第一步:环境准备
-
Java 8 或 11 并配置JAVA_HOME
-
Git
-
Maven
第二步:下载SeaTunnel并安装连接器
-
下载地址:https://seatunnel.apache.org/download/
-
下载SeaTunnel并安装2.3.0版本
https://www.apache.org/dyn/closer.lua/incubator/seatunnel/2.3.0/apache-seatunnel-incubating-2.3.0-bin.tar.gz
详细的安装过程可以参考:https://seatunnel.apache.org/docs/2.3.0/start-v2/locally/deployment
第三步:创建测试数据
1、在MySQL创建表source_user
create table source_user(userid int(4) primary key not null auto_increment,username varchar(16) not null);并插入一些数据
insert into source_user (username) values ("z3");insert into source_user (username) values ("l4");insert into source_user (username) values ("w5");
2、在Hive中创建表sink_user
create table sink_user( userid int, username string);第四步:运行作业
1、下载MySQL驱动程序
-
-
下载mysql驱动程序并放在 /plugins/Jdbc/lib/目录下
-
MySQL驱动可以从这里下载:https://dev.mysql.com/downloads/connector/j/
-
2、下载和拷贝Hive连接器所需包
-
-
目前版本Hive连接器需将以下包拷贝到 ./lib/ 目录下
-
hive-exec-x.x.x.jar 这个包可以从hive的lib目录下找到。
-
flink-shaded-hadoop-2-uber-x.x.x-xx.x.jar 这个包可以从这里下载:https://mvnrepository.com/artifact/org.apache.flink/flink-shaded-hadoop-2-uber
-
3、创建任务配置文件mysql_to_hive.conf 放在 ./conf/目录下
env {job.mode = "BATCH"}source {Jdbc {url = "jdbc:mysql://ctyun9/test?serverTimezone=GMT%2b8"driver = "com.mysql.cj.jdbc.Driver"user = "root"password = "123456"query = "select * from source_user"}}transform {}sink {Hive {table_name = "st.sink_user"metastore_uri = "thrift://localhost:9083"}}
如果我们需要分片并行读取,可以在JDBC中配置partition_column 和 partition_num。
连接器文档可以参考这里👉https://seatunnel.apache.org/docs/2.3.0-beta/connector-v2/source/Jdbc、https://seatunnel.apache.org/docs/2.3.0-beta/connector-v2/sink/Hive
4、运行任务
-
通过./bin/seatunnel.sh 可以运行同步任务。
-
通过-e 可以执行运行模式
-
LOCAL为本地模式,会在本机启动一个SeaTunnel实例并提交任务运行,任务运行完成后会自动关闭实例
-
CLUSTER为集群模式,可以把任务提交到SeaTunnel集群。
-
./bin/seatunnel.sh -e LOCAL -c ./config/mysql_to_hive.conf集群模式
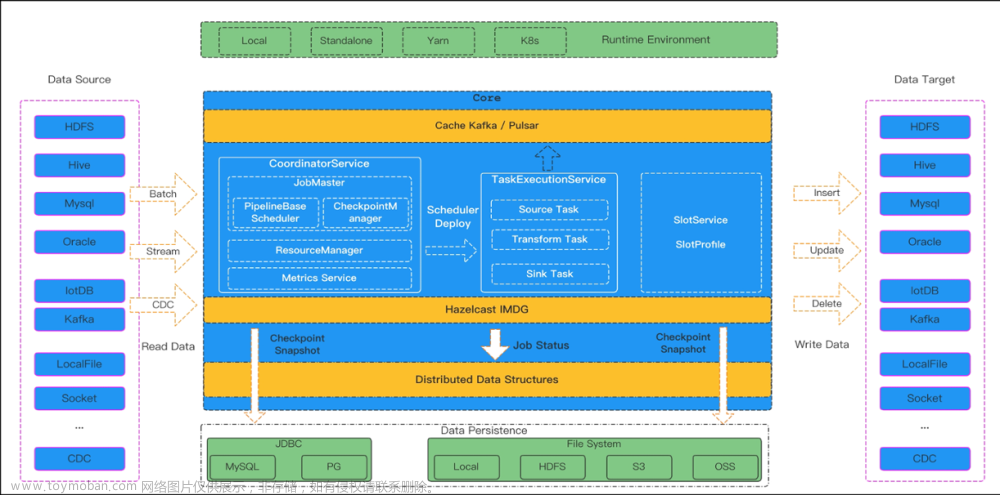
SeaTunnel也支持集群模式,集群模式的部署可以参考https://seatunnel.apache.org/docs/2.3.0/seatunnel-engine/deployment。
相比之下,集群模式比Local模式拥有更好的性能,同时支持作业的多机并行,支持集群HA、断点续传、历史作业信息存储等特性。文章来源:https://www.toymoban.com/news/detail-402392.html
集群模式的使用方式可以参考 https://seatunnel.apache.org/docs/2.3.0/seatunnel-engine/cluster-mode。文章来源地址https://www.toymoban.com/news/detail-402392.html
到了这里,关于如何使用 SeaTunnel 同步 MySQL 数据到 Hive的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!