在之前,我们想要存储一个数据的时候可以创建变量,例如存储一个整形的变量,我们使用int类型的变量来存储,那么如果存储一组相同类型的数据呢?这时我们就引入了数组的概念。
目录
一、一维数组的创建和初始化
1.1数组的创建
1.2 数组的初始化
1.3 一维数组的使用
1.4 一维数组在内存中的存储
二、二维数组的创建和初始化
2.1 二维数组的创建
2.2 二维数组的初始化
2.3 二维数组的使用
2.4 二维数组在内存中的存储
三、数组越界
四、数组作为函数参数
4.1 冒泡排序函数的错误设计
4.2 冒泡排序函数的正确设计
4.3 数组名是什么
一、一维数组的创建和初始化
1.1数组的创建
数组是一组相同类型元素的集合。
数组的创建方式:
type_t arr_name[const_n];
//type_t 是指数组的元素类型
// //arr_name 是数组名
//const_n 是一个常量表达式,用来指定数组的大小例如我们想要存储10个int类型的数据,这时我们就可以创建一个数组来存储,即:int arr[10];
在这里我们需要注意:
数组创建,在C99标准之前,[ ]中要给一个常量才可以,不能使用变量,但是在C99中引入了变长数组的概念,变长数组支持数组的大小使用变量来指定,(变长数组不是数组的长度可以变化)。注意:变长数组不能初始化。
数组创建的例子:
int arr[10];
char arr1[10];
float arr3[1];
double arr4[10];1.2 数组的初始化
数组的初始化是指,在创建数组的同时给数组的内容一些合理初始值(初始化)。
例如:
int arr[10] = { 1 }; //这种初始化方式是不完全初始化,指第一个元素初始化为1,其余的元 素默认初始化为0.
char arr1[3] = { 'a', 98, 'c' }; //将数组的第一个元素初始化为'a',第二个元素初始化为98, 第三个元素初始化为'c'
int arr[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
两个初始化的比较:
#include <stdio.h>
int main()
{
char ch1[10] = { 'a', 'b', 'c' }; //a b c 0 0 0 0 0 0 0
char ch2[10] = "abc"; //a b c \0 0 0 0 0 0 0
return 0;
}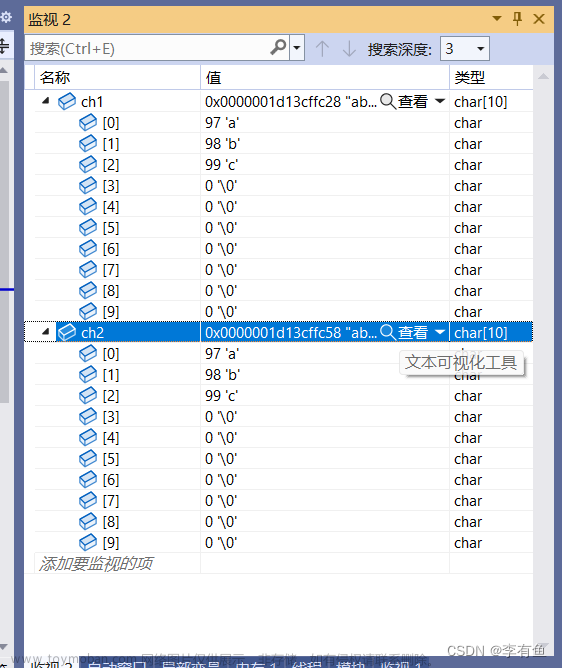
在监视中我们发现ch1和ch2中存储的数据是一样的,但是其实他们的性质不同,ch1中第一个元素初始化为'a',第二个元素初始化为 'b',第三个元素初始化为'c',其余的元素默认初始化为0,而ch2中第一个元素初始化为'a',第二个元素初始化为'b',第三个元素初始化为'c',第四个元素初始化为'\0'(相当于0),其余元素默认初始化为0。
数组在创建的时候如果不想指定数组确定的大小就得初始化。数组的元素个数根据初始化的内容来确定。
但是注意不要像下方的写法:
char ch1[] = "";上述的初始化很容易出问题:
#include <stdio.h>
int main()
{
char ch1[] = "";
scanf("%s", ch1);
printf("%s\n", ch1);
return 0;
}我们发现上述代码执行会报错:
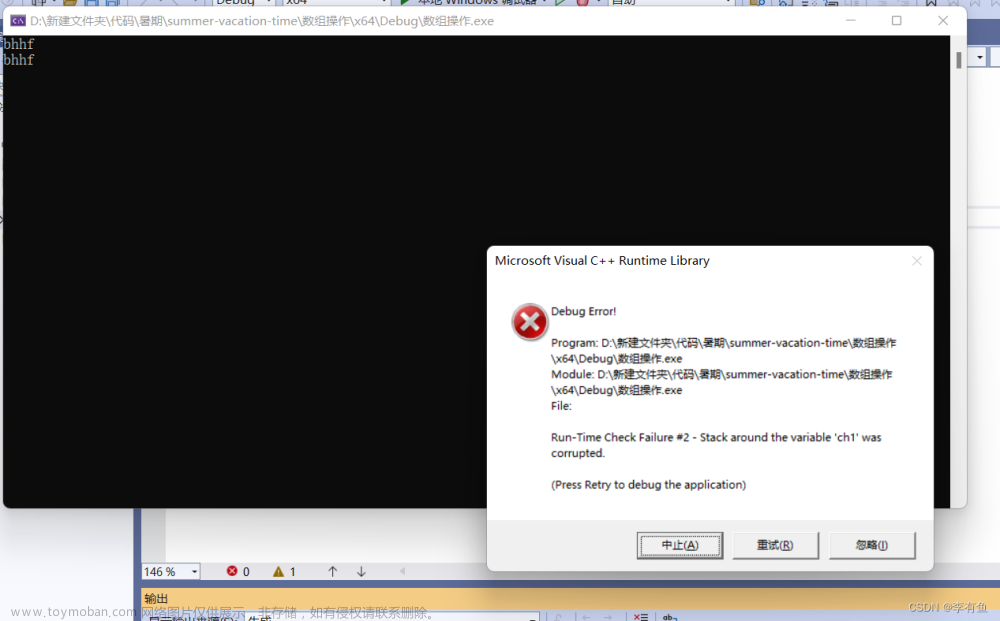
这是因为我们输入的字符长度超过了数组的长度
char ch1[] = ""; 在创建数组ch1时未指定大小,数组的元素个数根据初始化的内容来确定,在这里我们使用空字符串初始化,空字符串中只有一个'\0',用'\0'初始化这个数组,这个数组的长度就是1,我们输入一个超过一个字符的字符串就会报错。
1.3 一维数组的使用
在这里我们要知道一个操作符:[ ],下标引用操作符,它其实就是用来访问数组的操作符。
我们需要知道数组的每一个元素都有对应的下标,并且数组的下标是从0开始的。
例如有一个数组 int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
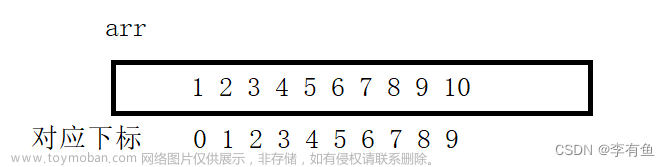
我们访问元素通过下标来访问例如我们要访问数组的第5个元素我们就可以使用arr[4]来访问。
我们可以将数组的每一个元素打印出来:
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}注意在这里的arr[i]表示数组的一个元素,而不是创建数组,访问数组元素可以使用变量。
总结:
- 数组是使用下标来访问的,下标是从0开始的。
- 数组的大小可以通过计算得到。即int sz = sizeof(arr) / sizeof(arr[0]);
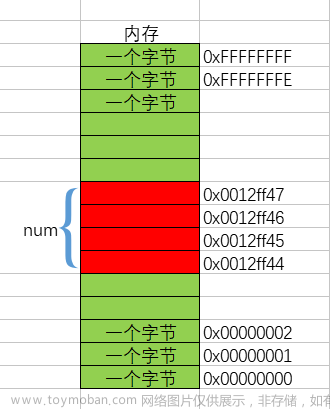
1.4 一维数组在内存中的存储
我们要探讨一维数组在内存中的存储,就要看一维数组各元素的地址。
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
for (i = 0; i < sz; i++)
{
printf("&arr[%d] = %p\n",i, &arr[i]);
}
return 0;
}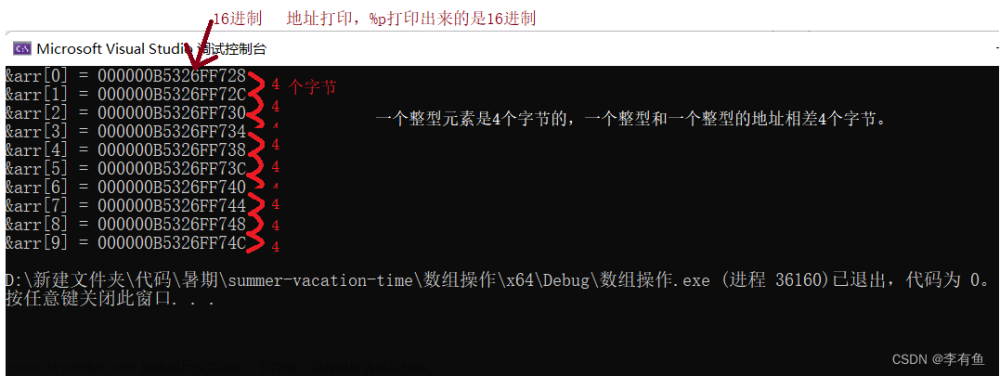
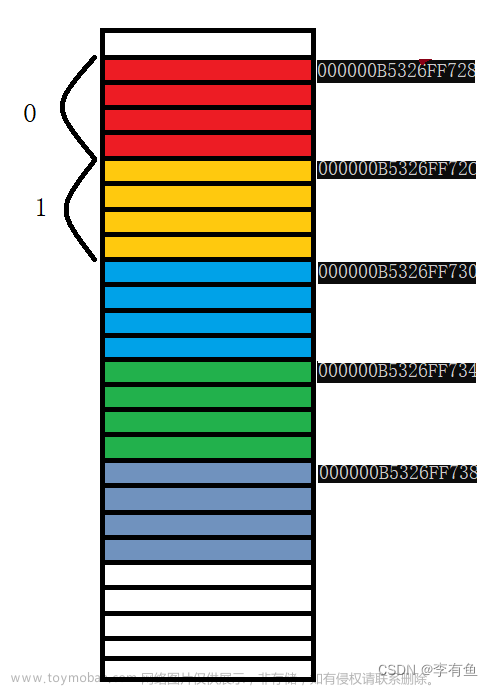
由此我们可以得出:数组在内存中是连续存放的
结论:
- 随着 数组下标的增长,元素的地址,也在有规律的递增。
- 数组在内存中是连续存放的。
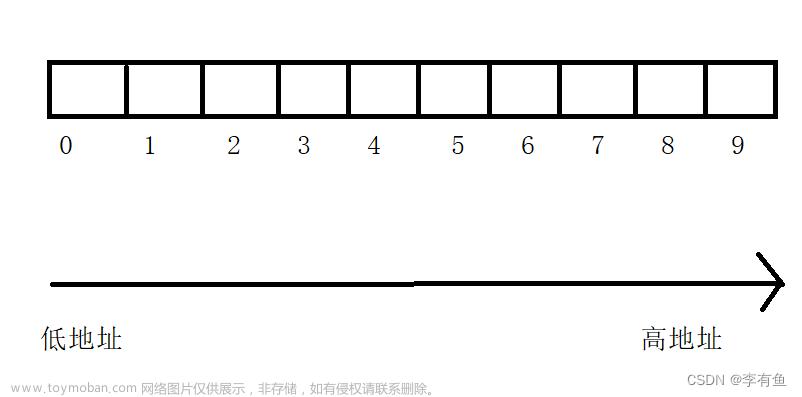
二、二维数组的创建和初始化
2.1 二维数组的创建
二维数组相当于是多了一个维度,例如:
我们想要创建一个数组,来存放三行四列的整型元素:int arr[3][4];
int arr[3][4];
2.2 二维数组的初始化
两种方式:
1.直接初始化,元素一个挨着一个初始化,初始化完一行再初始化一行,未放数据的元素初始化为 0
例如int arr[3][4] = { 1, 2, 3, 4 };
2.二维数组是可以指定第一行初始化为什么,第二行初始化为什么例如有三行四列的元素,我们想要把1,2初始化在第一行,3,4初始化在第二行,5初始化到第三行,(二维数组可以把他的一行当成一维数组,一维数组初始化用{ })因此我们这里可以int arr[3][4] = { { 1, 2 }, { 3, 4 }, { 5 } }
注意:
二维数组如果有初始化,行可以省略,列不可以省略。
即:int arr[][3] = { { 2, 3 }, { 4, 5 } };
2.3 二维数组的使用
二维数组的使用也是通过下标的方式。
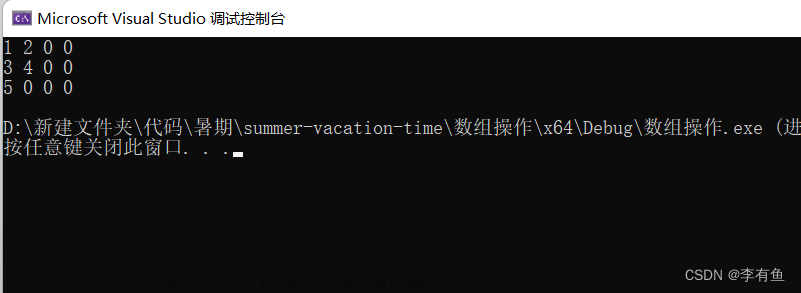
我们可以使用两种方式打印出来二维数组的元素:
按行打印:
#include <stdio.h>
int main()
{
int arr[3][4] = { {1, 2},{3, 4},{5} };
int i = 0;
for (i = 0; i < 3; i++)
{
int j = 0;
for (j = 0; j < 4; j++)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}
return 0;
}
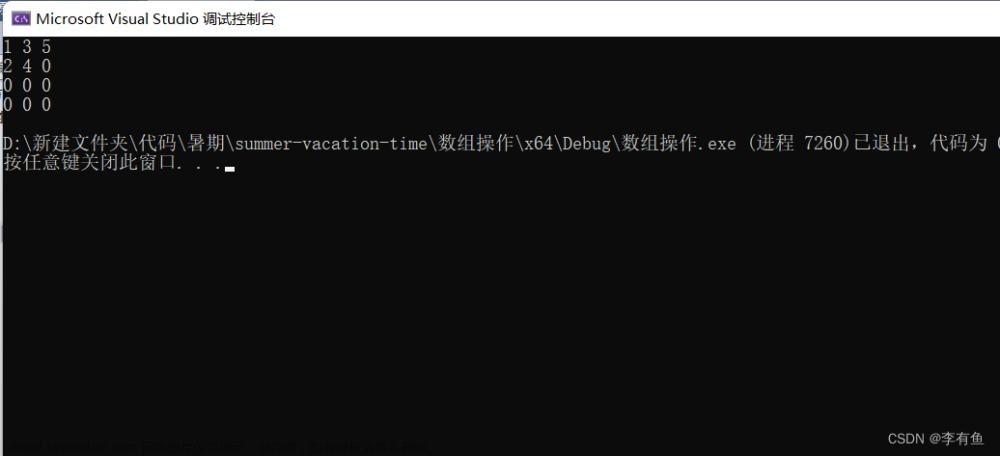
按列打印:
#include <stdio.h>
int main()
{
int arr[3][4] = { {1, 2},{3, 4},{5} };
int j = 0;
for (j = 0; j < 4; j++)
{
int i = 0;
for (i = 0; i < 3; i++)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}
return 0;
} 
2.4 二维数组在内存中的存储
要了解二维数组在内存中的存储,我们依然要去分析数组元素的地址。
#include <stdio.h>
int main()
{
int arr[3][4] = { {1, 2},{3, 4},{5} };
int i = 0;
for (i = 0; i < 3; i++)
{
int j = 0;
for (j = 0; j < 4; j++)
{
printf("&arr[%d][%d] = %p\n", i, j, &arr[i][j]);
}
}
return 0;
}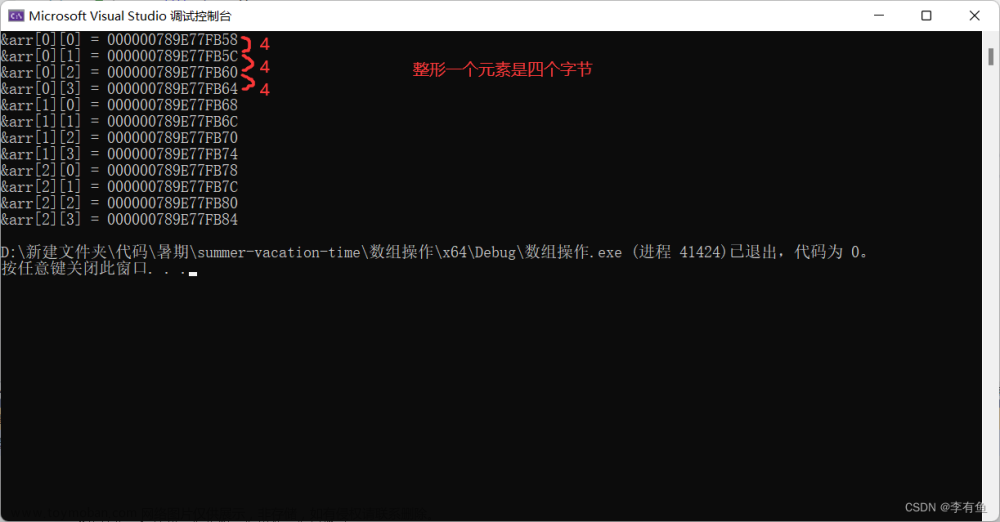
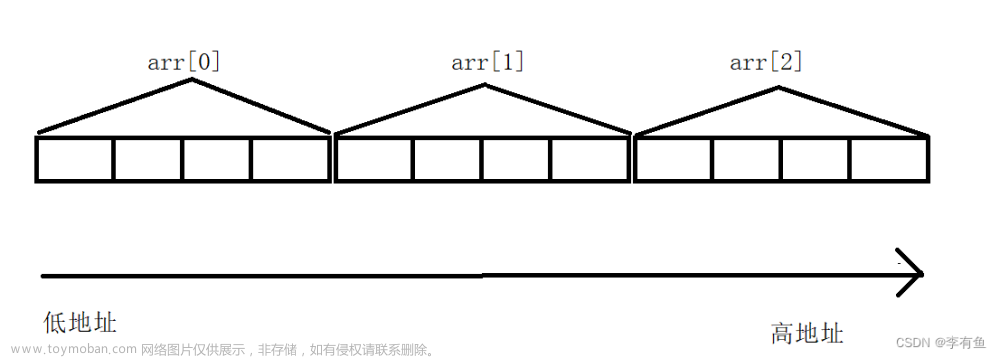
我们发现在内存中二维数组依然是连续存储的,即:

结论:
二位数组在内存中也是连续存储的。
三、数组越界
数组的下标是有范围限制的。
数组的下标是从0开始的,如果数组有n个元素,最后一个元素的下标就是n-1。
所以数组的下标如果小于0,或者大于n-1,就是越界访问了,超出了数组合法空间的访问。
c语言本身是不做数组下标的越界检查,编译器也不一定报错,但是编译器不报错,不代表程序是正确的,我们在写代码时需要自己做越界的检查。
越界会出现什么后果呢?
我们可以举例来看:
#include <stdio.h>
int main()
{
int arr[3][4] = { {1, 2},{3, 4},{5} };
int i = 0;
for (i = 0; i < 3; i++)
{
int j = 0;
for (j = 0; j < 5; j++)
{
printf("%d ",arr[i][j]);
}
}
return 0;
} 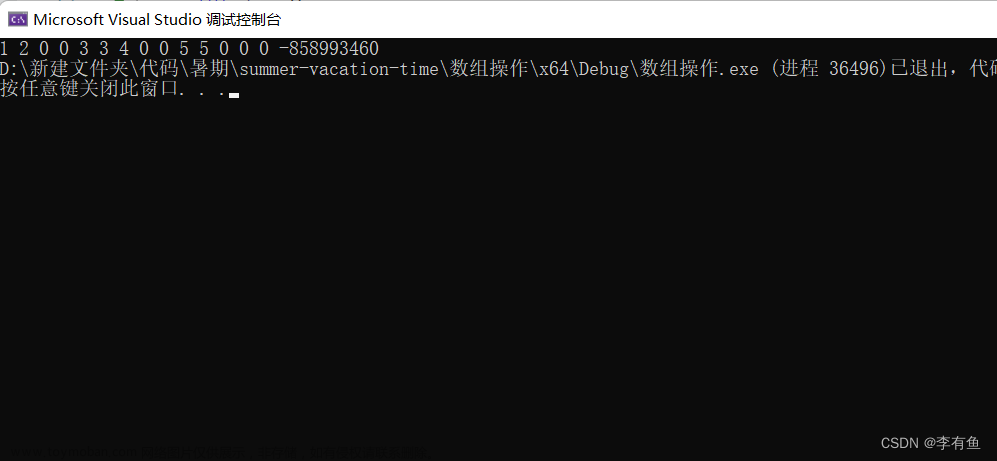
上述就是列越界的例子,会导致数组的读取紊乱,相当于:
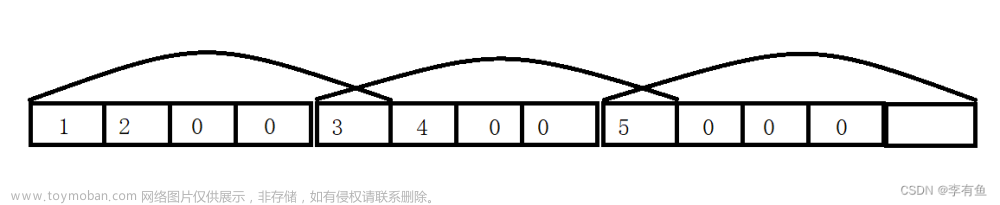
四、数组作为函数参数
在这里我们具体使用冒泡排序的例子来讲解 :
我们想要实现一个冒泡排序函数将一个整型数组排序。
冒泡排序的思想:
两两相邻的元素进行比较,如果他们的顺序错误就把他们交换过来。一趟冒泡排序(把一组待排序的元素里面相邻的两个元素进行比较并且按照要求进行交换)之后最后一个位置放的是最大(最小)的数。

文章来源地址https://www.toymoban.com/news/detail-401956.html
4.1 冒泡排序函数的错误设计
#include <stdio.h>
void bubble_sort(int arr[])
{
//求数组元素的个数
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
for (i = 0; i < sz - 1; i++)
{
//一趟冒泡排序
int j = 0;
for (j = 0; j <sz-1-i ; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
int main()
{
int arr[10] = { 9,8,7,6,5,4,3,2,1,0 };
//0 1 2 3 4 5 6 7 8 9
//要对数组升序排序
//冒泡排序
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}我们发现代码会报错
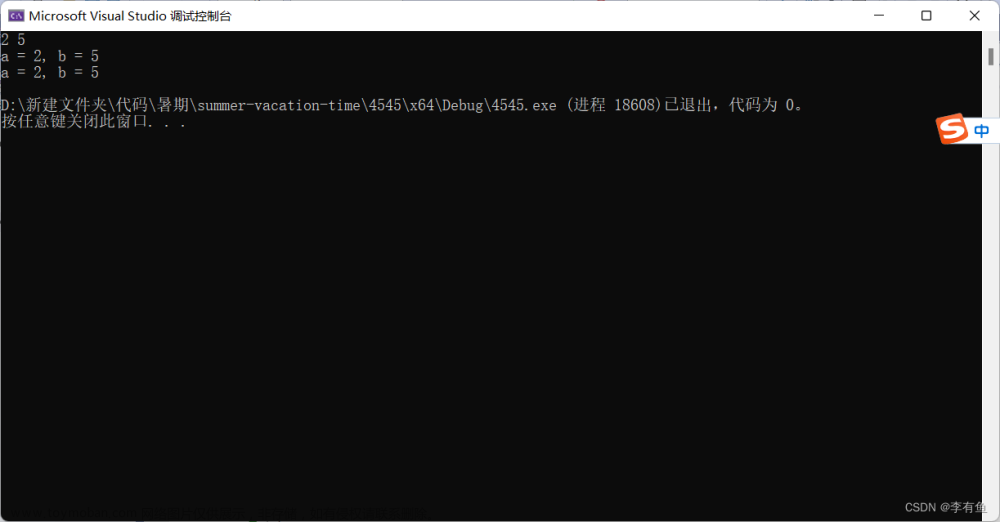
我们来分析错误原因:
所以在这里我们知道是由于数组名传参的时候传递的是首元素的地址导致sz无法计算最终程序错误。
4.2 冒泡排序函数的正确设计
上述代码错误是由于sz在自定义函数内部的计算错误,那么我们可以根据此处改进:
#include <stdio.h>
void bubble_sort(int arr[],int sz)
{
int i = 0;
for (i = 0; i < sz - 1; i++)
{
//一趟冒泡排序
int j = 0;
for (j = 0; j <sz-1-i ; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
int main()
{
int arr[10] = { 9,8,7,6,5,4,3,2,1,0 };
//0 1 2 3 4 5 6 7 8 9
//要对数组升序排序
//冒泡排序
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr,sz);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}我们直接将sz的值传参过去,避免了在自定义函数内部的计算。
4.3 数组名是什么
数组名是首元素的地址(有两个例外)。
- sizeof(数组名),计算整个数组的大小,数组名表示整个数组,单位是字节。
- &数组名,数组名表示整个数组,取出的是整个数组的地址。
除了上述情况以外,所有的数组名都表示数组首元素的地址。
在这里,我们介绍一下上述2与其他的区别: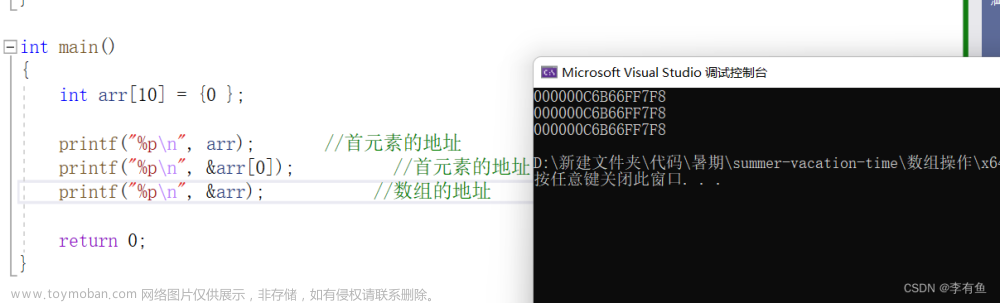
数组的地址也是首元素的地址所以这里相同。
不同:
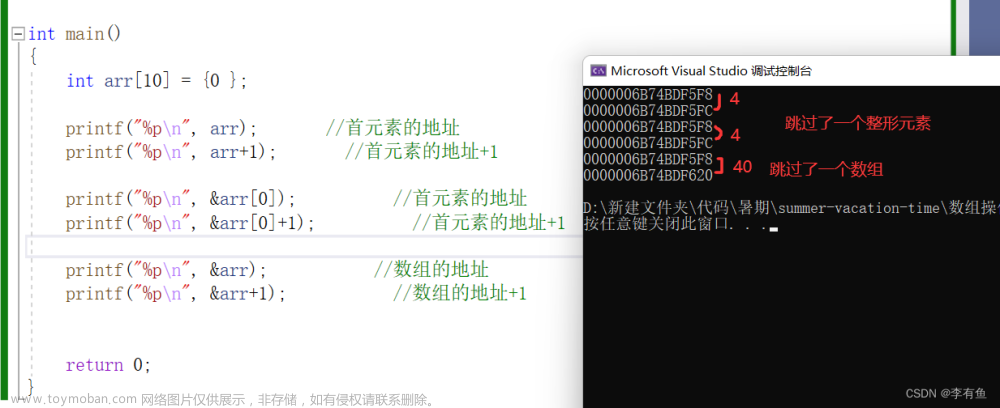 文章来源:https://www.toymoban.com/news/detail-401956.html
文章来源:https://www.toymoban.com/news/detail-401956.html
到了这里,关于数组(一篇带你掌握数组)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[Linux 基础] 一篇带你了解linux权限问题](https://imgs.yssmx.com/Uploads/2024/02/714142-1.png)



![[ C++ ] 一篇带你了解C++中隐藏的this指针](https://imgs.yssmx.com/Uploads/2024/02/471445-1.png)



