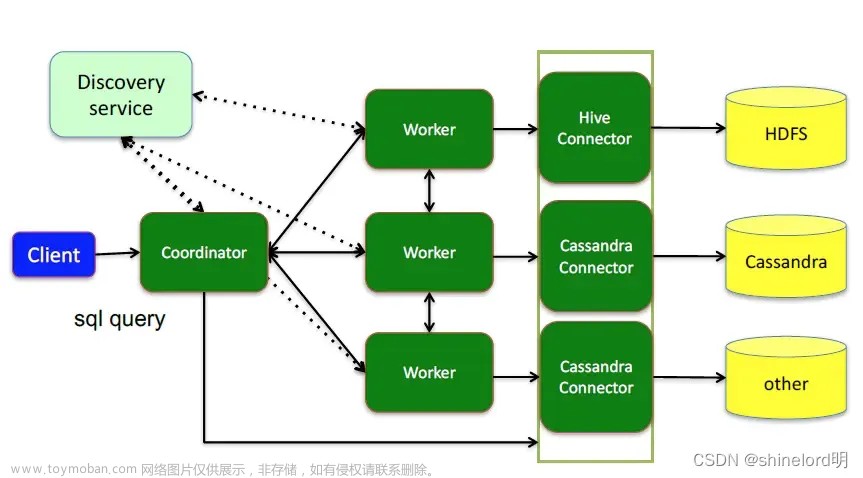
1、查询引擎
Phoenix:
Salesforce公司出品,Apache HBase之上的一个SQL中间层,完全使用Java编写
Stinger:
原叫Tez,下一代Hive, Hortonworks主导开发,运行在YARN上的DAG计算框架
Presto:
Facebook开源
Spark SQL:
Spark上的SQL执行引擎
Pig:
基于Hadoop MapReduce的脚本语言
Cloudera Impala:
参照Google Dremel实现,能运行在HDFS或HBase上,使用C++开发
Apache Drill:
参照Google Dremel实现
Apache Tajo:
一个运行在YARN上支持SQL的分布式数据仓库
Hive:
基于Hadoop MapReduce的SQL查询引擎
2、流式计算
Facebook Puma:
实时数据流分析
Twitter Rainbird:
分布式实时统计系统,如网站的点击统计
Yahoo S4:
Java开发的一个通用的、分布式的、可扩展的、分区容错的、可插拔的无主架构的流式系统
Twitter Storm:
使用Java和Clojure实现
Samza:
samza是一个分布式的流式数据处理框架(streaming processing),它是基于Kafka消息队列来实现类实时的流式数据处理的。(准确的说,samza是通过模块化的形式来使用kafka的,因此可以构架在其他消息队列框架上,但出发点和默认实现是基于kafka)
DataTorrent:
基于Hadoop2.X构建的实时流式处理和分析平台,每秒可以处理超过10亿个实时事件
Spark Streaming:
Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。
Apache Flink:
Apache Flink是一个高效、分布式、基于Java实现的通用大数据分析引擎,它具有分布式 MapReduce一类平台的高效性、灵活性和扩展性以及并行数据库查询优化方案,它支持批量和基于流的数据分析,且提供了基于Java和Scala的API。
3、迭代计算
Apache Hama:
建立在Hadoop上基于BSP(Bulk Synchronous Parallel)的计算框架,模仿了Google的Pregel。
Apache Giraph:
建立在Hadoop上的可伸缩的分布式迭代图处理系统,灵感来自BSP(bulk synchronous parallel)和Google的Pregel
HaLoop:
迭代的MapReduce
Twister:
迭代的MapReduce
Spark GraphX:
GraphX是 Spark中用于图(e.g., Web-Graphs and Social Networks)和图并行计算(e.g., PageRank and Collaborative Filtering)的API,可以认为是GraphLab(C++)和Pregel(C++)在Spark(Scala)上的重写及优化,
4、离线计算
Hadoop MapReduce:
经典的大数据批处理系统
Berkeley Spark:
使用Scala语言实现,和MapReduce有较大的竞争关系,性能强于MapReduce
Apache Flink:
Apache Flink是一个高效、分布式、基于Java实现的通用大数据分析引擎,它具有分布式 MapReduce一类平台的高效性、灵活性和扩展性以及并行数据库查询优化方案,它支持批量和基于流的数据分析,且提供了基于Java和Scala的API。
5、键值存储
LevelDB
LevelDB Facebook开源的,基于Google的LevelDB,但提高了扩展性可以运行在多核处理器上
HyperDex:
下一代KV存储系统,支持strings、integers、floats、lists、maps和sets等丰富的数据类型
TokyoCabinet:
日本人Mikio Hirabayashi(平林干雄)开发的一款DBM数据库,注意它只是个库(大名鼎鼎的DBM数据库qdbm就是Mikio Hirabayashi开发的),读写非常快
Voldemort:
一个分布式键值存储系统,是Amazon Dynamo的一个开源克隆,LinkedIn开源
Amazon Dynamo:
亚马逊的KV模式的存储平台,无主架构
Tair:
淘宝出品的高性能、分布式、可扩展、高可靠的KV结构存储系统,专为小文件优化,并提供简单易用的接口(类似Map),Tair支持Java和C版本的客户端
Apache Accumulo:
一个可靠的、可伸缩的、高性能的排序分布式的KV存储系统,参照Google Bigtable而设计,建立在Hadoop、Thrift和Zookeeper之上。
Redis:
使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、单机版KV数据库。从2010年3月15日起,Redis的开发工作由VMware主持
Memcached:
Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。Memcached基于一个存储键/值对的hashmap。其守护进程(daemon)是用C写的,但是客户端可以用任何语言来编写,并通过Memcached协议与守护进程通信。
OceanBase:
支持海量数据的高性能分布式数据库系统,实现了数千亿条记录、数百TB数据上的跨行跨表事务
Amazon SimpleDB:
一个可大规模伸缩、用 Erlang 编写的高可用数据存储
Vertica:
惠普2011收购Vertica,Vertica是传统的关系型数据库,基于列存储,同时支持MPP,使用标准的SQL查询,可以和Hadoop/MapReduce进行集成
Cassandra:
Hadoop成员,Facebook于2008将Cassandra开源,基于O(1)DHT的完全P2P架构
HyperTable:
搜索引擎公司Zvents针对Bigtable的C++开源实现
FoundationDB:
支持ACID事务处理的NoSQL数据库,提供非常好的性能、数据一致性和操作弹性
HBase:
Bigtable在Hadoop中的实现,最初是Powerset公司为了处理自然语言搜索产生的海量数据而开展的项目
6、文件存储
CouchDB:
面向文档的数据存储
MongoDB:
文档数据库
Tachyon:
加州大学伯克利分校的AMPLab基于Hadoop的核心组件开发出一个更快的版本Tachyon,它从底层重构了Hadoop平台。
KFS:
GFS的C++开源版本
HDFS:
GFS在Hadoop中的实现
7、资源管理
Twitter Mesos:
Google Borg的翻版
Hadoop Yarn:
类似于Mesos
8、日志收集系统
Facebook Scribe:
Facebook开源的日志收集系统,能够从各种日志源上收集日志,存储到一个中央存储系统(可以是NFS,分布式文件系统等)上,以便于进行集中统计分析处理,常与Hadoop结合使用,Scribe用于向HDFS中Push日志
Cloudera Flume:
Cloudera提供的日志收集系统,支持对日志的实时性收集
Logstash:
日志管理、分析和传输工具,可配合kibana、ElasticSearch组建成日志查询系统
Fluentd:
Fluentd是一个日志收集系统,它的特点在于其各部分均是可定制化的,你可以通过简单的配置,将日志收集到不同的地方。开源社区已经贡献了下面一些存储插件:MongoDB, Redis, CouchDB,Amazon S3, Amazon SQS, Scribe, 0MQ, AMQP, Delayed, Growl 等等。
Kibana:
为日志提供友好的Web查询页面
9、消息系统
ZeroMQ:
很底层的高性能网络库
RabbitMQ:
在AMQP基础上完整的,可复用的企业消息系统
Apache ActiveMQ:
能力强劲的开源消息总线
Jafka:
开源的、高性能的、跨语言分布式消息系统,最早是由Apache孵化的Kafka(由LinkedIn捐助给Apache)克隆而来
Apache Kafka:
Linkedin于2010年12月份开源的分布式消息系统,它主要用于处理活跃的流式数据,由Scala写成
10、分布式服务
ZooKeeper:
分布式锁服务,PoxOS算法的实现,对应Google的Chubby
RPC:
Apache Avro,Hadoop中的RPC
Facebook Thrift:
RPC,支持C++/Java/PHP等众多语言
11、集群管理
Nagios:
监视系统运行状态和网络信息的监视系统
Ganglia:
UC Berkeley发起的一个开源集群监视项目,设计用于测量数以千计的节点。
Apache Ambari:
Hadoop成员,管理和监视Apache Hadoop集群的开源框架
12、基础设施
LevelDB:
Google顶级大牛开发的单机版键值数据库,具有非常高的写性能
SSTable:
源于Google,orted String Table
RecordIO:
源于Google
Flat Buffers:
针对游戏开发的,高效的跨平台序列化库,相比Proto Buffers开销更小,因为Flat Buffers没有解析过程
Protocol Buffers:
Google公司开发的一种数据描述语言,类似于XML能够将结构化数据序列化,可用于数据存储、通信协议等方面。它不依赖于语言和平台并且可扩展性极强。
Consistent Hashing:
1997年由麻省理工学院提出,目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似,基本解决了在P2P环境中最为关键的问题——如何在动态的网络拓扑中分布存储和路由。
Netty:
JBOSS提供的一个Java开源框架,提供异步的、事件驱动的网络应用程序框架,用以快速开发高性能、高可靠性的网络服务器和客户端程序。
BloomFilter:
布隆过滤器,1970年由布隆提出,是一个很长的二进制矢量和一系列随机映射函数,可以用于检索一个元素是否在一个集合中,优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
13、搜索引擎
Nutch:
开源Java 实现的搜索引擎,诞生Hadoop的地方。
Lucene:
一套信息检索工具包,但并不包含搜索引擎系统,它包含了索引结构、读写索引工具、相关性工具、排序等功能。
SolrCloud:
基于Solr和Zookeeper的分布式搜索,Solr4.0的核心组件之一,主要思想是使用Zookeeper作为集群的配置信息中心
Solr:
Solr是基于Lucene的搜索。
ElasticSearch:
开源的(Apache2协议),分布式的,RESTful的,构建在Apache Lucene之上的的搜索引擎。
Sphinx:
一个基于SQL的全文检索引擎,可结合MySQL、PostgreSQL做全文检索,可提供比数据库本身更专业的搜索功能,单一索引可达1亿条记录,1000万条记录情况下的查询速度为毫秒级。
SenseiDB:
Linkin公司开发的一个开源分布式实时半结构化数据库,在全文索引的基础封装了Browse Query Language (BQL,类似SQL)的查询语法。
14、数据挖掘
Mahout:
Hadoop成员,目标是建立一个可扩展的机器学习库
Spark MLlib:
Spark成员,可扩展机器学习库
Iaas
OpenStack:
美国国家航空航天局和Rackspace合作研发的,以Apache许可证授权云平台管理的项目,它不是一个软件。这个项目由几个主要的组件组合起来完成一些具体的工作,旨在为公共及私有云的建设与管理提供软件的开源项目。6个核心项目:Nova(计算,Compute),Swift(对象存储,Object),Glance(镜像,Image),Keystone(身份,Identity),Horizon(自助门户,Dashboard),Quantum & Melange(网络&地址管理),另外还有若干社区项目,如Rackspace(负载均衡)、Rackspace(关系型数据库)。
Docker:
应用容器引擎,让开发者可打包应用及依赖包到一个可移植的容器中,然后发布到Linux机器上,也可实现虚拟化。
Kubernetes:
Google开源的容器集群管理系统
Imctfy:
Google开源的Linux容器
CloudStack:
CloudStack是一个开源的具有高可用性及扩展性的云计算平台。支持管理大部分主流的hypervisor,如KVM虚拟机,XenServer,VMware,Oracle VM,Xen等。
15、监控管理
Dapper:
Google生产环境下的大规模分布式系统的跟踪系统文章来源:https://www.toymoban.com/news/detail-401411.html
Zipkin:
Twitter开源的参考Google Dapper而开发,使用Apache Cassandra做为数据存储系统文章来源地址https://www.toymoban.com/news/detail-401411.html
到了这里,关于开源大数据工具整理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!