
文章目录
Hive优化措施
一、Fetch抓取
二、本地模式文章来源:https://www.toymoban.com/news/detail-402100.html
三、表的优化文章来源地址https://www.toymoban.com/news/detail-402100.html
到了这里,关于大数据面试题(八):Hive优化措施的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
这篇具有很好参考价值的文章主要介绍了大数据面试题(八):Hive优化措施。希望对大家有所帮助。如果存在错误或未考虑完全的地方,请大家不吝赐教,您也可以点击"举报违法"按钮提交疑问。
文章目录
Hive优化措施
一、Fetch抓取
二、本地模式文章来源:https://www.toymoban.com/news/detail-402100.html
三、表的优化文章来源地址https://www.toymoban.com/news/detail-402100.html
到了这里,关于大数据面试题(八):Hive优化措施的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处: 如若内容造成侵权/违法违规/事实不符,请点击违法举报进行投诉反馈,一经查实,立即删除!
目录 1、集群的最主要瓶颈 2、Hadoop运行模式 3、Hadoop生态圈的组件并做简要描述 4、解释“hadoop”和“hadoop 生态系统”两个概念 5、请列出正常工作的Hadoop集群中Hadoop都分别需要启动哪些进程,它们的作用分别是什么? 6、基于 Hadoop 生态系统对比传统数据仓库有何优势? 7、如
你准备好面试了吗?这里有一些面试中可能会问到的问题以及相对应的答案。如果你需要更多的面试经验和面试题,关注一下\\\"张飞的猪大数据分享\\\"吧,公众号会不定时的分享相关的知识和资料。 目录 1、谈谈Hadoop序列化和反序列化及自定义bean对象实现序列化? 2、FileInputForma
你准备好面试了吗?这里有一些面试中可能会问到的问题以及相对应的答案。如果你需要更多的面试经验和面试题,关注一下\\\" 张飞的猪大数据分享 \\\"吧,公众号会不定时的分享相关的知识和资料。 目录 1、为什么会产生 yarn,它解决了什么问题,有什么优势? 2、简述hadoop1与h
目录 一、前言 二、hive执行计划 2.1 hive explain简介 2.1.1 语法格式
目录 一、前言 二、hive 常用数据存储格式 2.1 文件格式-TextFile 2.1.1 操作演示
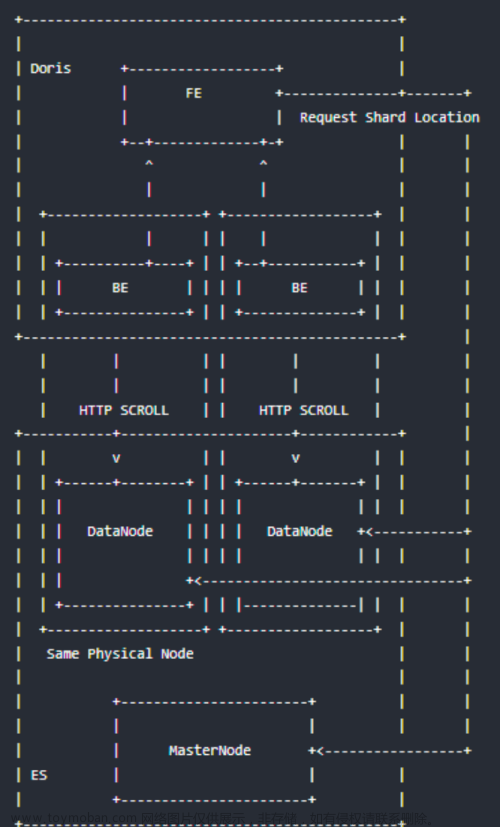
准备表和数据: Spark 读写 Doris Spark Doris Connector 可以支持通过 Spark 读取 Doris 中存储的数据,也支持通过Spark写入数据到Doris。 代码库地址:https://github.com/apache/incubator-doris-spark-connector 支持从 Doris 中读取数据 支持 Spark DataFrame 批量/流式 写入 Doris 可以将 Doris 表映射为 DataFra

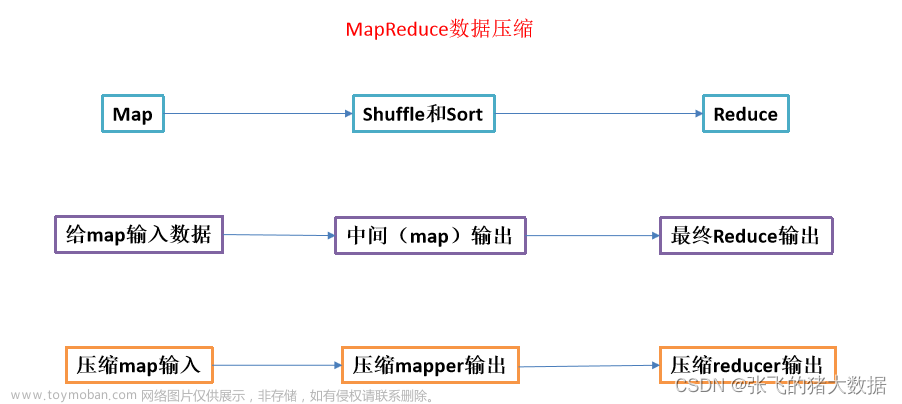
数据倾斜问题,通常是指参与计算的数据分布不均,即某个key或者某些key的数据量远超其他key,导致在shuffle阶段,大量相同key的数据被发往同一个Reduce,进而导致该Reduce所需的时间远超其他Reduce,成为整个任务的瓶颈。 比如对于一张表的province_id字段,其中99%的值都为1,则
嗨,亲爱的前端开发者!在构建Web应用程序时,确保安全性是至关重要的。本文将深入讨论前端开发中的安全性问题,并提供一些防范措施,以确保你的应用程序和用户数据的安全性。 前端安全性问题: 跨站脚本攻击(XSS): XSS攻击发生在恶意用户将恶意脚本注入到网页中

数据倾斜指参与计算的数据分布不均,即某个key或者某些key的数据量远超其他key,导致在shuffle阶段,大量相同key的数据被发往同一个Reduce,导致该Reduce所需的时间远超其他Reduce,成为整个任务的瓶颈。 Hive中的数据倾斜常出现在分组聚合和join操作的场景中 。

目录 一.优化Nginx 二.隐藏/查看版本号 隐藏版本号方法一:修改配置文件,关闭版本号 隐藏版本号方法二:修改源码文件中的版本号,重新编译安装 三.修改用户与组 四.设置缓存时间 五.日志切割脚本 六.设置连接超时控制连接访问时间 七.开启多进程 八.配置网页压缩 九



