什么是flink cdc?
cdc github源码地址
cdc官方文档
对很多初入门的人来说是无法理解cdc到底是什么个东西。 有这样一个需求,比如在mysql数据库中存在很多数据,但是公司要把mysql中的数据同步到数据仓库(starrocks), 数据仓库你可以理解为存储了各种各样来自不同数据库中表。
数据的同步目前对mysql来说比较常见是方式是使用:datax 和 canal配合, 为什么需要这两个框架配合呢?
因为datax不支持实时的同步, datax只能定义一个范围去同步,而且同步结束后程序就结束了。但是我想要的是数据仓库中的数据近乎实时的和mysql中的数据保持一致又该怎么办? 答案是再加上canal, canal和datax相反,它只支持指定一个binlog同步,然后会一直同步到现在,并且程序不会结束,会一直同步。 这样datax+canal就可以达到实时同步的功能。
这是业界比较常用的同步方式,datax同步历史数据,canal+kafka同步最新的数据,而且还要有一个程序去读取kafka中的binlog json数据(可以用flink或者spark又或者是flume)。可以看到这个链路比较长,不是很好。
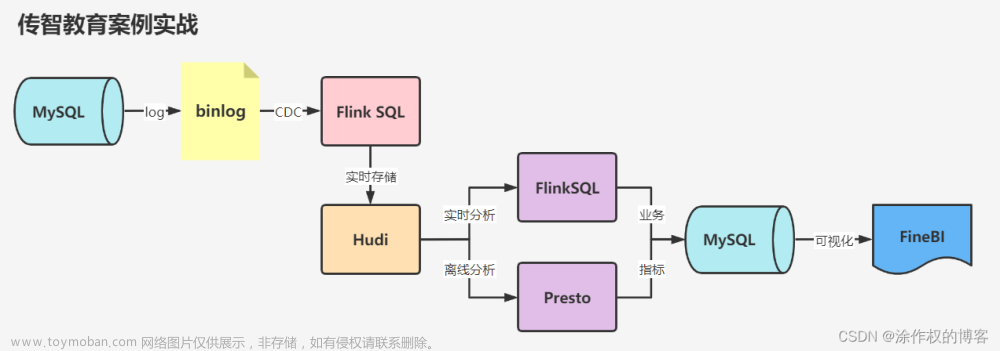
下面是目前常见的cdc同步方案以及对比: 文章来源:https://www.toymoban.com/news/detail-401109.html
文章来源:https://www.toymoban.com/news/detail-401109.html
-
DataX 不支持增量同步,Canal 不支持全量同步。虽然两者都是非常流行的数据同步工具,但
在场景支持上仍不完善。 - 在全量+增量一体化同步方面,只有 Flink CDC、Debezium、Oracle Goldengate 支持较好。
- 在架构方面,Apache Flink 是一个非常优秀的分布式流处理框架,因此 Flink CDC 作为
Apache Flink 的一个组件具有非常灵活的水平扩展能力。而 DataX 和 Canal 是个单机架构,
在大数据场景下容易面临性能瓶颈的问题。 - 在数据加工的能力上,CDC 工具是否能够方便地对数据做一些清洗、过滤、聚合,甚至关联打
宽? Flink CDC 依托强大的 Flink SQL 流式计算能力,可以非常方便地对数据进行加工。而
Debezium 等则需要通过复杂的 Java 代码才能完成,使用门槛比较高。 - 另外,在生态方面,这里指的是上下游存储的支持。Flink CDC 上下游非常丰富,支持对接
MySQL、PostgreSQL 等数据源,还支持写入到 TiDB、HBase、Kafka、Hudi 等各种存储系统
中,也支持灵活的自定义 connector。 - 我们看到flink cdc 是比较友好的方案, 其内部实现上用的是Debezium去采集binlong, 而且可通过参数scan.startup.mode 来控制同步行为:
- initial (默认):在第一次启动时对受监视的数据库表执行全量同步,并继续读取最新的 binlog。
- earliest-offset:跳过快照阶段,从可读取的最早 binlog 位点开始读取
- latest-offset:首次启动时,从不对受监视的数据库表执行快照, 连接器仅从 binlog 的结尾处开始读取,这意味着连接器只能读取在连接器启动之后的数据更改。
- specific-offset:跳过快照阶段,从指定的 binlog 位点开始读取。位点可通过 binlog 文件名和位置指定,或者在 GTID 在集群上启用时通过 GTID 集合指定。
- timestamp:跳过快照阶段,从指定的时间戳开始读取 binlog 事件。
一个demo
对flink_01 和flink_02 进行两个分表进行同步合并到:flink_merge文章来源地址https://www.toymoban.com/news/detail-401109.html
CREATE TABLE `flink_01` (
`indicator_name` varchar(255) DEFAULT NULL COMMENT '指标名称',
`indicator_value` varchar(255) DEFAULT NULL COMMENT '指标值',
`indicator_code` int NOT NULL COMMENT '指标编码',
`table_name` varchar(255) NOT NULL COMMENT '指标计算上游表名',
`window_start` datetime NOT NULL COMMENT '窗口开始时间',
`window_end` datetime DEFAULT NULL COMMENT '窗口截止时间',
`create_time` datetime DEFAULT NULL COMMENT '创建更新时间',
`indicator_description` varchar(255) DEFAULT NULL COMMENT '指标描述',
PRIMARY KEY (`indicator_code`,`table_name`,`window_start`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `test`.`flink_01`(`indicator_name`, `indicator_value`, `indicator_code`, `table_name`, `window_start`, `window_end`, `create_time`, `indicator_description`) VALUES ('all_login_num', '52', 0, 'app_login_log', '2022-12-14 00:00:00', '2022-12-15 00:00:00', '2022-12-19 18:09:24', '登录用户数');
INSERT INTO `test`.`flink_01`(`indicator_name`, `indicator_value`, `indicator_code`, `table_name`, `window_start`, `window_end`, `create_time`, `indicator_description`) VALUES ('all_login_num', '49', 0, 'app_login_log', '2022-12-15 00:00:00', '2022-12-16 00:00:00', '2022-12-19 18:09:24', '登录用户数');
INSERT INTO `test`.`flink_01`(`indicator_name`, `indicator_value`, `indicator_code`, `table_name`, `window_start`, `window_end`, `create_time`, `indicator_description`) VALUES ('all_login_num', '62到了这里,关于【实战-01】flink cdc 实时数据同步利器的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!