OpenAI 3D 模型生成器Point-E极速体验
3090显卡,极速体验三维模型生成,体验地址:Gradio

文本生成图像的 AI 最近已经火到了圈外,不论是 DALL-E 2、DeepAI 还是 Stable Diffusion,人人都在调用 AI 算法搞绘画艺术,研究对 AI 讲的「咒语」。不断进化的技术推动了文生图生态的蓬勃发展,甚至还催生出了独角兽创业公司 Stability AI。
本周,OpenAI 开源的 3D 模型生成器 Point-E 引发了 AI 圈的新一轮热潮,Point-E 可以在单块 Nvidia V100 GPU 上在一到两分钟内生成 3D 模型。相比之下,现有系统(如谷歌的 DreamFusion)通常需要数小时和多块 GPU。
论文《Point-E: A System for Generating 3D Point Clouds from Complex Prompts》:
-
论文链接:https://arxiv.org/abs/2212.08751
-
项目链接:https://github.com/openai/point-e
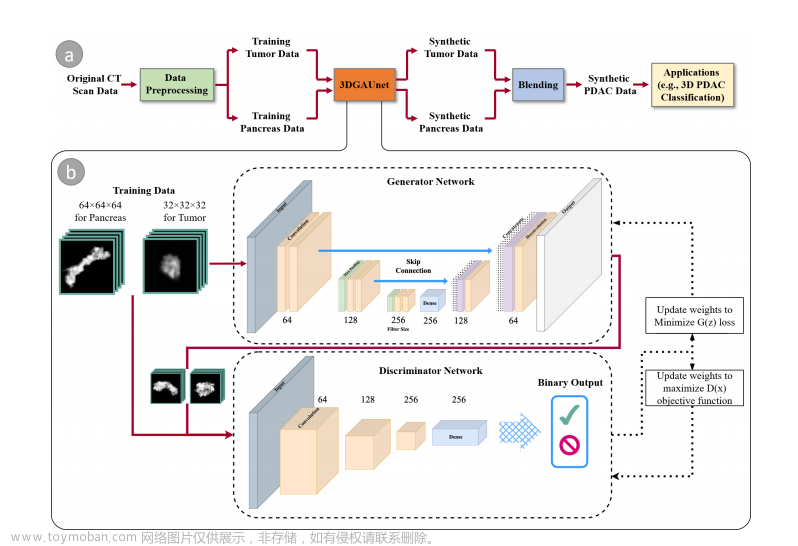
Point-E 不输出传统意义上的 3D 图像,它会生成点云,或空间中代表 3D 形状的离散数据点集。Point-E 中的 E 是「效率」的缩写,表示其比以前的 3D 对象生成方法更快。不过从计算的角度来看,点云更容易合成,但它们无法捕获对象的细粒度形状或纹理 ------ 这是目前 Point-E 的一个关键限制。
为了解决这一问题,OpenAI 团队训练了一个额外的人工智能系统来将 Point-E 的点云转换为网格。

Point-E 架构及运行原理
在独立的网格生成模型之外,Point-E 主要由两个模型组成:文本到图像模型和图像到 3D 模型。文本到图像模型类似于 OpenAI 自家的 DALL-E 2 和 Stable Diffusion 等生成模型系统,在标记图像上进行训练以理解单词和视觉概念之间的关联。在图像生成之后,图像到 3D 模型被输入一组与 3D 对象配对的图像,训练出在两者之间有效转换的能力。

Point-E 通过 30 亿参数的 GLIDE 模型生成综合视图渲染,内容被馈送到图像到 3D 模型,通过一系列扩散模型运行生成的图像,以创建初始图像的 3D RGB 点云 ------ 先生成粗略的 1024 点云模型,然后生成更精细的 4096 点云模型。

Point-E 的点云扩散模型架构。图像通过一个冻结的、预训练的 CLIP 模型输入,输出网格作为标记输入到 transformer 中
OpenAI 研究人员表示,在经过「数百万 3D 对象和相关元数据的数据集上训练模型后,Point-E 拥有了生成匹配文本提示的彩色点云的能力。Point-E 的问题和目前的生成模型一样,图像到 3D 转换过程中有时无法理解文本叙述的内容,导致生成的形状与文本提示不匹配。尽管如此,根据 OpenAI 团队的说法,它仍然比以前的最先进技术快几个数量级。

Point-E将点云转换为网格
OpenAI 在论文中表示,「虽然 Point-E 在评估中表现得比 SOTA 方法差,但它只用了后者一小部分的时间就可以生成样本。这使得 Point-E 对某些应用程序更实用,或者可以利用效率获得更高质量的 3D 对象。」
AI绘图在线体验
除了Point-E,还可以体验最新Stable diffusion-v2绘画模型,免注册,免安装,不用显卡,在线体验,有网就行!
二次元绘图
在线体验地址:Stable Diffusion
模型包括:
-
NovelAI,NovelAI的模型训练使用了数千个网站的数十亿张图片,包括 Pixiv、Twitter、DeviantArt、Tumblr等网站的作品。
-
Waifu,waifu的模型可用于生成二次元的卡通形象,可以生成独有的二次元动漫小姐姐和主人公
-
Stable diffusion-v2,以英文为输入的通用图像生成模型
中文输入绘图
在线体验地址:Stable Diffusion
-
太乙模型,首个开源的中文Stable Diffusion模型,基于0.2亿筛选过的中文图文对训练。文章来源:https://www.toymoban.com/news/detail-401061.html
 文章来源地址https://www.toymoban.com/news/detail-401061.html
文章来源地址https://www.toymoban.com/news/detail-401061.html
到了这里,关于OpenAI 3D 模型生成器Point-E极速体验的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!