PIDNet是2023年发表在CVPR上的实时语义分割网络,在推理速度和准确性之间实现了最佳平衡,其中该系列的PIDNet-S在Cityscapes 测试集上达到93.2 FPS + 78.6% mIOU。
论文和开源代码在这里。
解决的问题:传统双分支网络低层的细节信息和高层语义信息直接融合,会导致细节特征很容易被上下文信息淹没,即文中的overshoot。
思路:提出一种三分支网络架构,分别解析细节、上下文和边界信息,并设计边界注意力引导融合模块(Bag)融合三个分支的特征。
为了在推理速度和准确度之间取得最佳平衡,研究人员投入了大量精力来重新设计网络架构,可以概括为:轻量级编码器和解码器(卷积分解及分组卷积)、多尺度输入以及双分支网络。具体而言,SwiftNet使用一个低分辨率输入来获得高级语义,使用另一个高分辨率输入来为其轻量级解码器提供足够的细节。DFANet通过修改基于深度可分离卷积的Xception的架构,引入了一种轻量级主干,并缩减了输入大小以提高推理速度。ShuffleSeg采用Shuffle Net作为其主干,它结合了通道混洗和分组卷积,以降低计算成本。然而,这些网络中的大多数仍然是编码器-解码器架构的形式,并且需要信息流通过深层编码器,然后反向通过解码器,给这些模型带来了很大的延迟。此外,由于GPU上深度可分离卷积的优化还不成熟,传统卷积尽管具有更多FLOP和参数,但速度更快。
在语义分割任务中,上下文依赖性可以通过大的感受野来提取,而精确的边界和小范围物体识别则依赖于空间细节信息。在双分支网络如DDRNet中,细节分支的输出分辨率为上下文分支的8倍(BiSeNet中为4倍),它们的直接融合将不可避免地导致过冲现象(overshoot),即物体边界很容易被其周围的像素淹没,小规模物体可能被相邻的大物体淹没。文中用下图来解释过冲现象:
PID控制器包含3个具有互补功能的组件:比例(P)控制器表示当前误差,积分(I)控制器累积先前误差,微分(D)控制器预测未来误差变化。在双分支网络中,上下文分支通过级联卷积层或池化层(其实也就是下采样操作)不断聚合从局部到全局的语义信息,以解析像素之间的长距离依赖关系,而细节分支特征图维持高分辨率以保留单个像素的位置信息。因此细节分支和上下文分支可以被视为空间域中的比例和积分控制器,这解释了分割任务中存在过冲问题的原因。
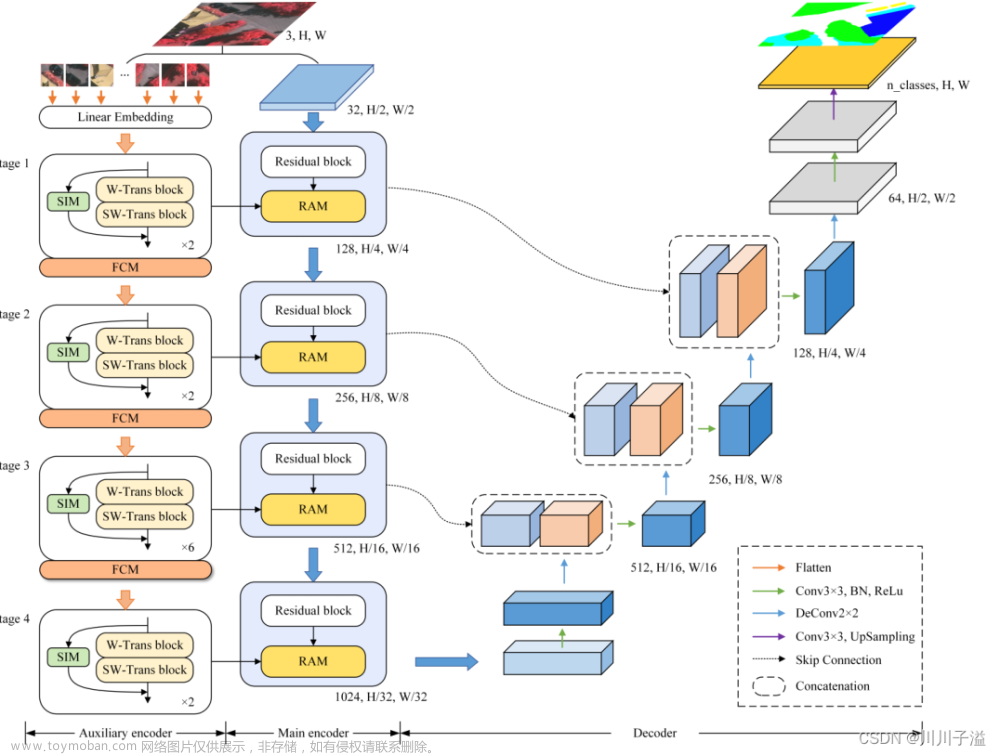
PIDNet网络结构

PIDNet主要包含以下结构:
- 绿色的比例(P)分支解析并保存高分辨率特征图中的细节信息;
- 蓝色的积分(I)分支聚合上下文信息,以解析远程依赖关系;
- 灰色的导数(D)分支提取高频特征以预测边界区域。
PIDNet的骨干网络采用级联的残差块,也就是ResNet中的BasicBlock和Bottleneck,首先我们介绍P分支中的Pag模块。
Pag:选择性学习高级语义
在PIDNet中,I分支提供的丰富和准确的语义信息对于P分支的细节解析至关重要,P分支包含相对较少的层和通道。因此,可以将I分支作为其他两个分支的备份,使其能够向它们提供所需的信息。
如上图,先对I分支和P分支的输入y和x分别做1*1卷积和BN,再将y上采样(因为特征图y的大小为原图的1/16,x为1/8),两者相乘后将结果做逐通道求和,再经过sigmoid得到结果σ,得到Pag的输出为σ * y + (1 - σ) *x
代码实现:
class PagFM(nn.Module):
def __init__(self, in_channels, mid_channels, after_relu=False, with_channel=False, BatchNorm=nn.BatchNorm2d):
super(PagFM, self).__init__()
self.with_channel = with_channel
self.after_relu = after_relu
self.f_x = nn.Sequential(
nn.Conv2d(in_channels, mid_channels,
kernel_size=1, bias=False),
BatchNorm(mid_channels)
)
self.f_y = nn.Sequential(
nn.Conv2d(in_channels, mid_channels,
kernel_size=1, bias=False),
BatchNorm(mid_channels)
)
if with_channel:
self.up = nn.Sequential(
nn.Conv2d(mid_channels, in_channels,
kernel_size=1, bias=False),
BatchNorm(in_channels)
)
if after_relu:
self.relu = nn.ReLU(inplace=True)
def forward(self, x, y):
input_size = x.size()
if self.after_relu:
y = self.relu(y)
x = self.relu(x)
y_q = self.f_y(y)
y_q = F.interpolate(y_q, size=[input_size[2], input_size[3]],
mode='bilinear', align_corners=False)##上采样到与x分辨率相同
x_k = self.f_x(x)
if self.with_channel:
sim_map = torch.sigmoid(self.up(x_k * y_q))
else:
sim_map = torch.sigmoid(torch.sum(x_k * y_q, dim=1).unsqueeze(1))
##dim=1:逐通道相加,假设x_k * y_q的shape为[4, 32, 32, 64],相加后shape变为[4, 32, 64],再通过unsqueeze(1)升维为[4, 1, 32, 64]
y = F.interpolate(y, size=[input_size[2], input_size[3]],
mode='bilinear', align_corners=False)##上采样到与x分辨率相同
x = (1-sim_map)*x + sim_map*y
return x
PAPPM:上下文特征快速聚合
作者改进了DDRNet中用于聚合不同尺度上下文信息的DAPPM模块,改变DAPPM中的连接并使其并行化,同时缩减了每个尺度的通道数以提高推理速度,提出一种新的上下文信息聚合模块,称为并行聚合PPM(PAPPM)。
代码实现:
class PAPPM(nn.Module):
def __init__(self, inplanes, branch_planes, outplanes, BatchNorm=nn.BatchNorm2d):
super(PAPPM, self).__init__()
bn_mom = 0.1
self.scale1 = nn.Sequential(nn.AvgPool2d(kernel_size=5, stride=2, padding=2),
BatchNorm(inplanes, momentum=bn_mom),
nn.ReLU(inplace=True),
nn.Conv2d(inplanes, branch_planes, kernel_size=1, bias=False),
)
self.scale2 = nn.Sequential(nn.AvgPool2d(kernel_size=9, stride=4, padding=4),
BatchNorm(inplanes, momentum=bn_mom),
nn.ReLU(inplace=True),
nn.Conv2d(inplanes, branch_planes, kernel_size=1, bias=False),
)
self.scale3 = nn.Sequential(nn.AvgPool2d(kernel_size=17, stride=8, padding=8),
BatchNorm(inplanes, momentum=bn_mom),
nn.ReLU(inplace=True),
nn.Conv2d(inplanes, branch_planes, kernel_size=1, bias=False),
)
self.scale4 = nn.Sequential(nn.AdaptiveAvgPool2d((1, 1)),
BatchNorm(inplanes, momentum=bn_mom),
nn.ReLU(inplace=True),
nn.Conv2d(inplanes, branch_planes, kernel_size=1, bias=False),
)##全局平均池化
self.scale0 = nn.Sequential(
BatchNorm(inplanes, momentum=bn_mom),
nn.ReLU(inplace=True),
nn.Conv2d(inplanes, branch_planes, kernel_size=1, bias=False),
)##scale0不做池化
self.scale_process = nn.Sequential(
BatchNorm(branch_planes*4, momentum=bn_mom),
nn.ReLU(inplace=True),
nn.Conv2d(branch_planes*4, branch_planes*4, kernel_size=3, padding=1, groups=4, bias=False),
)
self.compression = nn.Sequential(
BatchNorm(branch_planes * 5, momentum=bn_mom),
nn.ReLU(inplace=True),
nn.Conv2d(branch_planes * 5, outplanes, kernel_size=1, bias=False),
)
self.shortcut = nn.Sequential(
BatchNorm(inplanes, momentum=bn_mom),
nn.ReLU(inplace=True),
nn.Conv2d(inplanes, outplanes, kernel_size=1, bias=False),
)
def forward(self, x):
width = x.shape[-1]
height = x.shape[-2]
scale_list = []
x_ = self.scale0(x)
scale_list.append(F.interpolate(self.scale1(x), size=[height, width],
mode='bilinear', align_corners=algc)+x_)
scale_list.append(F.interpolate(self.scale2(x), size=[height, width],
mode='bilinear', align_corners=algc)+x_)
scale_list.append(F.interpolate(self.scale3(x), size=[height, width],
mode='bilinear', align_corners=algc)+x_)
scale_list.append(F.interpolate(self.scale4(x), size=[height, width],
mode='bilinear', align_corners=algc)+x_)
scale_out = self.scale_process(torch.cat(scale_list, 1))
out = self.compression(torch.cat([x_,scale_out], 1)) + self.shortcut(x)
return out
Bag:平衡细节和上下文
作者设计了一个边界注意力引导融合模块(Bag)来融合三个分支的特征,以边界信息指导细节分支§和上下文分支(I)的融合。上下文分支可以提供准确的语义信息,但丢失了很多空间和几何细节,尤其是边界区域和小物体,而细节分支更好的保留了空间细节信息,Bag模块使得模型沿着边界区域更加信任细节分支,在对象内部区域则更信任上下文特征。
当σ > 0.5时,模型更信任细节特征,小于0.5时更信任上下文特征。
代码实现:
##Bag:
class Bag(nn.Module):
def __init__(self, in_channels, out_channels, BatchNorm=nn.BatchNorm2d):
super(Bag, self).__init__()
self.conv = nn.Sequential(
BatchNorm(in_channels),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1, bias=False)
)
def forward(self, p, i, d):
edge_att = torch.sigmoid(d)
return self.conv(edge_att*p + (1-edge_att)*i)
##Light-Bag:
class Light_Bag(nn.Module):
def __init__(self, in_channels, out_channels, BatchNorm=nn.BatchNorm2d):
super(Light_Bag, self).__init__()
self.conv_p = nn.Sequential(
nn.Conv2d(in_channels, out_channels,
kernel_size=1, bias=False),
BatchNorm(out_channels)
)
self.conv_i = nn.Sequential(
nn.Conv2d(in_channels, out_channels,
kernel_size=1, bias=False),
BatchNorm(out_channels)
)
def forward(self, p, i, d):
edge_att = torch.sigmoid(d)
p_add = self.conv_p((1-edge_att)*i + p)
i_add = self.conv_i(i + edge_att*p)
return p_add + i_add
分割头S/B-Head
分割头的结构比较简单,主要作用是计算辅助损失,文中损失函数的定义如下:
Loss = λ₀l₀ + λ₁l₁ + λ₂l₂ + λ₃l₃
其中l₀是额外的语义损失,l₁是加权二元交叉熵损失,l₂和l₃是边界感知CE loss,在文中设置的权重为λ₀ = 0.4,λ₁ = 20, λ₂ = λ₃ = 1
分割头的代码实现:
class segmenthead(nn.Module):
def __init__(self, inplanes, interplanes, outplanes, scale_factor=None):
super(segmenthead, self).__init__()
self.bn1 = BatchNorm2d(inplanes, momentum=bn_mom)
self.conv1 = nn.Conv2d(inplanes, interplanes, kernel_size=3, padding=1, bias=False)
self.bn2 = BatchNorm2d(interplanes, momentum=bn_mom)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(interplanes, outplanes, kernel_size=1, padding=0, bias=True)
self.scale_factor = scale_factor
def forward(self, x):
x = self.conv1(self.relu(self.bn1(x)))
out = self.conv2(self.relu(self.bn2(x)))
if self.scale_factor is not None:
height = x.shape[-2] * self.scale_factor
width = x.shape[-1] * self.scale_factor
out = F.interpolate(out,
size=[height, width],
mode='bilinear', align_corners=algc)
return out
训练和结果
由于论文中的训练的代码比较复杂,博主功力不够看着比较费劲,就没有用论文中的训练策略,而是参考一位大佬的语义分割系列25-BiSeNetV2(pytorch实现)和语义分割系列26-VIT+SETR——Transformer结构如何在语义分割中大放异彩来进行训练和推理可视化的。论文中采用的是yacs库以yaml格式的文件来配置模型的各种参数,包括训练和测试等等的参数,为模型复现、调整参数提供了很多便利,大伙可以一起学习学习,yacs传送门文章来源:https://www.toymoban.com/news/detail-402774.html
下面是博主用PIDNet在camvid数据集上的分割结果,训练时没有使用辅助损失,所以分割精度也不是特别高。 文章来源地址https://www.toymoban.com/news/detail-402774.html
文章来源地址https://www.toymoban.com/news/detail-402774.html
到了这里,关于实时语义分割---PIDNet论文笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!