \\ \sum_{21} t_{1}-v \sum_{22} h_{1}=0 \end{array}\right.
⎩⎨⎧∑12h1−λ∑11t1=0∑21t1−v∑22h1=0,可得
λ
t
1
=
Σ
11
−
1
Σ
12
h
1
\lambda t_1 = \Sigma _{11}^{-1}\Sigma_{12} h_{1}
λt1=Σ11−1Σ12h1
由于
λ
=
v
\lambda=v
λ=v,再将此代入
∑
21
t
1
−
v
∑
22
h
1
=
0
\sum_{21} t_{1}-v \sum_{22} h_{1}=0
∑21t1−v∑22h1=0中,可得
Σ
12
Σ
22
−
1
Σ
21
t
1
−
λ
2
Σ
11
t
1
=
0
Σ
11
−
1
Σ
12
Σ
22
−
1
Σ
21
t
1
−
λ
2
t
1
=
0
\begin{array}{l} \Sigma_{12} \Sigma_{22}^{-1} \Sigma_{21} t_{1}-\lambda^{2} \Sigma_{11} t_{1}=0 \\ \\ \Sigma_{11}^{-1} \Sigma_{12} \Sigma_{22}^{-1} \Sigma_{21} t_{1}-\lambda^{2} t_{1}=0 \end{array}
Σ12Σ22−1Σ21t1−λ2Σ11t1=0Σ11−1Σ12Σ22−1Σ21t1−λ2t1=0
上面的式子是不是很熟悉
A
X
=
λ
X
AX=\lambda X
AX=λX,
Σ
11
−
1
Σ
12
Σ
22
−
1
Σ
21
=
A
t
1
=
X
λ
=
λ
2
\Sigma_{11}^{-1} \Sigma_{12} \Sigma_{22}^{-1} \Sigma_{21} = A \\ t_1=X \\ \lambda=\lambda^2
Σ11−1Σ12Σ22−1Σ21=At1=Xλ=λ2
故,
Σ
11
−
1
Σ
12
Σ
22
−
1
Σ
21
\Sigma_{11}^{-1} \Sigma_{12} \Sigma_{22}^{-1} \Sigma_{21}
Σ11−1Σ12Σ22−1Σ21的特征值为
λ
2
\lambda^2
λ2,特征向量为
t
1
t_1
t1。
到此,我们可求得相应的 t 1 , h 1 t_1,h_1 t1,h1及 R ( U , V ) R_{(U,V)} R(U,V)。
典型相关分析应用
基于 CCA 的故障检测方法
对于CCA应用在故障检测中,基于 CCA 的故障检测方法可以视为基于 PCA 和基于 PLS 故障检测方法的一种扩展。
基本思想:是利用典型相关关系构建一个残差发生器, 通过对残差信号的评价做出故障检测的相应决策。该方法中提出了 4 个统计量, 将输入空间分为两个部分, 即与输出空间相关的子空间和与输出空间不相关的子空间;同理,将输出空间分为两个部分, 即与输入空间相关的子空间和与输入空间不相关的子空间。
设 u o b s ∈ R l u_{obs}∈R^l uobs∈Rl和 y o b s ∈ R m y_{obs}∈R^m yobs∈Rm表示测量的过程输入和输出向量, l l l和 m m m分别表示相应的数据维数。对两个向量进行去均值, 可得
u
=
u
o
b
s
−
μ
u
(1)
\boldsymbol{u} = \boldsymbol{u}_{\mathrm{obs}}-\boldsymbol{\mu}_{u} \tag{1}
u=uobs−μu(1)
y
=
y
o
b
s
−
μ
y
(2)
\boldsymbol{y} = \boldsymbol{y}_{\mathrm{obs}}-\boldsymbol{\mu}_{y} \tag{2}
y=yobs−μy(2)
式中:
μ
u
μ_u
μu和
μ
y
μ_y
μy分别表示输入变量均值和输出变量均值。假设采样得到 N 个过程数据, 并组成如下输入输出数据集
U
=
[
u
(
1
)
,
u
(
2
)
,
⋯
,
u
(
N
)
]
∈
R
l
×
N
,
Y
=
[
y
(
1
)
,
y
(
2
)
,
⋯
,
y
(
N
)
]
∈
R
m
×
N
\boldsymbol{U}=[\boldsymbol{u}(1), \boldsymbol{u}(2), \cdots, \boldsymbol{u}(N)] \in \mathbf{R}^{l \times N}, \boldsymbol{Y}=[\boldsymbol{y}(1), \boldsymbol{y}(2), \cdots, \boldsymbol{y}(N)] \in \mathbf{R}^{m \times N}
U=[u(1),u(2),⋯,u(N)]∈Rl×N,Y=[y(1),y(2),⋯,y(N)]∈Rm×N
式中:
u
(
i
)
,
y
(
i
)
,
(
i
=
1
,
…
,
N
)
u(i), y(i) , (i = 1, …, N)
u(i),y(i),(i=1,…,N)是按式(1)(2)中心化后的输入输出向量, 相应的平均值
μ
u
≈
1
N
∑
i
=
1
N
u
o
b
s
(
i
)
,
μ
y
≈
1
N
∑
i
=
1
N
y
o
b
s
(
i
)
,
\boldsymbol{\mu}_{u} \approx \frac{1}{N} \sum_{i=1}^{N} \boldsymbol{u}_{\mathrm{obs}}(i), \boldsymbol{\mu}_{y} \approx \frac{1}{N} \sum_{i=1}^{N} \boldsymbol{y}_{\mathrm{obs}}(i),
μu≈N1i=1∑Nuobs(i),μy≈N1i=1∑Nyobs(i),
并且, 协方差矩阵
Σ
u
、
Σ
y
Σ_u、 Σ_y
Σu、Σy和输入输出的互协方差矩阵
Σ
u
y
Σ_{uy}
Σuy分别为:
Σ
u
≈
1
N
−
1
∑
i
=
1
N
(
u
o
b
s
(
i
)
−
μ
u
)
(
u
o
b
s
(
i
)
−
μ
u
)
T
=
U
U
T
N
−
1
(3)
\boldsymbol{\Sigma}_{u} \approx \frac{1}{N-1} \sum_{i=1}^{N}\left(\boldsymbol{u}_{\mathrm{obs}}(i)-\boldsymbol{\mu}_{u}\right)\left(\boldsymbol{u}_{\mathrm{obs}}(i)-\boldsymbol{\mu}_{u}\right)^{\mathrm{T}}=\frac{\boldsymbol{U} \boldsymbol{U}^{\mathrm{T}}}{N-1}\tag{3}
Σu≈N−11i=1∑N(uobs(i)−μu)(uobs(i)−μu)T=N−1UUT(3)
Σ
y
≈
1
N
−
1
∑
i
=
1
N
(
y
o
b
s
(
i
)
−
μ
y
)
(
y
o
b
s
(
i
)
−
μ
y
)
T
=
Y
Y
T
N
−
1
(4)
\boldsymbol{\Sigma}_{y} \approx \frac{1}{N-1} \sum_{i=1}^{N}\left(\boldsymbol{y}_{\mathrm{obs}}(i)-\boldsymbol{\mu}_{y}\right)\left(\boldsymbol{y}_{\mathrm{obs}}(i)-\boldsymbol{\mu}_{y}\right)^{\mathrm{T}}=\frac{\boldsymbol{Y} \boldsymbol{Y}^{\mathrm{T}}}{N-1}\tag{4}
Σy≈N−11i=1∑N(yobs(i)−μy)(yobs(i)−μy)T=N−1YYT(4)
Σ
u
y
≈
1
N
−
1
∑
i
=
1
N
(
u
o
b
s
(
i
)
−
μ
u
)
(
y
o
b
s
(
i
)
−
μ
y
)
T
=
U
Y
T
N
−
1
(5)
\boldsymbol{\Sigma}_{u y} \approx \frac{1}{N-1} \sum_{i=1}^{N}\left(\boldsymbol{u}_{\mathrm{obs}}(i)-\boldsymbol{\mu}_{u}\right)\left(\boldsymbol{y}_{\mathrm{obs}}(i)-\boldsymbol{\mu}_{y}\right)^{\mathrm{T}}=\frac{\boldsymbol{U} \boldsymbol{Y}^{\mathrm{T}}}{N-1}\tag{5}
Σuy≈N−11i=1∑N(uobs(i)−μu)(yobs(i)−μy)T=N−1UYT(5)
结合 CCA 方法, 可得:
(
U
U
T
N
−
1
)
−
1
/
2
(
U
Y
T
N
−
1
)
(
Y
Y
T
N
−
1
)
−
1
/
2
=
Σ
u
−
1
/
2
Σ
u
y
Σ
y
−
1
/
2
=
Γ
s
Σ
Ψ
s
T
,
Σ
=
[
Λ
κ
0
0
0
]
(6)
\left(\frac{\boldsymbol{U} \boldsymbol{U}^{\mathrm{T}}}{N-1}\right)^{-1 / 2}\left(\frac{\boldsymbol{U} \boldsymbol{Y}^{\mathrm{T}}}{N-1}\right)\left(\frac{\boldsymbol{Y} \boldsymbol{Y}^{\mathrm{T}}}{N-1}\right)^{-1 / 2}=\boldsymbol{\Sigma}_{u}^{-1 / 2} \boldsymbol{\Sigma}_{u y} \boldsymbol{\Sigma}_{y}^{-1 / 2}=\boldsymbol{\Gamma}_{s} \boldsymbol{\Sigma} \boldsymbol{\Psi}_{s}^{\mathrm{T}}, \boldsymbol{\Sigma}=\left[\begin{array}{ll} \boldsymbol{\Lambda}_{\kappa} & 0 \\ 0 & 0 \end{array}\right]\tag{6}
(N−1UUT)−1/2(N−1UYT)(N−1YYT)−1/2=Σu−1/2ΣuyΣy−1/2=ΓsΣΨsT,Σ=[Λκ000](6)
式中: κ 为主元个数,
κ
≤
m
i
n
(
l
,
m
)
;
Σ
κ
=
d
i
a
g
(
ρ
1
,
…
,
ρ
κ
)
κ ≤ min(l,m); Σ_κ= diag(ρ1, …, ρκ)
κ≤min(l,m);Σκ=diag(ρ1,…,ρκ)为典型相关系数值。
令
J
s
=
Σ
u
−
1
/
2
Γ
(
:
,
1
:
κ
)
,
L
s
=
Σ
y
−
1
/
2
Ψ
(
:
,
1
:
κ
)
,
J
r
e
s
=
Σ
u
−
1
/
2
Γ
(
:
,
κ
+
1
:
l
)
,
L
r
e
s
=
Σ
y
−
1
/
2
Ψ
(
:
,
κ
+
1
:
m
)
\boldsymbol{J}_{s}=\boldsymbol{\Sigma}_{u}^{-1 / 2} \boldsymbol{\Gamma}(:, 1: \kappa), \boldsymbol{L}_{s}=\boldsymbol{\Sigma}_{y}^{-1 / 2} \boldsymbol{\Psi}(:, 1: \kappa), \boldsymbol{J}_{\mathrm{res}}=\boldsymbol{\Sigma}_{u}^{-1 / 2} \boldsymbol{\Gamma}(:, \kappa+1: l), \boldsymbol{L}_{\mathrm{res}}=\boldsymbol{\Sigma}_{y}^{-1 / 2} \boldsymbol{\Psi}(:, \kappa+1: m)
Js=Σu−1/2Γ(:,1:κ),Ls=Σy−1/2Ψ(:,1:κ),Jres=Σu−1/2Γ(:,κ+1:l),Lres=Σy−1/2Ψ(:,κ+1:m),
由 CCA 方法可知, J s T u J^T_su JsTu和 L s T y L^T_sy LsTy具有密切的相关性。
但是在实际系统中, 测量变量难免受到噪声影响, 两者之间的相关性可表示为:
L
s
T
y
(
k
)
=
Λ
κ
T
J
s
T
u
(
k
)
+
v
s
(
k
)
(7)
\boldsymbol{L}_{s}^{\mathrm{T}} \boldsymbol{y}(k)=\boldsymbol{\Lambda}_{\kappa}^{\mathrm{T}} \boldsymbol{J}_{s}^{\mathrm{T}} \boldsymbol{u}(k)+\boldsymbol{v}_{s}(k)\tag{7}
LsTy(k)=ΛκTJsTu(k)+vs(k)(7)
式中:
v
s
v_s
vs为噪声项, 并且与
J
s
T
u
J^T_su
JsTu弱相关。基于此, 残差向量
r
1
(
k
)
=
L
s
T
y
(
k
)
−
Λ
κ
T
J
s
T
u
(
k
)
(8)
\boldsymbol{r}_{1}(k)=\boldsymbol{L}_{s}^{\mathrm{T}} \boldsymbol{y}(k)-\boldsymbol{\Lambda}_{\kappa}^{\mathrm{T}} \boldsymbol{J}_{s}^{\mathrm{T}} \boldsymbol{u}(k)\tag{8}
r1(k)=LsTy(k)−ΛκTJsTu(k)(8)
其中的 Λ κ T {\Lambda}_{\kappa}^{\mathrm{T}} ΛκT为系数矩阵,上面介绍了CCA的数学运算,这里应该能理解,只不过多加了一个噪声向量。
假设输入输出数据服从高斯分布。已知线性变换不改变随机变量的分布, 所以残差信号
r
1
r_1
r1也服
从高斯分布, 其协方差矩阵:
Σ
r
1
=
1
N
−
1
(
L
s
T
Y
−
Λ
κ
T
J
s
T
U
)
(
L
s
T
Y
−
Λ
κ
T
J
s
T
U
)
T
=
I
κ
−
Λ
κ
2
N
−
1
(9)
\boldsymbol{\Sigma}_{r_1}=\frac{1}{N-1}\left(\boldsymbol{L}_{s}^{\mathrm{T}} \boldsymbol{Y}-\boldsymbol{\Lambda}_{\kappa}^{\mathrm{T}} \boldsymbol{J}_{s}^{\mathrm{T}} \boldsymbol{U}\right)\left(\boldsymbol{L}_{s}^{\mathrm{T}} \boldsymbol{Y}-\boldsymbol{\Lambda}_{\kappa}^{\mathrm{T}} \boldsymbol{J}_{s}^{\mathrm{T}} \boldsymbol{U}\right)^{\mathrm{T}}=\frac{\boldsymbol{I}_{\kappa}-\boldsymbol{\Lambda}_{\kappa}^{2}}{N-1}{ }^{}\tag{9}
Σr1=N−11(LsTY−ΛκTJsTU)(LsTY−ΛκTJsTU)T=N−1Iκ−Λκ2(9)
同理, 还可以得到另一残差向量
r
2
(
k
)
=
L
s
T
y
(
k
)
−
Λ
κ
T
J
s
T
u
(
k
)
(10)
\boldsymbol{r}_{2}(k)=\boldsymbol{L}_{s}^{\mathrm{T}} \boldsymbol{y}(k)-\boldsymbol{\Lambda}_{\kappa}^{\mathrm{T}} \boldsymbol{J}_{s}^{\mathrm{T}} \boldsymbol{u}(k)\tag{10}
r2(k)=LsTy(k)−ΛκTJsTu(k)(10)
其协方差矩阵
Σ
r
2
=
1
N
−
1
(
L
s
T
Y
−
Λ
κ
T
J
s
T
U
)
(
L
s
T
Y
−
Λ
κ
T
J
s
T
U
)
T
=
I
κ
−
Λ
κ
2
N
−
1
(11)
\boldsymbol{\Sigma}_{r_2}=\frac{1}{N-1}\left(\boldsymbol{L}_{s}^{\mathrm{T}} \boldsymbol{Y}-\boldsymbol{\Lambda}_{\kappa}^{\mathrm{T}} \boldsymbol{J}_{s}^{\mathrm{T}} \boldsymbol{U}\right)\left(\boldsymbol{L}_{s}^{\mathrm{T}} \boldsymbol{Y}-\boldsymbol{\Lambda}_{\kappa}^{\mathrm{T}} \boldsymbol{J}_{s}^{\mathrm{T}} \boldsymbol{U}\right)^{\mathrm{T}}=\frac{\boldsymbol{I}_{\kappa}-\boldsymbol{\Lambda}_{\kappa}^{2}}{N-1}{ }^{}\tag{11}
Σr2=N−11(LsTY−ΛκTJsTU)(LsTY−ΛκTJsTU)T=N−1Iκ−Λκ2(11)
由式(9)(11) 可以看出, 残差 r1和 r2的协方差相同。 对于故障检测, 可构造如下两个统计量:
T
1
2
(
k
)
=
(
N
−
1
)
r
1
T
(
k
)
(
I
κ
−
Λ
κ
2
)
−
1
r
1
(
k
)
(12)
T_{1}^{2}(k)=(N-1) \boldsymbol{r}_{1}^{\mathrm{T}}(k)\left(\boldsymbol{I}_{\kappa}-\boldsymbol{\Lambda}_{\kappa}^{2}\right)^{-1} \boldsymbol{r}_{1}(k)\tag{12}
T12(k)=(N−1)r1T(k)(Iκ−Λκ2)−1r1(k)(12)
T
2
2
(
k
)
=
(
N
−
1
)
r
2
T
(
k
)
(
I
κ
−
Λ
κ
2
)
−
1
r
2
(
k
)
(13)
T_{2}^{2}(k)=(N-1) \boldsymbol{r}_{2}^{\mathrm{T}}(k)\left(\boldsymbol{I}_{\kappa}-\boldsymbol{\Lambda}_{\kappa}^{2}\right)^{-1} \boldsymbol{r}_{2}(k)\tag{13}
T22(k)=(N−1)r2T(k)(Iκ−Λκ2)−1r2(k)(13)
注意到统计量
T
1
2
T^2_1
T12用于检测发生在输出子空间且输入相关的那部分故障, 为了检测与输入不相关的那部分故障, 可构造一个统计量
T
3
2
=
y
T
L
r
e
s
L
r
e
s
T
y
(14)
T_{3}^{2}=\boldsymbol{y}^{\mathrm{T}} \boldsymbol{L}_{\mathrm{res}} \boldsymbol{L}_{\mathrm{res}}^{\mathrm{T}} \boldsymbol{y}\tag{14}
T32=yTLresLresTy(14)
同理, 为了检测发生在输入空间且与输出不相关的那部分故障, 可构造另一统计量
T
4
2
=
u
T
L
r
e
s
L
r
e
s
T
u
(15)
T_{4}^{2}=\boldsymbol{u}^{\mathrm{T}} \boldsymbol{L}_{\mathrm{res}} \boldsymbol{L}_{\mathrm{res}}^{\mathrm{T}} \boldsymbol{u}\tag{15}
T42=uTLresLresTu(15)
由以上分析可知, 通过确定主元个数 κ, 可以得到4 个统计量
T
1
2
T^2_1
T12、
T
2
2
T^2_2
T22、
T
3
2
T^2_3
T32和
T
4
2
T^2_4
T42进行故障检测。
关于过程故障监控的统计量 T 2 T^2 T2,在深度学习、机器学习、故障诊断领域用的较多,这里可参考 T 2 T^2 T2的相关内容。
应用部分参考自一篇Paper ⟶ \longrightarrow ⟶[1]. CHEN Zhiw en,DING S X,ZHANG Kai,et al.Canonical correlation analysis- based fault detection methods with application to alumina evaporation process[J].Control Engineering Practice,2016,46:51- 58.
Python代码:
## 通过sklearn工具包内置的CCA实现
import numpy as np
from sklearn.cross_decomposition import CCA
from icecream import ic # ic用于显示,类似于print
A = [[3, 4, 5, 6, 7] for i in range(2000)]
B = [[8, 9, 10, 11, 12] for i in range(2000)]
# 注意在A、B中的数为输入变量及输出变量参数
# 建模
cca = CCA(n_components=1) # 若想计算第二主成分对应的相关系数,则令cca = CCA(n_components=2)
# 训练数据
cca.fit(X, Y)
# 降维操作
X_train_r, Y_train_r = cca.transform(X, Y)
#输出相关系数
ic(np.corrcoef(X_train_r[:, 0], Y_train_r[:, 0])[0, 1]) #如果想计算第二主成分对应的相关系数 print(np.corrcoef(X_train_r[:, 1], Y_train_r[:, 1])[0, 1])
另有一个包含可视化CCA的Python代码在 这里。
Matlab代码:
function[ccaEigvector1, ccaEigvector2] = CCA(data1, data2)
dataLen1 = size(data1, 2);
dataLen2 = size(data2, 2);
% Construct the scatter of each view and the scatter between them
data = [data1 data2];
covariance = cov(data);
% Sxx = covariance(1 : dataLen1, 1 : dataLen1) + eye(dataLen1) * 10^(-7);
Sxx = covariance(1 : dataLen1, 1 : dataLen1);
% Syy = covariance(dataLen1 + 1 : size(covariance, 2), dataLen1 + 1 : size(covariance, 2)) ...
% + eye(dataLen2) * 10^(-7);
Syy = covariance(dataLen1 + 1 : size(covariance, 2), dataLen1 + 1 : size(covariance, 2));
Sxy = covariance(1 : dataLen1, dataLen1 + 1 : size(covariance, 2));
% Syx = Sxy';
% using SVD to compute the projection
Hx = (Sxx)^(-1/2);
Hy = (Syy)^(-1/2);
H = Hx * Sxy * Hy;
[U, D, V] = svd(H, 'econ');
ccaEigvector1 = Hx * U;
ccaEigvector2 = Hy * V;
% make the canonical correlation variable has unit variance
ccaEigvector1 = ccaEigvector1 * diag(diag((eye(size(ccaEigvector1, 2)) ./ sqrt(ccaEigvector1' * Sxx * ccaEigvector1))));
ccaEigvector2 = ccaEigvector2 * diag(diag((eye(size(ccaEigvector2, 2)) ./ sqrt(ccaEigvector2' * Syy * ccaEigvector2))));
end
坚持读Paper,坚持做笔记!!!
To Be No.1
哈哈哈哈
过路能❤关注、收藏、点个赞❤三连就最好不过了
ღ( ´・ᴗ・` )
❤文章来源:https://www.toymoban.com/news/detail-400510.html
『
对自己的爱好保持热情,不要太功利!
』文章来源地址https://www.toymoban.com/news/detail-400510.html
到了这里,关于典型相关分析(Canonical Correlation Analysis,CCA)原理及Python、MATLAB实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!