前言
本篇主要阐述Spark Shuffle过程,在执行 Job 任务时,无论是 MapReduce 或者 Spark Shuffle 过程都是比较消耗性能;因为该环节包含了大量的磁盘 IO、序列化、网络数据传输等操作。因此,在这一过程中进行调参优化,就有可能让 Job 执行效率上更好。
在 Spark 1.2 以前,默认的 Shuffle 计算引擎是 HashShuffleManager。该 ShuffleManager 会产生大量的中间磁盘文件,进而由大量的磁盘 IO 操作影响了性能。
到 Spark 1.2 以后的版本中,默认的 ShuffleManager 改成了 SortShuffleManager。 SortShuffleManager 相较于 HashShuffleManager 来说进行了一定的改进。主要就在于,每个 Task 在进行 Shuffle 操作时,会产生较多的临时磁盘文件,但是最后会将所有的临时文件合并 (merge)成一个磁盘文件,因此每个 Task 就只有一个磁盘文件。在下一个 Stage 的 Shuffle Read Task 拉取自己的数据时,只要根据索引读取每个磁盘文件中的部分数据即可。
下面是对 HashShuffleManager 和 SortShuffleManager 的分析与原理阐述。
Spark Shuffle
HashShuffleManager
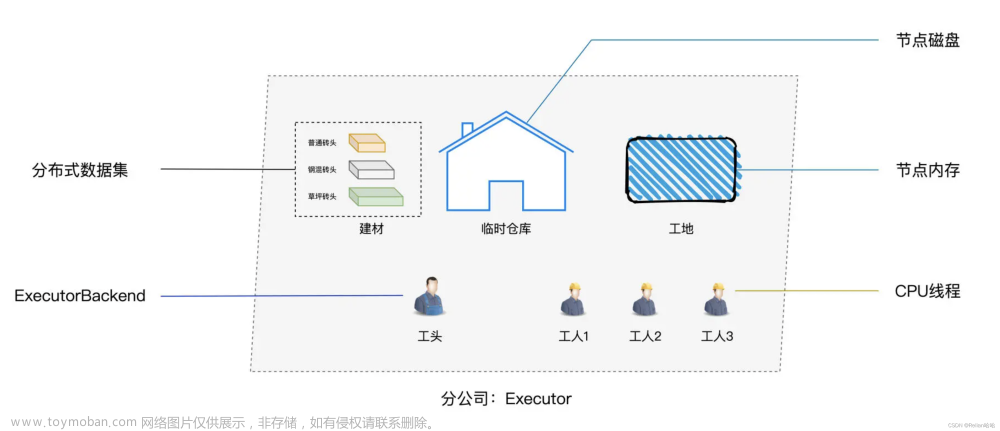
未被优化的HashShuffleManager

注:假设每个Executor 只有 1 个 CPU core,无论 Executor 上分配多少个 Task 线程,同一时间都只能执行一个 Task 线程。
- 首先 Shuffle Write 阶段,主要就是在一个 Stage 结束计算之后,为了下一个 Stage 可以执行 Shuffle 类的算子(比如 reduceBy Key ),而将每个 Task 处理的数据按 Key 进行分类。就是对相同的 Key 执行 Hash算法,从而将相同 Key 都写入同一个磁盘文件中,而每一个磁盘文件都只属于下游 Stage 的一个 Task 。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去;
- 每个执行 Shuffle Write 的 Task ,要为下一个 Stage 创建多少个磁盘文件呢?下一个 Stage 的 Task 有多少个,当前 Stage 的每个 Task 就要创建多少份磁盘文件。比如下一个 Stage 总共有 100 个 Task ,那么当前 Stage 的每个 Task 都要创建 100 份磁盘文件。如果当前 Stage 有 50 个 Task ,总共有 10 个 Executor,每个 Executor 执行 5 个 Task ,那么每个 Executor 上总共就要创建 500 个磁盘文件,所有 Executor 上会创建5000 个磁盘文件。由此可见,未经优化的shuffle write操作所产生的磁盘文件的数量是极其惊人的;
- Shuffle Read阶段,通常是一个 Stage 刚开始运行的时候。 Stage 中每一个 Task 需要将上一个 Stage 的计算结果( Key 值相同),从各个节点上通过网络都拉取到自己所在的节点上;然后进行 Key 的聚合或连接等操作。由于 Shuffle Write 的过程中, Task 给下游 Stage 的每个 Task 都创建了一个磁盘文件,因此 Shuffle Read 的过程中,每个 Task 只要从上游 Stage 的所有 Task 所在节点上,拉取属于自己的那一个磁盘文件即可;
- Shuffle Read 拉取过程是一边拉取一边进行聚合的。每个 Shuffle Read Task 都会有一个自己的 Buffer 缓冲,每次都只能拉取与 Buffer 缓冲相同大小的数据;然后通过内存中的一个 Map 进行聚合等操作。聚合完一批数据后,再拉取下一批数据,并放到 Buffer 缓冲中进行聚合操作。以此类推,直到最后将所有数据到拉取完,并得到最终的结果。
优化的HashShuffleManager

注:设置 spark.shuffle.consolidateFiles为 true 即可开启优化机制(默认为 false)
- 开启 consolidate 机制之后,在 Shuffle Write 过程中,Task 就不是为下游 Stage 的每个 Task 创建一个磁盘文件了。此时会出现 ShuffleFileGroup 的概念,每个 ShuffleFileGroup 会对应一批磁盘文件,磁盘文件的数量与下游 Stage 的 Task 数量是相同的。一个 Executor 上有多少个 CPU core,就可以并行执行多少个 Task 。而第一批并行执行的每个 Task 都会创建一个 ShuffleFileGroup ,并将数据写入对应的磁盘文件内;
- 当 Executor 的 CPU core 执行完一批 Task ,接着执行下一批 Task 时,下一批 Task 就会复用之前已有的 ShuffleFileGroup ,包括其中的磁盘文件。也就是说,此时 Task 会将数据写入已有的磁盘文件中,而不会写入新的磁盘文件中。因此,consolidate 机制允许不同的 Task 复用同一批磁盘文件,这样就可以有效将多个 Task 的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升 Shuffle Write的性能;
- 假设第二个 Stage 有100个 Task ,第一个 Stage 有 50 个 Task ,总共还是有 10 个 Executor,每个 Executor 执行5个 Task 。那么原本使用未经优化的 HashShuffleManager 时,每个 Executor 会产生500个磁盘文件,所有 Executor 会产生 5000 个磁盘文件的。但是此时经过优化之后,每个 Executor 创建的磁盘文件的数量的计算公式为:CPU Core 的数量 * 下一个 Stage 的 Task 数量。也就是说,每个 Executor 此时只会创建 100 个磁盘文件,所有 Executor 只会创建 1000 个磁盘文件。
SortShuffleManager
普通运行机制

- 首先数据会先写入一个内存数据结构中,此时根据不同的 Shuffle 算子,可能选用不同的数据结构。如果是 reduceBy Key 这种聚合类的 Shuffle 算 子,那么会选用 Map数据结构,一边通过 Map 进行聚合,一边写入内存;如果是 join 这种普通的 Shuffle 算子,那么会选用 Array 数据结构,直接写入内存。接着,每写一条数据进入内存数据结构之 后,就会判断一下,是否达到了某个临界阈值。如果达到临界阈值的话,那么就会尝试将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构;
- 在溢写到磁盘文件之前,会先根据 Key 对内存数据结构中已有的数据进行排序。排序过后,会分批将数 据写入磁盘文件。默认的 batch 数量是 10000 条,也就是说,排序好的数据,会以每批 1 万条数据的 形式分批写入磁盘文件。写入磁盘文件是通过 Java 的 BufferedOutputStream 实现的。BufferedOutputStream 是 Java 的缓冲输出流,首先会将数据缓冲在内存中,当内存缓冲满溢之后再 一次写入磁盘文件中,这样可以减少磁盘 IO 次数,提升性能;
- Task 将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个临时文 件。最后会将之前所有的临时磁盘文件都进行合并,这就是 Merge 过程,此时会将之前所有临时磁盘 文件中的数据读取出来,然后依次写入最终的磁盘文件之中。此外,由于一个 Task 就只对应一个磁盘 文件,也就意味着该 Task 为下游 Stage 的 Task 准备的数据都在这一个文件中,因此还会单独写一份索引 文件,其中标识了下游各个 Task 的数据在文件中的 Start offset 与 End offset;
- SortShuffleManager 由于有一个磁盘文件 Merge 的过程,因此大大减少了文件数量。比如第一个 Stage 有 50 个 Task ,总共有 10 个 Executor ,每个 Executor 执行 5 个 Task ,而第二个 Stage 有 100 个 Task 。由于每 个 Task 最终只有一个磁盘文件,因此此时每个 Executor 上只有 5 个磁盘文件,所有 Executor 只有 50 个磁 盘文件。
bypass 运行机制
 文章来源:https://www.toymoban.com/news/detail-402763.html
文章来源:https://www.toymoban.com/news/detail-402763.html
- Task 会为每个下游 Task 都创建一个临时磁盘文件,并将数据按 Key 进行 Hash 然后根据 Key 的 Hash 值,将 Key 写入对应的磁盘文件之中。写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件;
- 该过程的磁盘写机制其实跟未经优化的 HashShuffleManager 是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的 HashShuffleManager 来说,Shuffle Read的性能会更好;
- 而该机制与普通 SortShuffleManager 运行机制的不同在于:磁盘写机制不同、不会进行排序。启用该机制的最大好处在于,Shuffle Write 过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
SortShuffleManager 源码说明
执行 runTask
org.apache.spark.scheduler.Task
final def run(
taskAttemptId: Long,
attemptNumber: Int,
metricsSystem: MetricsSystem): T = {
SparkEnv.get.blockManager.registerTask(taskAttemptId)
................. 中间省略部分代码 ....................
try {
/**
* @Author: Small_Ran
* @Date: 2022/6/20
* @Description: 开始运行 Task(ResultTask、ShuffleMapTask)
*/
runTask(context)
} catch {
case e: Throwable =>
// Catch all errors; run task failure callbacks, and rethrow the exception.
try {
context.markTaskFailed(e)
} catch {
case t: Throwable =>
e.addSuppressed(t)
}
context.markTaskCompleted(Some(e))
throw e
} finally {
................. 中间省略部分代码 ....................
}
}
org.apache.spark.scheduler.ResultTask
override def runTask(context: TaskContext): U = {
// Deserialize the RDD and the func using the broadcast variables.
val threadMXBean = ManagementFactory.getThreadMXBean
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
val ser = SparkEnv.get.closureSerializer.newInstance()
/**
* @Author: Small_Ran
* @Date: 2022/6/20
* @Description: ResultTask 是 JOb 的最后一个环节;主要的作用就是输出结果
* 包括:
* 1、collect 收集结果到 Driver
* 2、foreach 打印输出
* 3、saveAsTextFile 写出到外部系统 HDFS、MySQL、Hive
*/
val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0L
func(context, rdd.iterator(partition, context))
}
注:接下来主要说明 ShuffleMapTask 的实现方式文章来源地址https://www.toymoban.com/news/detail-402763.html
选择 Shuffle 写入器
org.apache.spark.scheduler.ShuffleMapTask.runTask(context: TaskContext)
// 这里的 shuffleManager 就是SparkContext初始化中默认值 manager = org.apache.spark.shuffle.sort.SortShuffleManager
val manager = SparkEnv.get.shuffleManager
// 获取 Shuffle 选择器(SerializedShuffleHandle、BypassMergeSortShuffleHandle、BaseShuffleHandle)
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
org.apache.spark.shuffle.sort.SortShuffleManager
override def getWriter[K, V](
handle: ShuffleHandle,
mapId: Int,
context: TaskContext): ShuffleWriter[K, V] = {
numMapsForShuffle.putIfAbsent(
handle.shuffleId, handle.asInstanceOf[BaseShuffleHandle[_, _, _]].numMaps)
// 根据条件判断选择不同的 ShuffleManager,handle值是通过上面的 registerShuffle 方法进行判断
val env = SparkEnv.get
handle match {
// 不需要进行 Map 阶段的预聚合、Partition 数量小于16777216
case unsafeShuffleHandle: SerializedShuffleHandle[K @unchecked, V @unchecked] =>
new UnsafeShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
context.taskMemoryManager(),
unsafeShuffleHandle,
mapId,
context,
env.conf)
// 不需要进行 Map 阶段的预聚合、Partition 数量小于 200,返回 BypassMergeSortShuffleHandle 对象
case bypassMergeSortHandle: BypassMergeSortShuffleHandle[K @unchecked, V @unchecked] =>
new BypassMergeSortShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
bypassMergeSortHandle,
mapId,
context,
env.conf)
// 其他情况,通用情况
case other: BaseShuffleHandle[K @unchecked, V @unchecked, _] =>
new SortShuffleWriter(shuffleBlockResolver, other, mapId, context)
}
}
ShuffleManager 选择判断
org.apache.spark.shuffle.sort.SortShuffleManager
override def registerShuffle[K, V, C](
shuffleId: Int,
numMaps: Int,
dependency: ShuffleDependency[K, V, C]): ShuffleHandle = {
// 对 BypassMergeSortShuffleHandle 进行的判断
if (SortShuffleWriter.shouldBypassMergeSort(conf, dependency)) {
// If there are fewer than spark.shuffle.sort.bypassMergeThreshold partitions and we don't
// need map-side aggregation, then write numPartitions files directly and just concatenate
// them at the end. This avoids doing serialization and deserialization twice to merge
// together the spilled files, which would happen with the normal code path. The downside is
// having multiple files open at a time and thus more memory allocated to buffers.
new BypassMergeSortShuffleHandle[K, V](
shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
// 对 SerializedShuffleHandle 进行的判断
} else if (SortShuffleManager.canUseSerializedShuffle(dependency)) {
// Otherwise, try to buffer map outputs in a serialized form, since this is more efficient:
new SerializedShuffleHandle[K, V](
shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else {
// Otherwise, buffer map outputs in a deserialized form:
new BaseShuffleHandle(shuffleId, numMaps, dependency)
}
}
org.apache.spark.shuffle.sort.SortShuffleWriter
def shouldBypassMergeSort(conf: SparkConf, dep: ShuffleDependency[_, _, _]): Boolean = {
// We cannot bypass sorting if we need to do map-side aggregation.
// 首先使用 bypass 运行机制的前提是,在map阶段是否存在预聚合操作(Combine)
if (dep.mapSideCombine) {
require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")
false
} else {
// 这里就是判断是否使用 bypass 运行机制,如果任务数量(分区数量) <= 200(参数:spark.shuffle.sort.bypassMergeThreshold)则使用 bypass 运行机制。
val bypassMergeThreshold: Int = conf.getInt("spark.shuffle.sort.bypassMergeThreshold", 200)
dep.partitioner.numPartitions <= bypassMergeThreshold
}
}
org.apache.spark.shuffle.sort.SortShuffleManager
def canUseSerializedShuffle(dependency: ShuffleDependency[_, _, _]): Boolean = {
val shufId = dependency.shuffleId
val numPartitions = dependency.partitioner.numPartitions
// 判断支不支持序列化器
if (!dependency.serializer.supportsRelocationOfSerializedObjects) {
log.debug(s"Can't use serialized shuffle for shuffle $shufId because the serializer, " +
s"${dependency.serializer.getClass.getName}, does not support object relocation")
false
// 判断是否有聚合操作
} else if (dependency.aggregator.isDefined) {
log.debug(
s"Can't use serialized shuffle for shuffle $shufId because an aggregator is defined")
false
// 判断分区数是否大于16777216
} else if (numPartitions > MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE) {
log.debug(s"Can't use serialized shuffle for shuffle $shufId because it has more than " +
s"$MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE partitions")
false
} else {
log.debug(s"Can use serialized shuffle for shuffle $shufId")
true
}
}
ShuffleManager 读写数据
org.apache.spark.scheduler.ShuffleMapTask
/**
* @Author: Small_Ran
* @Date: 2022/6/20
* @Description: rdd 计算的核心方法就是 iterator 方法
* SortShuffleWriter 的 write 方法可以分为几个步骤:
* 1、将上游 RDD 计算出的数据(通过调用 rdd.iterator方法)写入内存缓冲区,在写的过程中如果超过内存阈值就会溢写磁盘文件(可能会写多个文件);
* 2、最后将溢写的文件和内存中剩余的数据一起进行归并排序后写入到磁盘中形成一个大的数据文件(按照 Key 分区排序);
* 3、在归并排序后写的过程中,每写一个分区就会手动刷写一遍,并记录下这个分区数据在文件中的位移;
* 4、最后写完一个 Task 的数据后,磁盘上会有两个文件:数据文件和记录每个 reduce 端 partition 数据位移的索引文件;
*
*/
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
org.apache.spark.shuffle.sort.SortShuffleWriter
override def write(records: Iterator[Product2[K, V]]): Unit = {
// 获取一个排序器,根据是否需要 map 端聚合传递不同的参数
sorter = if (dep.mapSideCombine) {
require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")
new ExternalSorter[K, V, C](
context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else {
// In this case we pass neither an aggregator nor an ordering to the sorter, because we don't
// care whether the keys get sorted in each partition; that will be done on the reduce side
// if the operation being run is sortByKey.
new ExternalSorter[K, V, V](
context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
// 将数据插入排序器中,这个过程或溢写出多个磁盘文件
sorter.insertAll(records)
// Don't bother including the time to open the merged output file in the shuffle write time,
// because it just opens a single file, so is typically too fast to measure accurately
// (see SPARK-3570).
// 根据 ShuffleID 和分区 ID 获取一个磁盘文件名,MapId 就是 ShuffleMap 端 RDD 的 PartitionID
// 将多个溢写的磁盘文件和内存中的排序数据进行归并排序并写到一个文件中,同时返回每个reduce端分区的数据在这个文件中的位移
val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
// 将索引写入一个索引文件,并将数据文件的文件名由临时文件名改成正式的文件名;为输出文件名加一个uuid后缀
val tmp = Utils.tempFileWith(output)
try {
val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID)
// 这一步将溢写到的磁盘的文件和内存中的数据进行归并排序,并溢写到一个文件中,这一步写的文件是临时文件名
val partitionLengths = sorter.writePartitionedFile(blockId, tmp)
// 写入索引文件,使用 File.renameTo 方法将临时索引和临时数据文件重命名为正常的文件名
shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp)
// 返回一个状态对象,包含 shuffle 服务 Id 和各个分区数据在文件中的位移
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)
} finally {
if (tmp.exists() && !tmp.delete()) {
logError(s"Error while deleting temp file ${tmp.getAbsolutePath}")
}
}
}
org.apache.spark.util.collection.ExternalSorter
def insertAll(records: Iterator[Product2[K, V]]): Unit = {
// TODO: stop combining if we find that the reduction factor isn't high
val shouldCombine = aggregator.isDefined
if (shouldCombine) {
// Combine values in-memory first using our AppendOnlyMap
val mergeValue = aggregator.get.mergeValue
val createCombiner = aggregator.get.createCombiner
var kv: Product2[K, V] = null
val update = (hadValue: Boolean, oldValue: C) => {
if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2)
}
while (records.hasNext) {
addElementsRead()
kv = records.next()
// 向内存缓冲中插入一条数据,map的键为(partitionId, key)
map.changeValue((getPartition(kv._1), kv._1), update)
// 每写入一条数据就检查一遍内存。如果缓冲超过阈值,就会溢写到磁盘生成一个文件
maybeSpillCollection(usingMap = true)
}
} else {
// Stick values into our buffer
while (records.hasNext) {
addElementsRead()
val kv = records.next()
buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C])
maybeSpillCollection(usingMap = false)
}
}
}
到了这里,关于Spark Shuffle 过程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!