FFmpeg 的社群来了,想加入微信社群的朋友请购买《FFmpeg原理》VIP版 电子书,里有更高级的内容与答疑服务。
在做音频处理的时候,我们有时候需要调整音频流的采样率 或者 采样格式,可能是喇叭不支持 48000 采样率,所以需要降低到 44100 采样了.也可能因为各种业务原因,需要调整 采样率,采样格式,或者声道布局。
FFmpeg 提供了 swr_convert() 函数来实现上面的功能。
需要注意的是,调整采样率,是不会影响音频流的播放时长的,原来是 10 分钟的音频文件,你调高或者降低采样率,它还是 10 分钟的播放时长。
不过 swr_convert() 是支持调整播放时长的,这个后面说。
下面通过一个代码实例演示 swr_convert() 函数的用法,代码下载地址:GitHub,编译环境是 Qt 5.15.2 跟 MSVC2019_64bit 。
这个代码实例主要是把 音频流的 采样率 从 48000 降低到 44100,把音频格式 从 fltp 转成 s64,声道布局不变。
int tgt_fmt = AV_SAMPLE_FMT_S64;
int tgt_freq = 44100;
重点代码如下:

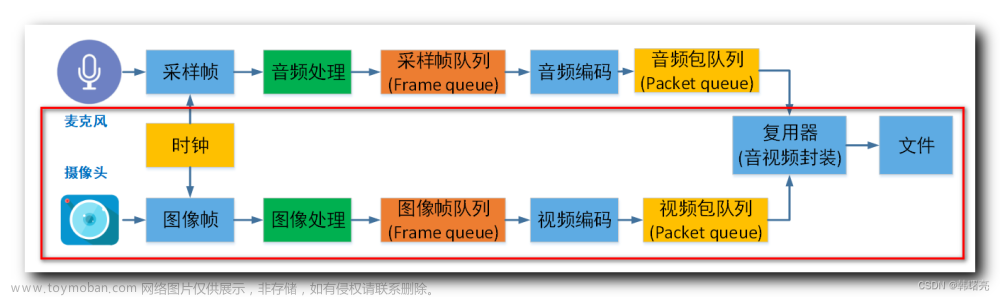
音频重采样库的API函数调用流程如下:

下面来介绍一下各个函数。
1,swr_alloc_set_opts(),定义如下:
struct SwrContext *swr_alloc_set_opts(struct SwrContext *s,
int64_t out_ch_layout, enum AVSampleFormat out_sample_fmt, int out_sample_rate,
int64_t in_ch_layout, enum AVSampleFormat in_sample_fmt, int in_sample_rate,
int log_offset, void *log_ctx);
参数解释如下:
-
struct SwrContext *s,如果传 NULL,他内部会申请一块内存,非NULL可以复用之前的内存,不用申请。 -
int64_t out_ch_layout,目标声道布局 -
enum AVSampleFormat out_sample_fmt,目标采样格式 -
int out_sample_rate,目标采样率 -
int64_t in_ch_layout,原始声道布局 -
enum AVSampleFormat in_sample_fmt,原始采样格式 -
int in_sample_rate,原始采样率 -
int log_offset,不知道做什么的,填 0 就行。 -
void *log_ctx,不知道做什么的,填 NULL 就行。
2,swr_init(),初始化重采样函数,如果你更改了重采样上下文的 options,也就是改了选项,例如改了采样率,必须调 swr_init() 才能生效。。
3,swr_convert(),转换函数,定义如下:
/** Convert audio.
*
* in and in_count can be set to 0 to flush the last few samples out at the
* end.
*
* If more input is provided than output space, then the input will be buffered.
* You can avoid this buffering by using swr_get_out_samples() to retrieve an
* upper bound on the required number of output samples for the given number of
* input samples. Conversion will run directly without copying whenever possible.
*
* @param s allocated Swr context, with parameters set
* @param out output buffers, only the first one need be set in case of packed audio
* @param out_count amount of space available for output in samples per channel
* @param in input buffers, only the first one need to be set in case of packed audio
* @param in_count number of input samples available in one channel
*
* @return number of samples output per channel, negative value on error
*/
int swr_convert(struct SwrContext *s, uint8_t **out, int out_count,
const uint8_t **in , int in_count);
参数解释如下:
-
struct SwrContext *s,重采样上下文,也叫重采样实例。 -
uint8_t **out,输出的内存地址。 -
int out_count,每声道有多少个样本,这个值通常建议设置得大一点,避免内存空间不够,不够空间写入,就会缓存在重采样实例里面,越积越多。 -
const uint8_t **in,输入的内存地址。 -
int in_count,输入的音频流,每声道有多少个样本。
swr_convert() 函数的返回值是实际的样本数。
项目代码的运行结果如下:
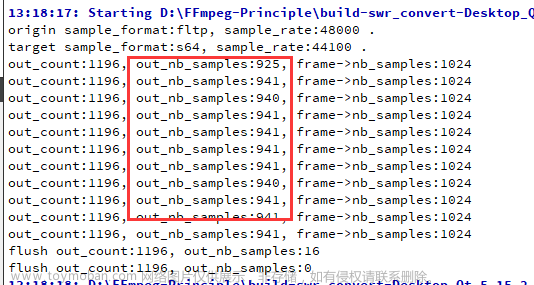
本文项目代码的重点是 out_count 的计算,如下:
out_count = (int64_t)frame->nb_samples * tgt_freq / frame->sample_rate + 256;
由于源文件 juren-30s.mp4 大部分音频帧是 1024 个样本数,从 48000 降低 44100,也就是说 1024个样本 会 变成 940 个样本。
但是从上图的运行结果可以看到,有时候是转换出 941 个样本的,比 940 多了一个。所以 out_count 通常会在本来的大小上 加上 256,让写空间大一点。
如果不够空间写入,就会缓存在重采样实例里面,越积越多。
+256 也是 ffplay 播放器的做法。
最后还有一个重点是,SwrContext 上下文里面可能会有残留数据,当没有数据输入的时候,需要再调 swr_convert() ,把残留的数据刷出来,如下:


可以看到,最后刷出来了 16 个残留样本。
上面讲的是播放器的重采样场景,重采样之后,获取到了内存 out ,直接把 out 的内存丢给 SDL 即可播放。
但是有时候,我们是需要把转换之后的数据进行编码保存的,所以这种情况下,需要把 out 的内存挂在 AVFrame 里面,具体做法如下:
AVFrame frame;
frame->extended_data = out;
frame->data = out;
frame->nb_samples = out_nb_samples;
然后设置好 frame 的 pts 即可,这样应该是可以的,不过我没编码测试过,后面补充。
音频也可以用 av_samples_alloc() 来申请内存,但是由于本文要 +256 ,所以没有使用这个函数。
扩展知识:
音频与视频的转换函数,命名是类似的,例如:
av_samples_alloc()
av_image_alloc()
av_samples_fill_arrays()
av_image_fill_arrays()
而 av_frame_get_buffer() 函数可以同时用于音频,视频的申请内存,前提是设置好 AVFrame 的 格式,宽高,采样率,声道。
swr_convert() 函数使用起来,我个人觉得有点繁琐,其实音频的 aformat 格式滤镜也可以调整 采样率,采样格式,声道布局。
滤镜的语法比较统一,只是 aformat 滤镜不能调整播放时长,推荐阅读《FFmpeg的音频aformat滤镜介绍》
最后需要用swr_free() 释放调重采样实例。文章来源:https://www.toymoban.com/news/detail-402029.html
一开始留的彩蛋,调整播放时长,是用 swr_set_compensation() 实现,推荐阅读《如何调整音频播放时长》文章来源地址https://www.toymoban.com/news/detail-402029.html
到了这里,关于swr_convert音频重采样介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!