简介
基于doris官方用doris构建实时仓库的思路,从flinkcdc到doris实时数仓的实践。

原文
Apache Flink X Apache Doris 构建极速易用的实时数仓架构 (qq.com)
前提-Flink CDC 原理、实践和优化
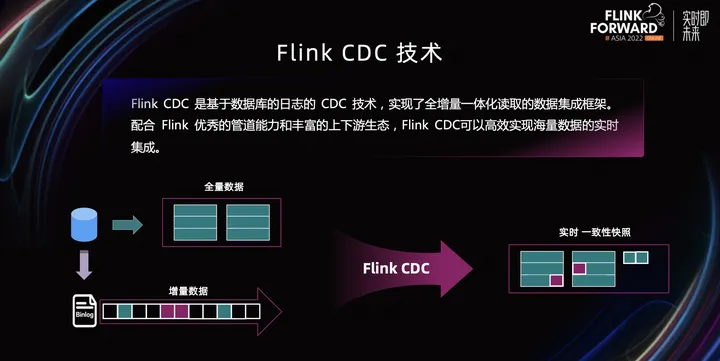
CDC 是什么
CDC 是变更数据捕获(Change Data Capture)技术的缩写,它可以将源数据库(Source)的增量变动记录,同步到一个或多个数据目的(Sink)。在同步过程中,还可以对数据进行一定的处理,例如分组(GROUP BY)、多表的关联(JOIN)等。
例如对于电商平台,用户的订单会实时写入到某个源数据库;A 部门需要将每分钟的实时数据简单聚合处理后保存到 Redis 中以供查询,B 部门需要将当天的数据暂存到 Elasticsearch 一份来做报表展示,C 部门也需要一份数据到 ClickHouse 做实时数仓。随着时间的推移,后续 D 部门、E 部门也会有数据分析的需求,这种场景下,传统的拷贝分发多个副本方法很不灵活,而 CDC 可以实现一份变动记录,实时处理并投递到多个目的地。
下图是一个示例,通过腾讯云 Oceanus 提供的 Flink CDC 引擎,可以将某个 MySQL 的数据库表的变动记录,实时同步到下游的 Redis、Elasticsearch、ClickHouse 等多个接收端。这样大家可以各自分析自己的数据集,互不影响,同时又和上游数据保持实时的同步。

CDC 的实现原理
通常来讲,CDC 分为主动查询和事件接收两种技术实现模式。
对于主动查询而言,用户通常会在数据源表的某个字段中,保存上次更新的时间戳或版本号等信息,然后下游通过不断的查询和与上次的记录做对比,来确定数据是否有变动,是否需要同步。这种方式优点是不涉及数据库底层特性,实现比较通用;缺点是要对业务表做改造,且实时性不高,不能确保跟踪到所有的变更记录,且持续的频繁查询对数据库的压力较大。
事件接收模式可以通过触发器(Trigger)或者日志(例如 Transaction log、Binary log、Write-ahead log 等)来实现。当数据源表发生变动时,会通过附加在表上的触发器或者 binlog 等途径,将操作记录下来。下游可以通过数据库底层的协议,订阅并消费这些事件,然后对数据库变动记录做重放,从而实现同步。这种方式的优点是实时性高,可以精确捕捉上游的各种变动;缺点是部署数据库的事件接收和解析器(例如 Debezium、Canal 等),有一定的学习和运维成本,对一些冷门的数据库支持不够。
综合来看,事件接收模式整体在实时性、吞吐量方面占优,如果数据源是 MySQL、PostgreSQL、MongoDB 等常见的数据库实现,建议使用 Debezium 来实现变更数据的捕获(下图来自 Debezium 官方文档)。如果使用的只有 MySQL,则还可以用 Canal。

为什么选 Flink
从上图可以看到,Debezium 官方架构图中,是通过 Kafka Streams 直接实现的 CDC 功能。而我们这里更建议使用 Flink CDC 模块,因为 Flink 相对 Kafka Streams 而言,有如下优势:
- Flink 的算子和 SQL 模块更为成熟和易用
- Flink 作业可以通过调整算子并行度的方式,轻松扩展处理能力
- Flink 支持高级的状态后端(State Backends),允许存取海量的状态数据
- Flink 提供更多的 Source 和 Sink 等生态支持
- Flink 有更大的用户基数和活跃的支持社群,问题更容易解决
- Flink 的开源协议允许云厂商进行全托管的深度定制,而 Kafka Streams 只能自行部署和运维
而且 Flink Table / SQL 模块将数据库表和变动记录流(例如 CDC 的数据流)看做是同一事物的两面,因此内部提供的 Upsert 消息结构(+I 表示新增、-U 表示记录更新前的值、+U 表示记录更新后的值,-D 表示删除)可以与 Debezium 等生成的变动记录一一对应。
Flink CDC 的使用方法
目前 Flink CDC 支持两种数据源输入方式。
输入 Debezium 等数据流进行同步
例如 MySQL -> Debezium -> Kafka -> Flink -> PostgreSQL。适用于已经部署好了 Debezium,希望暂存一部分数据到 Kafka 中以供多次消费,只需要 Flink 解析并分发到下游的场景。

在该场景下,由于 CDC 变更记录会暂存到 Kafka 一段时间,因此可以在这期间任意启动/重启 Flink 作业进行消费;也可以部署多个 Flink 作业对这些数据同时处理并写到不同的数据目的(Sink)库表中,实现了 Source 变动与 Sink 的解耦。
CREATE TABLE `Data_Input` (
id BIGINT,
actor VARCHAR,
alias VARCHAR,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'kafka', -- 可选 'kafka','kafka-0.11'. 注意选择对应的内置 Connector
'topic' = 'YourDebeziumTopic', -- 替换为您要消费的 Topic
'scan.startup.mode' = 'earliest-offset' -- 可以是 latest-offset / earliest-offset / specific-offsets / group-offsets 的任何一种
'properties.bootstrap.servers' = '10.0.1.2:9092', -- 替换为您的 Kafka 连接地址
'properties.group.id' = 'YourGroup', -- 必选参数, 一定要指定 Group ID
-- 定义数据格式 (Debezium JSON 格式)
'format' = 'debezium-json',
'debezium-json.schema-include' = 'false',
);
CREATE TABLE `Data_Output` (
id BIGINT,
actor VARCHAR,
alias VARCHAR,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:postgresql://postgresql.example:50060/myDatabase?currentSchema=mySchema&reWriteBatchedInserts=true', -- 请替换为您的实际 PostgreSQL 连接参数
'table-name' = 'MyTable', -- 需要写入的数据表
'username' = 'user', -- 数据库访问的用户名(需要提供 INSERT 权限)
'password' = 'helloworld' -- 数据库访问的密码
);
INSERT INTO `Data_Output` SELECT * FROM `Data_Input`;如果在流计算 Oceanus 界面上,可以勾选 kafka 和 jdbc 两个内置的 Connector:

随后直接开始运行作业,Flink 就会源源不断的消费 YourDebeziumTopic 这个 Kafka 主题中 Debezium 写入的记录,然后输出到下游的 MySQL 数据库中,实现了数据同步。
直接对接上游数据库进行同步
我们还可以跳过 Debezium 和 Kafka 的中转,使用 Flink CDC Connectors 对上游数据源的变动进行直接的订阅处理。从内部实现上讲,Flink CDC Connectors 内置了一套 Debezium 和 Kafka 组件,但这个细节对用户屏蔽,因此用户看到的数据链路如下图所示:

用法示例
同样的,这次我们有个 MySQL 数据库,需要实时将内容同步到 PostgreSQL 中。但我们没有也不想安装 Debezium 等额外组件,那我们可以新建一个 Flink SQL 作业,然后输入如下 SQL 代码(连接参数都是虚拟的,仅供参考):
CREATE TABLE `Data_Input` (
id BIGINT,
actor VARCHAR,
alias VARCHAR,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc', -- 可选 'mysql-cdc' 和 'postgres-cdc'
'hostname' = '192.168.10.22', -- 数据库的 IP
'port' = '3306', -- 数据库的访问端口
'username' = 'debezium', -- 数据库访问的用户名(需要提供 SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT, SELECT, RELOAD 权限)
'password' = 'hello@world!', -- 数据库访问的密码
'database-name' = 'YourData', -- 需要同步的数据库
'table-name' = 'YourTable' -- 需要同步的数据表名
);
CREATE TABLE `Data_Output` (
id BIGINT,
actor VARCHAR,
alias VARCHAR,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:postgresql://postgresql.example:50060/myDatabase?currentSchema=mySchema&reWriteBatchedInserts=true', -- 请替换为您的实际 PostgreSQL 连接参数
'table-name' = 'MyTable', -- 需要写入的数据表
'username' = 'user', -- 数据库访问的用户名(需要提供 INSERT 权限)
'password' = 'helloworld' -- 数据库访问的密码
);
INSERT INTO `Data_Output` SELECT * FROM `Data_Input`; 如果在流计算页面,可以选择内置的 mysql-cdc 和 jdbc Connector:

注意
需要使用 Flink CDC Connectors 附加组件。腾讯云 Oceanus 已经自带了 MySQL-CDC Connector,如果自行部署的话,需要下载 jar 包并将其放入 Flink 的 lib 目录下。
访问数据库时,请确保连接的用户足够权限(PostgreSQL 用户看这里,MySQL 用户看这里)
Flink CDC 模块的实现
Debezium JSON 格式解析类探秘
flink-json 模块中的 org.apache.flink.formats.json.debezium.DebeziumJsonFormatFactory 是负责构造解析 Debezium JSON 格式的工厂类;同样地,org.apache.flink.formats.json.canal.CanalJsonFormatFactory 负责 Canal JSON 格式。这些类已经内置在 Flink 1.11 的发行版中,直接可以使用,无需附加任何程序包。
对于 Debezium JSON 格式而言,Flink 将具体的解析逻辑放在了 org.apache.flink.formats.json.debezium.DebeziumJsonDeserializationSchema#DebeziumJsonDeserializationSchema 类中。

上图表示 Debezium JSON 的一条更新(Update)消息,它表示上游已将 id=123 的数据更新,且字段内包含了更新前的旧值,以及更新后的新值。
那么,Flink 是如何解析并生成对应的 Flink 消息呢?我们看下这个类的 deserialize 方法:
GenericRowData before = (GenericRowData) payload.getField(0); // 更新前的数据
GenericRowData after = (GenericRowData) payload.getField(1); // 更新后的数据
String op = payload.getField(2).toString(); // 获取 "op" 字段的类型
if (OP_CREATE.equals(op) || OP_READ.equals(op)) { // 如果是创建 (c) 或快照读取 (r) 消息
after.setRowKind(RowKind.INSERT); // 设置消息类型为新建 (+I)
out.collect(after); // 发送给下游
} else if (OP_UPDATE.equals(op)) { // 如果是更新 (u) 消息
before.setRowKind(RowKind.UPDATE_BEFORE); // 把更新前的数据类型设置为撤回 (-U)
after.setRowKind(RowKind.UPDATE_AFTER); // 把更新后的数据类型设置为更新 (+U)
out.collect(before); // 发送两条数据给下游
out.collect(after);
} else if (OP_DELETE.equals(op)) { // 如果是删除 (d) 消息
before.setRowKind(RowKind.DELETE); // 将消息类型设置为删除 (-D)
out.collect(before); // 发送给下游
} else {
... // 异常处理逻辑
}从上述逻辑可以看出,对于每一种 Debezium 的操作码(op 字段的类型),都可以用 Flink 的 RowKind 类型来表示。对于插入 +I 和删除 D,都只需要一条消息即可;而对于更新,则涉及删除旧数据和写入新数据,因此需要 -U 和 +U 两条消息来对应。
特别地,在 MySQL、PostgreSQL 等支持 Upsert(原子操作的 Update or Insert)语义的数据库中,通常前一个 -U 消息可以省略,只把后一个 +U 消息用作实际的更新操作即可,这个优化在 Flink 中也有实现。
因此可以看到,Debezium 到 Flink 消息的转换逻辑是非常简单和自然的,这也多亏了 Flink 先进的设计理念,很早就提出并实现了 Upsert 数据流和动态数据表之间的映射关系。
Flink CDC Connectors 的实现
flink-connector-debezium 模块
我们在使用 Flink CDC Connectors 时,也会好奇它究竟是如何做到的不需要安装和部署外部服务就可以实现 CDC 的。当我们阅读 flink-connector-mysql-cdc 的源码时,可以看到它内部依赖了 flink-connector-debezium 模块,而这个模块将 Debezium Embedded 嵌入到了 Connector 中。
flink-connector-debezium 的数据源实现类为 com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction,它集成了 Flink 中的 RichSourceFunction 并实现了 CheckpointedFunction 以支持快照保存状态。
通常而言,对于 SourceFunction,我们可以从它的 run 方法入手分析。它的核心代码如下:
this.engine = DebeziumEngine.create(Connect.class)
.using(properties) // 初始化 Debezium 所需的参数
.notifying(debeziumConsumer) // 收到批量的变更消息, 则 Debezium 会回调 DebeziumChangeConsumer 来反序列化并向下游输出数据
.using(OffsetCommitPolicy.always())
.using(
(success, message, error) -> {
if (!success && error != null) {
this.reportError(error);
}
})
.build();
...
executor.execute(engine); // 向 Executor 提交 Debezium 线程以启动运行可以看到,这个 SourceFunction 使用一些预先定义的参数,初始化了一个嵌入式的 DebeziumEngine(Java 的 Runnable),然后提交给线程池(executor)去执行。这个 Debezium 线程会批量接收 binlog 信息并回调传入的 debeziumConsumer 以反序列化消息并交给 Flink 来处理。本类的其他方法主要负责初始化状态和保存快照,这里略过。
这里我们再来看一下 DebeziumChangeConsumer 的实现,它的最核心的方法是 handleBatch 。当 Debezium 收到一批新的事件时,会调用这个方法来通知我们的 Connector 进行处理。这里有个 for 循环轮询的逻辑:
for (ChangeEvent<SourceRecord, SourceRecord> event : changeEvents) { // 轮询各个事件
SourceRecord record = event.value();
if (isHeartbeatEvent(record)) { // 如果时心跳包
// 只更新当前 offset 信息, 然后继续(不进行实际处理)
synchronized (checkpointLock) {
debeziumOffset.setSourcePartition(record.sourcePartition());
debeziumOffset.setSourceOffset(record.sourceOffset());
}
continue;
}
deserialization.deserialize(record, debeziumCollector); // 反序列化这条消息
if (isInDbSnapshotPhase) { // 如果处于数据库快照期, 需要阻止 Flink 检查点(Checkpoint)生成
if (!lockHold) {
MemoryUtils.UNSAFE.monitorEnter(checkpointLock);
lockHold = true;
...
}
if (!isSnapshotRecord(record)) { // 如果已经不在数据库快照期了, 就释放锁, 允许 Flink 正常生成检查点(Checkpoint)
MemoryUtils.UNSAFE.monitorExit(checkpointLock);
isInDbSnapshotPhase = false;
...
}
}
// 更新当前 offset 信息, 并向下游 Flink 算子发送数据
emitRecordsUnderCheckpointLock(
debeziumCollector.records, record.sourcePartition(), record.sourceOffset());
}可以看到逻辑比较简单,只需要关注 checkpointLock 这个对象:只有持有这个对象的锁时,才允许 Flink 进行检查点的生成。
当作业处于数据库快照期(即作业刚启动时,需全量同步源数据库的一份完整快照,此时收到的数据类型是 Debezium 的 SnapshotRecord),则不允许 Flink 进行 Checkpoint 即检查点的生成,以避免作业崩溃恢复后状态不一致;同样地,如果正在向下游算子发送数据并更新 offset 信息时,也不允许快照的进行。这些操作都是为了保证 Exacly-Once(精确一致)语义。
这里也解释了在作业刚启动时,如果数据库较大(同步时间较久),Flink 刚开始的 Checkpoint 永远失败(超时)的原因:只有当 Flink 完整同步了全量数据后,才可以进行增量数据的处理,以及 Checkpoint 的生成。
flink-connector-mysql-cdc 模块
而对于 flink-connector-mysql-cdc 模块而言,它主要涉及到 MySQLTableSource 的声明和实现。
我们知道,Flink 是通过 Java 的 SPI(Service Provider Interface)机制动态加载 Connector 的,因此我们首先看这个模块的 src/main/resources/META-INF/services/org.apache.flink.table.factories.Factory 文件,里面内容指向 com.alibaba.ververica.cdc.connectors.mysql.table.MySQLTableSourceFactory。
打开这个工厂类,我们可以看到它定义了该 Connector 所需的参数,例如 MySQL 数据库的用户名、密码、表名等信息,并负责 MySQLTableSource 实例的具体创建,而 MySQLTableSource 类对这些参数做转换,最终会生成一个上文提到的 DebeziumSourceFunction 对象。
因此我们可以发现,这个模块作用是一个 MySQL 参数的封装和转换层,最终的逻辑实现仍然是由 flink-connector-debezium 完成的。
MySQL CDC 常见问题 & 优化(重点Maxwell如果不设置成Full,那么update就可能没有old数据)
由于 Flink 的 CDC 功能还比较新(1.11 版本刚开始支持,1.12 版本逐步完善),因而在应用过程中,很可能会遇到有各种问题。鉴于大多数客户的数据源都是 MySQL,我们这里整理了客户常见的一些问题和优化方案,希望能够帮助到大家。
Debezium 报错:binlog probably contains events generated with statement or mixed based replication format 或 The MySQL server is not configured to use a FULL binlog_row_image
当前的 Binlog 格式被设置为了 STATEMENT 或者 MIXED, 这两种都不被 Debezium 支持。为了使用 Flink CDC 功能,需要把 MySQL 的 binlog-format 设置为 ROW:
SET GLOBAL binlog_format = 'ROW';
SET GLOBAL binlog_row_image = 'FULL';如果您使用的是腾讯云的 TencentDB for MySQL,请确认下面设置:

Debezium 报错:User does not have the 'LOCK TABLES' privilege required to obtain a consistent snapshot 或 Access denied; you need (at least one of) the SUPER, REPLICATION CLIENT privilege(s)
请对作业中指定的 MySQL 用户赋予如下权限:SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT,例如:
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO '用户名' IDENTIFIED BY '密码';
FLUSH PRIVILEGES; 如果您使用的数据库不允许或者不希望使用 RELOAD 进行全局锁,则还需要授予 LOCK TABLES 权限以令 Debezium 尝试进行表级锁。注意,表级锁会导致更长的数据库锁定时间!
如果希望彻底跳过锁(对数据的一致性要求不高,但要求数据库不能被锁),则可以在 WITH 参数中设置 'debezium.snapshot.locking.mode' = 'none' 参数来跳过锁操作。但请注意,同步过程中千万不要随意变更库表的结构。
作业刚启动期间,Flink Checkpoint 一直失败/重启
前文讲过,Flink CDC Connector 在初始的全量快照同步阶段,会屏蔽掉快照的执行,因此如果 Flink Checkpoint 需要执行的话,就会因为一直无法获得 checkpointLock 对象的锁而超时。
可以设置 Flink 的 execution.checkpointing.tolerable-failed-checkpoint 参数以容忍更多的 Checkpoint 失败事件,同时可以调大 Checkpoint 周期,避免作业因 Checkpoint 失败而一直重启。
JDBC Sink 批量写入时,数据会缺失几条
如果发现数据库中的某些数据在 CDC 同步后有缺失,请确认是否仍在使用 Flink 旧版 1.10 的 Flink SQL WITH 语法(例如 WITH 参数中的 connector.type 是旧语法,connector 是新语法)。
旧版语法的 Connector 在 JDBC 批量写入 Upsert 数据(例如数据库的更新记录)时,并未考虑到 Upsert 与 Delete 消息之间的顺序关系,因此会出现错乱的问题,请尽快迁移到新版的 Flink SQL 语法。
异常数据造成作业持续重启
默认情况下,如果遇到异常的数据(例如消费的 Kafka topic 在无意间混入了其他数据),Flink 会立刻崩溃重启,然后从上个快照点(Checkpoint)重新消费。由于某条异常数据的存在,作业会永远因为异常而重启。可以在 WITH 参数中加入 'debezium-json.ignore-parse-errors' = 'true' 来应对这个问题。
上游 Debezium 崩溃导致写入重复数据,结果不准
Debezium 服务端发生异常并恢复后,由于可能没有及时记录崩溃前的现场,可能会退化为 At least once 模式,即同样的数据可能被发送多次,造成下游结果不准确。
为了应对这个问题,新版的 Flink 1.12 增加了一个 table.exec.source.cdc-events-duplicate 配置项(可以编辑 flink-conf.yaml 文件来配置),建议将其设置为 true 以对这些重复数据进行去重。
但是需要注意,该选项需要数据源表定义了主键,否则也无法进行去重操作。
未来展望
在 Flink 1.11 版本中,CDC 功能首次被集成到内核中。由于 Flink 1.11.0 版本有个 严重 Bug 造成 Upsert 数据无法写入下游,我们建议使用 1.11.1 及以上版本。
在 1.12 版本上,Flink 还在配置项中增加了前文提到的 table.exec.source.cdc-events-duplicate 等选项以更好地支持 CDC 去重;还支持 Avro 格式的 Debezium 数据流,而不仅仅限于 JSON 了。另外,这个版本增加了对 Maxwell 格式的 CDC 数据流支持,
为了更好地完善 CDC 功能模块,Flink 社区创建了 FLINK-18822 以追踪关于该模块的进展。可以从中看到,Flink 1.13 主要着力于支持更多的类型(FLINK-18758),以及允许从 Debezium Avro、Canal 等数据流中读取一些元数据信息等。
而在更远的规划中,Flink 还可能支持基于 CDC 的内存数据库缓存,这样我们可以在内存中动态地 JOIN 一个数据库的副本,而不必每次都查询源库,这将极大地提升作业的处理能力,并降低数据库的查询压力。
参考文章
Flink CDC 原理、实践和优化 - 腾讯云开发者社区-腾讯云
FlinkCDC-MySql到Doris
FlinkCDC将MySQL接入Doris实战_wangleigiser的博客-CSDN博客
基于Flink CDC 和 Doris Connector 实现 MySQL分库分表数据数据实时入Doris - 知乎
Doris构建简易实时数仓
Apache Flink X Apache Doris 构建极速易用的实时数仓架构 (qq.com)
简易版实时数仓模板
CREATE TABLE demo_order_info (
`order_info` STRING,
`id` INT NOT NULL,
primary key(id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'ip',
'port' = '3306',
'username' = '账号',
'password' = '密码',
'database-name' = '数据库',
'table-name' = '表名'
);
CREATE TABLE demo_order_info_detail (
`id` int,
`order_info_id` int,
`order_info_detail` STRING,
primary key(id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'ip',
'port' = '3306',
'username' = '用户',
'password' = '密码',
'database-name' = '数据库',
'table-name' = '表名'
);
CREATE TABLE cdc_doris_sink (
`order_info_detail_id` int,
`order_info_id` int,
`order_info` STRING,
`order_info_detail_id_order_id` int,
`order_info_detail` STRING
)
WITH (
'connector' = 'doris',
'fenodes' = 'ip',
'table.identifier' = '数据库.表',
'username' = '账号',
'password' = '密码',
'sink.properties.two_phase_commit'='true',
'sink.label-prefix'='doris_demo_emp_003',
'sink.properties.format' = 'json',
'sink.properties.read_json_by_line' = 'true',
'sink.enable-delete' = 'true'
);
insert into cdc_doris_sink
select demo_order_info_detail.id,demo_order_info.id,demo_order_info.order_info,demo_order_info_detail.order_info_id,demo_order_info_detail.order_info_detail from demo_order_info_detail
INNER join demo_order_info
on demo_order_info.id=demo_order_info_detail.order_info_id;
等值连接里面order_info和order_detail(doris建表用的是order_detail_id作为唯一),不修改他们的id的情况下,修改其他的都是能够正常使用的
也就是修改他们的字段都能够同步过来。
添加也能够同步过来。
删除也能够同时删除dwd的表。
删除以后,后面来的数据也没有关联出来。
比如我删除了订单2
insert into lecangs_tiktok_analyze.`demo_order_info_detail` values(7,2,'wo shi chongqi de ') ;
dwd里面的表没有出来。
然后添加订单。
insert into lecangs_tiktok_analyze.`demo_order_info` (id,order_info) values(2,'orderinfo2') ;
成功出结果
根据checkpoing重启以后的结果(从savepoint重启不用修改'sink.label-prefix'='doris_demo_emp_003')
insert into lecangs_tiktok_analyze.`demo_order_info_detail` values(8,3,'wo shi chongqi de ') ;
#修改订单id的情况。
update demo_order_info set id='11' where id='1';
#然后添加一条指向11的数据
insert into lecangs_tiktok_analyze.`demo_order_info_detail` values(9,11,'wo shi hou mian jia de 11') ;
#然后修改下order_detail的id
update demo_order_info_detail set id='11' where id='9';
上面应该还有落一层到ods,由于时间关系我直接从cdc到dwd了,应该是mysqlcdc-ods_dors,然后mysqlcdc表关联到dwd_doris
##################增,删,改都能够同步到下游###########################大佬博客
https://hf200012.github.io/2021/10/Apache-Doris-Flink-Connector%E8%AE%BE%E8%AE%A1%E6%96%B9%E6%A1%88/
Demo:基于 Flink SQL 构建流式应用 | Jark's Blog 文章来源:https://www.toymoban.com/news/detail-402155.html
https://github.com/wuchong/flink-sql-demo/blob/master/docker-compose.yml 文章来源地址https://www.toymoban.com/news/detail-402155.html
到了这里,关于Flink进阶篇-CDC 原理、实践和优化&采集到Doris中的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!