Kafka 原理以及分区分配策略剖析
一、简介
Apache Kafka 是一个分布式的流处理平台(分布式的基于发布/订阅模式的消息队列【Message Queue】)。
流处理平台有以下3个特性:
可以让你发布和订阅流式的记录。这一方面与消息队列或者企业消息系统类似。
可以储存流式的记录,并且有较好的容错性。
可以在流式记录产生时就进行处理。
1.1 消息队列的两种模式
1.1.1 点对点模式
生产者将消息发送到queue中,然后消费者从queue中取出并且消费消息。消息被消费以后,queue中不再存储,所以消费者不可能消费到已经被消费的消息。Queue支持存在多个消费者,但是对一个消息而言,只能被一个消费者消费。

1.1.2 发布/订阅模式
生产者将消息发布到topic中,同时可以有多个消费者订阅该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。

1.2 Kafka 适合什么样的场景
它可以用于两大类别的应用:
构造实时流数据管道,它可以在系统或应用之间可靠地获取数据。(相当于message queue)。
构建实时流式应用程序,对这些流数据进行转换或者影响。(就是流处理,通过kafka stream topic和topic之间内部进行变化)。
为了理解Kafka是如何做到以上所说的功能,从下面开始,我们将深入探索Kafka的特性。
首先是一些概念:
Kafka作为一个集群,运行在一台或者多台服务器上。
Kafka 通过 topic 对存储的流数据进行分类。
每条记录中包含一个key,一个value和一个timestamp(时间戳)。
1.3 主题和分区
Kafka的消息通过主题(Topic)进行分类,就好比是数据库的表,或者是文件系统里的文件夹。主题可以被分为若干个分区(Partition),一个分区就是一个提交日志。消息以追加的方式写入分区,然后以先进先出的顺序读取。**注意,由于一个主题一般包含几个分区,因此无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序。**主题是逻辑上的概念,在物理上,一个主题是横跨多个服务器的。

**Kafka 集群保留所有发布的记录(无论他们是否已被消费),并通过一个可配置的参数——保留期限来控制(可以同时配置时间和消息大小,以较小的那个为准)。**举个例子, 如果保留策略设置为2天,一条记录发布后两天内,可以随时被消费,两天过后这条记录会被抛弃并释放磁盘空间。
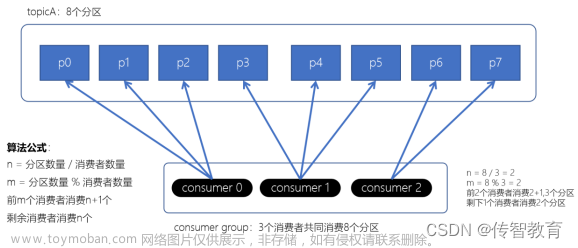
有时候我们需要增加分区的数量,比如为了扩展主题的容量、降低单个分区的吞吐量或者要在单个消费者组内运行更多的消费者(因为一个分区只能由消费者组里的一个消费者读取)。从消费者的角度来看,基于键的主题添加分区是很困难的,因为分区数量改变,键到分区的映射也会变化,所以对于基于键的主题来说,建议在一开始就设置好分区,避免以后对其进行调整。
(注意:不能减少分区的数量,因为如果删除了分区,分区里面的数据也一并删除了,导致数据不一致。如果一定要减少分区的数量,只能删除topic重建)
1.4 生产者和消费者
**生产者(发布者)**创建消息,一般情况下,一个消息会被发布到一个特定的主题上。生产者在默认情况下把消息均衡的分布到主题的所有分区上,而并不关心特定消息会被写入哪个分区。不过,生产者也可以把消息直接写到指定的分区。这通常通过消息键和分区器来实现,分区器为键生成一个散列值,并将其映射到指定的分区上。生产者也可以自定义分区器,根据不同的业务规则将消息映射到分区。
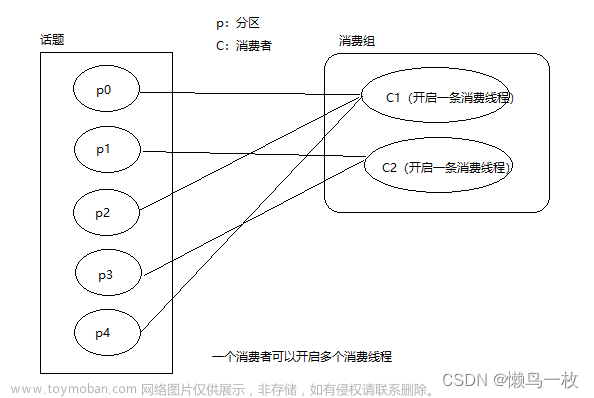
**消费者(订阅者)**读取消息,消费者可以订阅一个或者多个主题,并按照消息生成的顺序读取它们。消费者通过检查消息的偏移量来区分已经读取过的消息。偏移量是一种元数据,它是一个不断递增的整数值,在创建消息时,kafka会把它添加到消息里。在给定的分区里,每个消息的偏移量都是唯一的。消费者把每个分区最后读取的消息偏移量保存在zookeeper或者kafka上,如果消费者关闭或者重启,它的读取状态不会丢失。
消费者是消费者组的一部分,也就是说,会有一个或者多个消费共同读取一个主题。消费者组保证每个分区只能被同一个组内的一个消费者使用。如果一个消费者失效,群组里的其他消费者可以接管失效消费者的工作。

1.5 broker和集群
broker:一个独立的kafka服务器被称为broker。broker接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。broker为消费者提供服务,对读取分区的请求作出相应,返回已经提交到磁盘上的消息。
集群:交给同一个zookeeper集群来管理的broker节点就组成了kafka的集群。
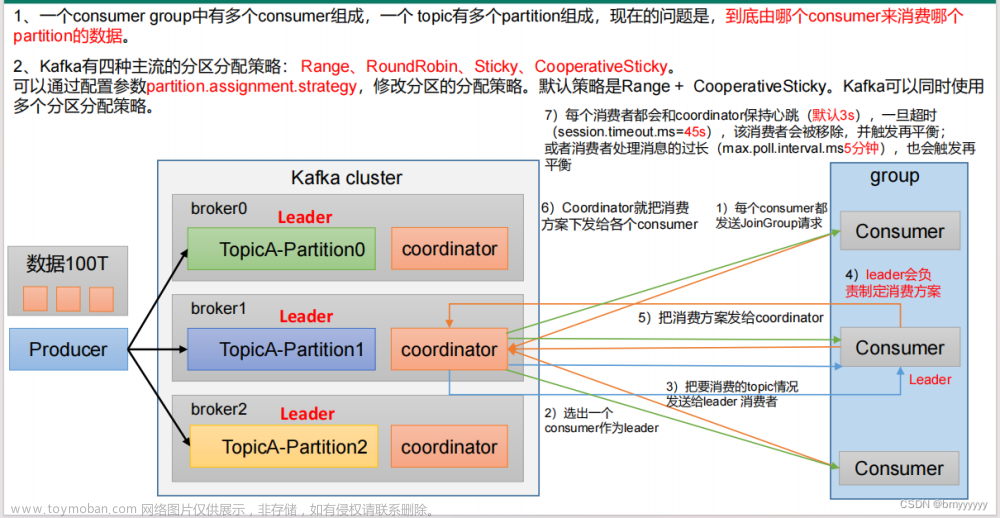
broker是集群的组成部分,每个集群都有一个broker同时充当集群控制器的角色。控制器负责管理工作,包括将分区分配给broker和监控broker。在broker中,一个分区从属于一个broker,该broker被称为分区的首领。一个分区可以分配给多个broker(Topic设置了多个副本的时候),这时会发生分区复制。如下图:

**broker如何处理请求:**broker会在它所监听的每个端口上运行一个Acceptor线程,这个线程会创建一个连接并把它交给Processor线程去处理。Processor线程(也叫网络线程)的数量是可配的,Processor线程负责从客户端获取请求信息,把它们放进请求队列,然后从响应队列获取响应信息,并发送给客户端。如下图所示:文章来源:https://www.toymoban.com/news/detail-400931.html
 <文章来源地址https://www.toymoban.com/news/detail-400931.html
<文章来源地址https://www.toymoban.com/news/detail-400931.html
到了这里,关于Kafka 原理以及分区分配策略剖析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!