CVPR2023论文最新速递!含分割/VIT/点云等多个方向
2023 年 2 月 28 日凌晨,CVPR 2023 顶会论文接收结果出炉!
CVPR 2023 收录的工作中 " 扩散模型、多模态、预训练、MAE " 相关工作的数量会显著增长。
语义分割/Segmentation - 3 篇
Delivering Arbitrary-Modal Semantic Segmentation
论文/Paper: http://arxiv.org/pdf/2303.01480
代码/Code: None
Conflict-Based Cross-View Consistency for Semi-Supervised Semantic Segmentation
论文/Paper: http://arxiv.org/pdf/2303.01276
代码/Code: https://github.com/xiaoyao3302/CCVC
Token Contrast for Weakly-Supervised Semantic Segmentation
论文/Paper: http://arxiv.org/pdf/2303.01267
代码/Code: https://github.com/rulixiang/toco
超分/Super-Resolution - 1 篇
OPE-SR: Orthogonal Position Encoding for Designing a Parameter-free Upsampling Module in Arbitrary-scale Image Super-Resolution
论文/Paper: http://arxiv.org/pdf/2303.01091
代码/Code: None
Transformers - - 2 篇
Visual Atoms: Pre-training Vision Transformers with Sinusoidal Waves
论文/Paper: http://arxiv.org/pdf/2303.01112
代码/Code: None
AMIGO: Sparse Multi-Modal Graph Transformer with Shared-Context Processing for Representation Learning of Giga-pixel Images
论文/Paper: http://arxiv.org/pdf/2303.00865
代码/Code: None
点云/Point Clouds - 1 篇
Neural Intrinsic Embedding for Non-rigid Point Cloud Matching
论文/Paper: http://arxiv.org/pdf/2303.01038
代码/Code: None
其他/Other - 8 篇
Zero-Shot Text-to-Parameter Translation for Game Character Auto-Creation
论文/Paper: http://arxiv.org/pdf/2303.01311
代码/Code: None
MixPHM: Redundancy-Aware Parameter-Efficient Tuning for Low-Resource Visual Question Answering
论文/Paper: http://arxiv.org/pdf/2303.01239
代码/Code: https://github.com/jingjing12110/MixPHM
Disentangling Orthogonal Planes for Indoor Panoramic Room Layout Estimation with Cross-Scale Distortion Awareness
论文/Paper: http://arxiv.org/pdf/2303.00971
代码/Code: https://github.com/zhijieshen-bjtu/dopnet
Neuro-Modulated Hebbian Learning for Fully Test-Time Adaptation
论文/Paper: http://arxiv.org/pdf/2303.00914
代码/Code: None
Towards Trustable Skin Cancer Diagnosis via Rewriting Model’s Decision
论文/Paper: http://arxiv.org/pdf/2303.00885
代码/Code: None
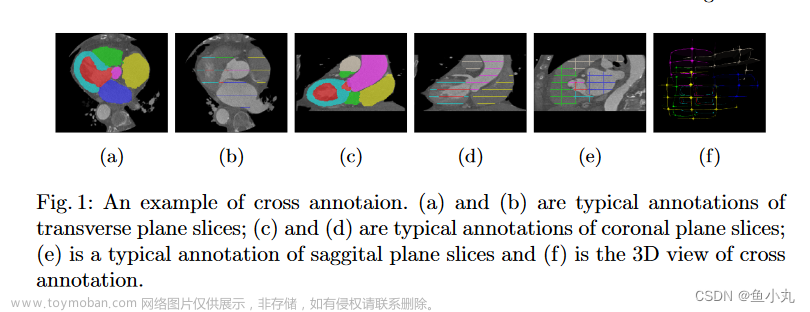
Geometric Visual Similarity Learning in 3D Medical Image Self-supervised Pre-training
论文/Paper: http://arxiv.org/pdf/2303.00874
代码/Code: https://github.com/yutinghe-list/gvsl
Demystifying Causal Features on Adversarial Examples and Causal Inoculation for Robust Network by Adversarial Instrumental Variable Regression
论文/Paper: http://arxiv.org/pdf/2303.01052
代码/Code: None文章来源:https://www.toymoban.com/news/detail-401245.html
UniDexGrasp: Universal Robotic Dexterous Grasping via Learning Diverse Proposal Generation and Goal-Conditioned Policy
论文/Paper: https://arxiv.org/abs/2303.00938
代码/Code: None文章来源地址https://www.toymoban.com/news/detail-401245.html
下载1:人工资料大礼包
在「阿远学长」公众号后台回复:【1】
即可领取一份人工资料大礼包
包含机器学习、深度学习书籍pdf
各大人工智能项目实战、大厂面试宝典等
下载2:人工智能实战项目
在「阿远」公众号菜单栏点击:【实战项目】
即可手把手复现人工智能实战项目
到了这里,关于CVPR2023最新论文 (含语义分割、扩散模型、多模态、预训练、MAE等方向)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!