介绍
为什么要用Ceph
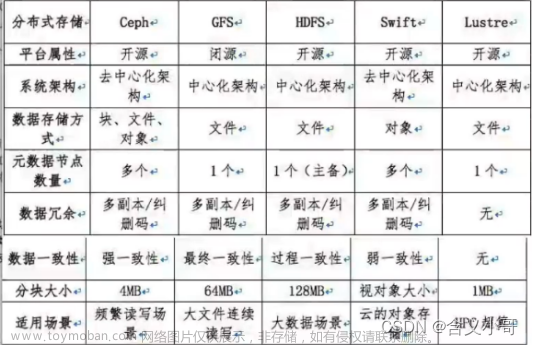
Ceph是当前非常流行的开源分布式存储系统,具有高扩展性、高性能、高可靠性 等优点,同时提供块存储服务(rbd)、对象存储服务(rgw)以及文件系统存储服务(cephfs),Ceph在存储的时候充分利用存储节点的计算能力,在存储每一个数据时 都会通过计算得出该数据的位置,尽量的分布均衡。。目前也是OpenStack的主流 后端存储,随着OpenStack在云计算领域的广泛使用,ceph也变得更加炙手可热。 国内目前使用ceph搭建分布式存储系统较为成功的企业有x-sky,深圳元核云,上海 UCloud等三家企业。
Ceph架构介绍



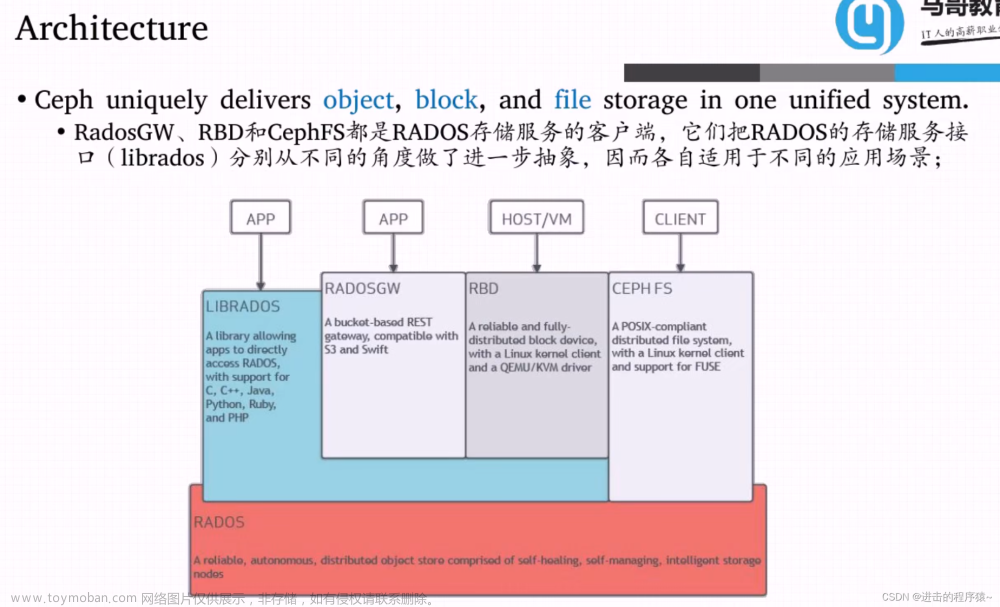
Ceph使用RADOS提供对象存储,通过librados封装库提供多种存储方式的文件和 对象转换。外层通过RGW(Object,有原生的API,而且也兼容Swift和S3的API, 适合单客户端使用)、RBD(Block,支持精简配置、快照、克隆,适合多客户端有 目录结构)、CephFS(File,Posix接口,支持快照,社会和更新变动少的数据,没 有目录结构不能直接打开)将数据写入存储。
-
高性能
a. 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布 均衡,并行度高
b.考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机 架感知等
c. 能够支持上千个存储节点的规模,支持TB到PB级的数据
-
高可扩展性
a. 去中心化
b. 扩展灵活
c. 随着节点增加而线性增长
-
特性丰富
a. 支持三种存储接口:块存储、文件存储、对象存储
b. 支持自定义接口,支持多种语言驱动
目前来说,ceph在开源社区还是比较热门的,但是更多的是应用于云计算的后端 存储。官方推荐使用ceph的对象式存储,速度和效率都比较高,而cephfs官方并 不推荐直接在生产中使用。以上介绍的只是ceph的沧海一粟,ceph远比上面介绍 的要复杂,而且支持很多特性,比如使用纠删码就行寻址,所以大多数在生产环境 中使用ceph的公司都会有专门的团队对ceph进行二次开发,ceph的运维难度也 比较大。但是经过合理的优化之后,ceph的性能和稳定性都是值得期待的。
Ceph核心概念
-
RADOS
可靠的、自动化的、分布式对象存储系统。RADOS是Ceph集群的精华,用户 实现数据分配、Failover等集群操作。
-
Librados
上层的RBD、RGW和CephFS都是通过librados访问的,目前提供PHP、Ruby、 Java、Python、C和C++支持。
-
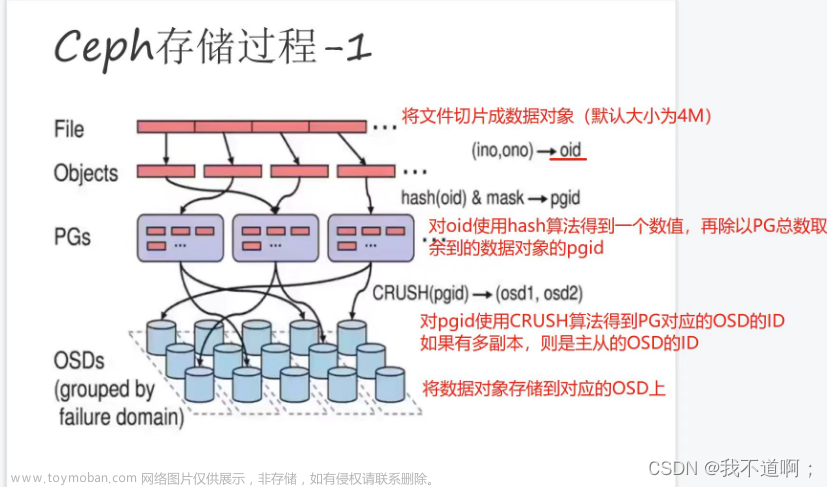
Crush
Crush算法在一致性哈希基础上很好的考虑了容灾域的隔离,使得Ceph能够 实现各类负载的副本放置规则,例如跨机房、机架感知等。同时,Crush算法 有相当强大的扩展性,理论上可以支持数千个存储节点,这为Ceph在大规模 云环境中的应用提供了先天的便利。
-
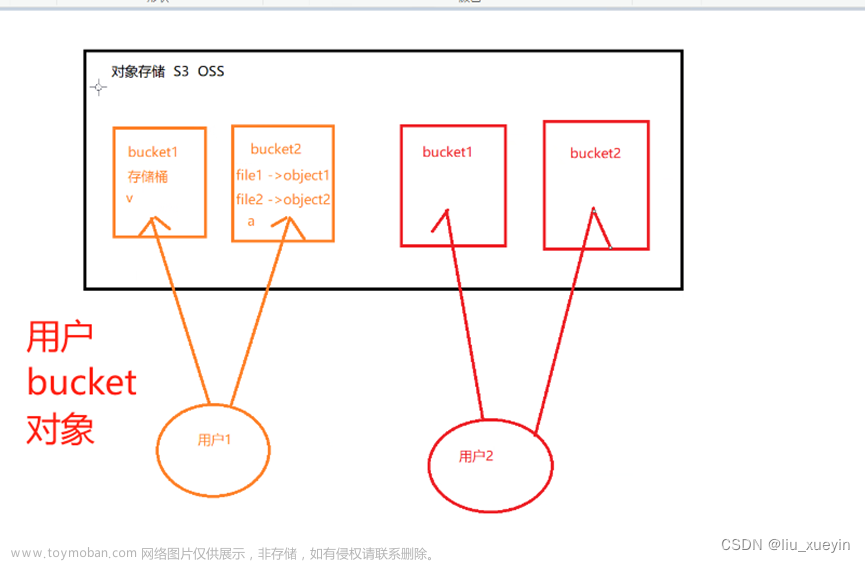
Pool
Pool是存储对象的逻辑分区,它规定了数据冗余的类型和对应的副本分布策 略,默认存储3份副本;支持两种类型:副本(replicated)和 纠删码( Erasure Code);
-
PG
放置策略组,它是对象的集合,该集合里的所有对象都具有相同的放置策略, 简单点说就是相同PG内的对象都会放到相同的硬盘上,PG是 ceph的逻辑概 念,服务端数据均衡和恢复的最小粒度就是PG,一个PG包含多个OSD。引入 PG这一层其实是为了更好的分配数据和定位数据;
-
Object
简单来说块存储读写快,不利于共享,文件存储读写慢,利于共享。能否弄一 个读写快,利于共享的出来呢。于是就有了对象存储。最底层的存储单元,包 含元数据和原始数据。
-
ceph资源划分

-
ceph对象元数据

Ceph核心组件
-
OSD
OSD是负责物理存储的进程,一般配置成和磁盘一一对应,一块磁盘启动一个 OSD进程。主要功能是存储数据、复制数据、平衡数据、恢复数据,以及与其 它OSD间进行心跳检查,负责响应客户端请求返回具体数据的进程等;
-
Pool、PG和OSD的关系:
一个Pool里有很多PG;
一个PG里包含一堆对象,一个对象只能属于一个PG;
PG有主从之分,一个PG分布在不同的OSD上(针对三副本类型);
-
pool PG

-
OSD PG pool

-
Monitor
一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据, 用来保存OSD的元数据。负责监视整个Ceph集群运行的Map视图(如OSD Map、Monitor Map、PG Map和CRUSH Map),维护集群的健康状态,维护展 示集群状态的各种图表,管理集群客户端认证与授权;生产中建议最少要用3 个Monitor,基数个的Monitor组成组件来做高可用。
-
MDS
CephFS服务依赖的元数据服务。负责保存文件系统的元数据,管理目录结构。 对象存储和块设备存储不需要元数据服务;
-
Mgr
实现 ceph 集群的管理,为外界提供统一的入口。
-
RGW
Ceph对外提供的对象存储服务,接口与S3和Swift兼容。
-
Admin
Ceph常用管理接口通常都是命令行工具,如rados、ceph、rbd等命令,另外 Ceph还有可以有一个专用的管理节点,在此节点上面部署专用的管理工具来 实现近乎集群的一些管理工作,如集群部署,集群组件管理等。
Ceph三种存储类型
-
块存储(RBD)
优点:
a.通过Raid与LVM等手段,对数据提供了保护;
b.多块廉价的硬盘组合起来,提高容量;
c.多块磁盘组合出来的逻辑盘,提升读写效率;缺点:
a.采用SAN架构组网时,光纤交换机,造价成本高;
b.主机之间无法共享数据;使用场景
a.docker容器、虚拟机磁盘存储分配;
b.日志存储;
c.文件存储; -
文件存储(CephFS)
优点:
a.造价低,随便一台机器就可以了;
b.方便文件共享;缺点:
a.读写速率低;
b.传输速率慢;使用场景
a.日志存储;
b.FTP、NFS;
c.其它有目录结构的文件存储 -
对象存储(Object)(适合更新变动较少的数据)
优点:
a.具备块存储的读写高速;
b.具备文件存储的共享等特性;使用场景
a.图片存储;
b.视频存储;
如何将ssd作为hdd的缓存池
-
缓存池原理
缓存分层特性也是在Ceph的Firfly版中正式发布的,这也是Ceph的Firefly版本中 被谈论最多的一个特性。缓存分层是在更快的磁盘(通常是SSD),上创建一 个Ceph池。这个缓存池应放置在一个常规的复制池或erasure池的前端,这 样所有的客户端I/O操作都首先由缓存池处理。之后,再将数据写回到现有的 数据池中。客户端能够在缓存池上享受高性能,而它们的数据显而易见最终是 被写入到常规池中的。
一般来说,缓存层构建在昂贵/速度更快的SSD磁盘上,这样才能为客户提供更好 的I/O性能。在缓存池后端通常是存储层,它由复制或者erasure类型的HDD 组成。在这种类型的设置中,客户端将I/O请求提交到缓存池,不管它是一个 读或写操作,它的请求都能够立即获得响应。速度更快的缓存层为客户端请求 提供服务。一段时间后,缓存层将所有数据写回备用的存储层,以便它可以缓 存来自客户端的新请求。在缓存层和存储层之间的数据迁移都是自动触发且对 客户端是透明的。缓存分层能以两种模式进行配置。

-
writeback模式:
写操作时,写入缓存池。基于缓存层flushing/evicting策略,数据将从缓存层 迁移到存储层,并由缓存分层代理将其从缓存层中删除。
读操作时,由缓存分层代理将数据从存储层迁移到缓存层,然后再把它提供给 客户。直到数据变得不再活跃或成为冷数据,否则它将一直保留在缓存层 中。 -
read-only模式:
写操作不涉及缓存分层,所有的客户端写都在存储层上完成。
读操作时,在处理来自客户端的读操作时,缓存分层代理将请求的数据从存储 层复制到缓存层。基于你为缓存层配置的策略,不活跃的对象将会从缓存 层中删除。这种方法非常适合多个客户端需要读取大量类似数据的场景。缓存层是在速度更快的物理磁盘(通常是SSD),上实现的,它在使用HDD构建 的速度较慢的常规池前部署一个快速的缓存层。在本节中,我们将创建两个独 立的池(一个缓存池和一个常规),分别用作缓存层和存储层。

部署
机器需求
- 最少三台Centos7系统虚拟机用于部署Ceph集群
- 硬件配置:2C4G
- 另外每台机器最少挂载三块硬盘
安装前环境准备
-
服务器初始化(参考初始化文档)
-
安装需要工具
yum install createrepo -y yum install epel-release -y yum install lttng-ust -y -
关闭NetworkManager
systemctl disable NetworkManager systemctl stop NetworkManager -
升级系统内核
#查看内核版本 uname -r cd 内核文件/ yum -y install kernel-ml-5.7.8-1.el7.elrepo.x86_64.rpm kernel-ml-devel-5.7.8-1.el7.elrepo.x86_64.rpm #调整默认启动内核 cat /boot/grub2/grub.cfg | grep menuentry grub2-set-default "CentOS Linux (5.7.8-1.el7.elrepo.x86_64) 7 (Core)" #查看是否设置成功 grub2-editenv list reboot -
主机名与IP对应关系(必须配置主机名映射)
vim /etc/hosts 192.168.66.31 ceph-node1 192.168.66.32 ceph-node2 192.168.66.33 ceph-node3 -
ceph-node1操作节点上安装ceph的yum源共享
安装源
yum install httpd #上传软件包\ceph到/var/www/html/下 #启动httpd systemctl restart httpd systemctl enable httpd #更新yum源 createrepo --update /var/www/html/ceph/rpm-nautilus #(官方yum源 vim /etc/yum.repos.d/ceph.repo [Ceph] name=Ceph packages for $basearch baseurl=http://mirrors.163.com/ceph/rpm-nautilus/el7/$basearch enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://download.ceph.com/keys/release.asc priority=1 [Ceph-noarch] name=Ceph noarch packages baseurl=http://mirrors.163.com/ceph/rpm-nautilus/el7/noarch enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://download.ceph.com/keys/release.asc priority=1 [ceph-source] name=Ceph source packages baseurl=http://mirrors.163.com/ceph/rpm-nautilus/el7/SRPMS enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://download.ceph.com/keys/release.asc )编辑yum源文件
vim /etc/yum.repos.d/ceph.repo [Ceph] name=Ceph packages for $basearch baseurl=http://192.168.66.31/ceph/rpm-nautilus/el7/$basearch gpgcheck=0 priority=1 [Ceph-noarch] name=Ceph noarch packages baseurl=http://192.168.66.31/ceph/rpm-nautilus/el7/noarch gpgcheck=0 priority=1 [ceph-source] name=Ceph source packages baseurl=http://192.168.66.31/ceph/rpm-nautilus/el7/SRPMS gpgcheck=0 priority=1 [nfs-ganesha] name=nfs-ganesha baseurl=http://192.168.66.31/nfs-ganesha/el7/x86_64 gpgcheck=0 priority=1 [ceph-iscsi] name=ceph-iscsi noarch packages baseurl=http://192.168.66.31/ceph-iscsi/3/rpm/el7/noarch gpgcheck=0 priority=1 [ceph-iscsi-source] name=ceph-iscsi source packages baseurl=http://192.168.66.31/ceph-iscsi/3/rpm/el7/SRPMS gpgcheck=0 priority=1 [tcmu-runner] name=tcmu-runner baseurl=http://192.168.66.31/tcmu-runner/x86_64 gpgcheck=0 priority=1 [ceph-iscsi-conf] name=ceph-iscsi-config baseurl=http://192.168.66.31/ceph-iscsi-config/noarch gpgcheck=0 priority=1在每台node上执行
yum makecache -
安装基础ceph包每台node
yum -y install ceph ceph -v
安装Ceph集群
-
部署安装工具
安装 ceph-deploy在ceph-node1操作节点上
yum install -y ceph-deploy yum install python-setuptools -y ceph-deploy --version创建一个my-cluster目录,所有命令在此目录下进行ceph-node1操作节点上
mkdir /my-cluster cd /my-cluster控制端无密码连接所以节点和自己
ssh-keygen for i in 31 32 33; do ssh-copy-id root@192.168.66.$i; done -
创建Ceph集群,生成Ceph配置文件(建议是奇数)ceph-node1操作节点上
ceph-deploy new --public-network 对外网端 --cluster-network 192.168.66.0/24 ceph-node1 ceph-node2 ceph-node3 #--public-network没有就不写 #--cluster-network对内通行网端 #ceph-nodex mon节点允许删除存储池
ceph-node1操作节点上修改配置文件vim ceph.conf [global] ....... #允许删除存储池 mon_allow_pool_delete = true -
安装mon服务,生成monitor检测集群所使用的的秘钥ceph-node1操作节点上
ceph-deploy mon create-initial -
安装管理命令Ceph CLIceph-node1操作节点上
如前所示,我们执行admin的命令,要提供admin的key(–keyring ceph.client.admin.keyring)以及配置文件(-c ceph.conf)。在后续的运维中,我们经常 需要在某个node上执行admin命令。每次都提供这些参数比较麻烦。实际上,ceph 会默认地从/etc/ceph/中找keyring和ceph.conf。因此,我们可以把 ceph.client.admin.keyring和ceph.conf放到每个node的/etc/ceph/。ceph-deploy可 以帮做这些
ceph-deploy admin ceph-node1 ceph-node2 ceph-node3 -
添加osd(添加的磁盘必须是没有被处理过的裸盘)ceph-node1操作节点上
所有操作节点上初始化清空磁盘数据
ceph-volume lvm zap /dev/sdb /dev/sdc /dev/sdd ceph-deploy osd create --data /dev/sdb ceph-node1 ceph-deploy osd create --data /dev/sdc ceph-node1 ceph-deploy osd create --data /dev/sdd ceph-node1 ceph-deploy osd create --data /dev/sdb ceph-node2 ceph-deploy osd create --data /dev/sdc ceph-node2 ceph-deploy osd create --data /dev/sdd ceph-node2 ceph-deploy osd create --data /dev/sdb ceph-node3 ceph-deploy osd create --data /dev/sdc ceph-node3 ceph-deploy osd create --data /dev/sdd ceph-node3 -
检查Ceph群集状态。
ceph -s -
#使用盘+盘的方式所有节点磁盘创建固态+集群盘组
对固态进行分区
parted /dev/sdb mklabel gpt parted /dev/sdb mkpart primary 1 50% parted /dev/sdb mkpart primary 50% 100% #磁盘分区后的默认权限无法让ceph软件对其进行读写操作提权
chown ceph.ceph /dev/sdb1 chown ceph.ceph /dev/sdb2 vim /etc/udev/rules.d/70-sdb.rules ENV{DEVNAME}=="/dev/sdb1",OWNER="ceph",GROUP="ceph" ENV{DEVNAME}=="/dev/sdb2",OWNER="ceph",GROUP="ceph"创建OSD存储空间
ceph-deploy osd create --data /dev/sdc:/dev/sdb1 /dev/sdd:/dev/sdb2 ceph-node1 ceph-deploy osd create --data ceph-node2:/dev/sdc:/dev/sdb1 ceph-node2:/dev/sdd:/dev/sdb2 ceph-deploy osd create --data ceph-node3:/dev/sdc:/dev/sdb1 ceph-node3:/dev/sdd:/dev/sdb2#使用pool+pool的方式(后面说)
-
部署监控配置mgr,用于管理集群ceph-node1操作节点上
ceph-deploy mgr create ceph-node1 ceph-deploy mgr create ceph-node2 ceph-deploy mgr create ceph-node3 -
允许删除存储池以做
ceph-node1操作节点上修改配置文件
vim ceph.conf [global] ....... #允许删除存储池 mon_allow_pool_delete = true使用ceph-deploy推配置给所有节点
ceph-deploy --overwrite-conf config push ceph-node1 ceph-node2 ceph-node3所有节点重启ceph-mon服务
systemctl restart ceph-mon.target -
创建默认pool,ceph-node1操作节点上
```powershell
ceph osd pool create rbd 32 32
ceph osd pool application enable rbd rbd
```
-
检查状态
OSD状态
ceph osd tree ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.29279 root default -3 0.09760 host cephnode01 0 hdd 0.04880 osd.0 up 1.00000 1.00000 1 hdd 0.04880 osd.1 up 1.00000 1.00000 -5 0.09760 host cephnode02 2 hdd 0.04880 osd.2 up 1.00000 1.00000 3 hdd 0.04880 osd.3 up 1.00000 1.00000 -7 0.09760 host cephnode03 4 hdd 0.04880 osd.4 up 1.00000 1.00000 5 hdd 0.04880 osd.5 up 1.00000 1.00000整体运行状态
ceph -s cluster: id: a4c42290-00ac-4647-9856-a707d5f8f2fd health: HEALTH_OK services: mon: 3 daemons, quorum cephnode01,cephnode02,cephnode03 (age 18m) mgr: cephnode01(active, since 34m), standbys: cephnode03, cephnode02 mds: 3 up:standby osd: 6 osds: 6 up (since 27m), 6 in (since 27m) rgw: 1 daemon active (cephnode01) data: pools: 4 pools, 128 pgs objects: 187 objects, 1.2 KiB usage: 6.0 GiB used, 294 GiB / 300 GiB avail pgs: 128 active+clean检查集群健康状况的命令,后期用来查找故障
ceph health detail HEALTH_OKMonitor状态
ceph mon stat
Ceph Dashboard监控
-
所有节点节点安装
yum -y install ceph-mgr-dashboard -
配置ceph-node1操作节点上
禁用 SSL
ceph config set mgr mgr/dashboard/ssl false #生成并安装自签名的证书ssl #ceph dashboard create-self-signed-cert配置监听IP和 port
ceph config set mgr mgr/dashboard/server_addr 0.0.0.0 ceph config set mgr mgr/dashboard/server_port 8888 #IP 不设置,默认绑定 ::,禁用 ssl 之后,PORT 默认8080创建一个dashboard登录用户名密码
vim dashboard-password 123456 ceph dashboard ac-user-create admin -i ./dashboard-password administrator #更多操作,查看帮助 ceph dashboard -h -
开启功能ceph-node1操作节点上
ceph mgr module enable dashboard ceph mgr module disable dashboard(注意修改了配置,要先停,在开启) -
启用功能
rgw启用
#部署rgw #安装实现 ceph 集群的管理,为外界提供统一的入口,所有节点 yum install -y ceph-radosgw #创建rgw实例ceph-node1操作节点上 ceph-deploy rgw create ceph-node1 ceph-deploy rgw create ceph-node2 ceph-deploy rgw create ceph-node3#Dashboard中启用RGWceph-node1操作节点上 #创建rgw系统账户 radosgw-admin user create --uid=rgw --display-name=rgw --system #查看 radosgw-admin user info --uid=rgw #记下输出的access_key 和 secret_key的值 "access_key": "DK81962PKOT9MURYBL3Y", "secret_key": "OABnPhViCWlYtNCyXxTQ7sr6xUVAYvvSgrTiNUQE" #为Dashboard设置access_key 和 secret_key echo DK81962PKOT9MURYBL3Y > access_key echo OABnPhViCWlYtNCyXxTQ7sr6xUVAYvvSgrTiNUQE > secret_key ceph dashboard set-rgw-api-access-key -i ./access_key ceph dashboard set-rgw-api-secret-key -i ./secret_key #禁用SSL ceph dashboard set-rgw-api-ssl-verify False#检测 http://rgw-node:7480
cephfs启用ceph-node1操作节点上
#创建cephfs实例 ceph-deploy mds create ceph-node1 ceph-deploy mds create ceph-node2 ceph-deploy mds create ceph-node3 #创建cephfs池 ceph osd pool create cephfs_data 32 ceph osd pool create cephfs_metadata 32 #创建文件系统 ceph fs new cephfs cephfs_metadata cephfs_data #查看mds状态 ceph mds stat
-
查看服务访问方式,查看已开启模块信息ceph-node1操作节点上
ceph mgr services访问:http://ceph-node1:8888/
创建nfs存储
-
首先创建存储池nfs-hmtd
#创建在SSD上 #ceph osd pool create nfs-hmtd on-ssd ceph osd pool create nfs-hmtd 32 32 ceph osd pool application enable nfs-hmtd nfs -
部署NFS服务(这里我放在了appfor117\appfor210):
# ceph orch apply nfs *<svc_id>* *<pool>* *<namespace>* --placement="*<num-daemons>* [*<host1>* ...]" ceph orch apply nfs nfs-hmtd --pool nfs-hmtd nfs-ns --placement="appfor117 appfor210" -
为了在dashboard中进行操作,可以进行如下设置:
ceph dashboard set-ganesha-clusters-rados-pool-namespace nfs-hmtd/nfs-ns -
Ceph的NFS是基于CephFS提供的,我们首先在CephFS中创建一个/nfs目录,用于作为NFS服务的根目录。
mkdir /mnt/cephfs/nfs -
其中mount的时候的secret是/etc/ceph/ceph.client.admin.keyring的值,也可以替换成
secretfile=/etc/ceph/ceph.client.admin.keyring。
创建Ceph块存储
-
创建存储池pool
新建数据池
ceph osd pool create storage_(池名) 64重命名pool
ceph osd pool rename storage_(旧池名) storage_(新池名)设置存储池副本数(默认3副本)
ceph osd pool get storage_(池名) size ceph osd pool setstorage_(池名) size 3给test使用的pool标识成test
ceph osd pool application enable storage_(池名)/cache_(池名) test查看存储池
ceph osd lspools#创建缓存+存储(可以不操作) #新建数据池 ceph osd pool create storage_(池名) 64 #新建缓冲池 ceph osd pool create cache_(池名) 64 #把缓存层挂接到后端存储池上 ceph osd tier add storage_(池名) cache_(池名) #设定缓冲池读写策略为写回模式。 ceph osd tier cache-mode cache_(池名) writeback #将客户端流量指向到缓存存储池 ceph osd tier set-overlay storage_(池名) cache_(池名) #调整Cache tier配置 #1、设置缓存层hit_set_type使用bloom过滤器 ceph osd pool set cache_(池名) hit_set_type bloom #2、设置hit_set_count、hit_set_period #热度数hit_set_count:HitSet 覆盖的时间区间,保留多少个这样的 HitSet,保留一段时间以来的访问记录 #热度周期hit_set_period:判断一客户端在一段时间内访问了某对象 一次、还是多次 #最大缓冲数据target_max_bytes。 ceph osd pool set cache_(池名) hit_set_count 1 ceph osd pool set cache_(池名) hit_set_period 3600 ceph osd pool set cache_(池名) target_max_bytes 1000000000000 #3、设置min_read_recency_for_promete、min_write_recency_for_promote ceph osd pool set cache_(池名) min_read_recency_for_promote 1 ceph osd pool set cache_(池名) min_write_recency_for_promote 1 #缓存池容量控制 #刷写(flushing):负责把已经被修改的对象写入到后端慢存储,但是对 象依然在缓冲池。 #驱逐(evicting):负责在缓冲池里销毁那些没有被修改的对象。 #(1)驱逐(容量百分比),缓冲池代理就开始把这些数据刷写到后端慢存 储。当缓冲池里被修改的数据达到40%时,则触发刷写动作。 ceph osd pool set cache_(池名) cache_target_dirty_ratio 0.4 #(2)驱逐指定数据对象数量或者确定的数据容量。对缓冲池设定最大的数 据容量 ceph osd pool set cache_(池名) target_max_bytes 1073741824 #(3)驱逐对缓冲池设定最大的对象数量。在默认情况下,RBD的默认对 象大小为 4MB,1GB容量包含256个4MB的对象 ceph osd pool set cache_(池名) target_max_objects 256 #4、对象有最短的刷写周期。 #设定最短的刷写周期:若被修改的对象在缓冲池里超过最短周期,将会被刷写 到慢存储池(分钟) ceph osd pool set cache_(池名) cache_min_flush_ age 600 #设定对象最短的驱逐周期 ceph osd pool set cache_(池名) cache_min_evict_age 1800 #删除缓存层 #删除readonly缓存 #把缓存模式改为 none 即可禁用 ceph osd tier cache-mode cache_(池名) none #去除后端存储池的缓存池 ceph osd tier remove storage_(池名) cache_(池名) #删除writeback缓存 #把缓存模式改为 forward ,这样新的和更改过的对象将直接刷回到 后端存储池 ceph osd tier cache-mode cache_(池名) forward --yes-i-really-mean-it #确保缓存池已刷回,可能要等数分钟 rados ls -p cache_(池名) #可以通过以下命令进行手动刷回 rados -p cache_(池名) cache-flush-evict-all #取消流量指向缓存池 ceph osd tier remove-overlay storage_(池名) #剥离缓存池 ceph osd tier remove storage cache_(池名) -
创建镜像
方法一:默认池中创建镜像
rbd create cxk-image --image-feature layering --size 1G方法二:指定池中创建镜像
rbd create 池名/cxk-image --image-feature layering --size 1G查看镜像
rbd list 池名查看详细信息
rbd info 池名/cxk-image -
镜像动态调整
扩容容量
rbd resize --size 2G 池名/cxk-image缩小容量
rbd resize --size 1G 池名/cxk-image --allow-shrink -
删除RBD块设备
rbd rm 池名/cxk-image镜像快照操作 给镜像创建快照 rbd snap create 池名/cxk-image --snap cxk-snap1 克隆快照
保护快照不让删除:rbd snap protect 池名/cxk-image --snap cxk-snap1 取消保护:rbd snap
unprotect 池名/cxk-image --snap cxk-snap1 rbd clone 池名/cxk-image --snap
cxk-snap1 cxk-snap2 --image-feature layering 还原快照: rbd snap rollback
池名/cxk-image --snap cxk-snap1 把快照脱离父母独立工作 rbd flatten cxk-snap1 删除快照:
rbd snap rm 池名/cxk-image --snap cxk-snap1 查看快照: 查看镜像快照 rbd snap ls
池名/cxk-image 查看克隆镜像与父镜像快照的关系 rbd info 池名/cxk-clone
客户端通过KRBD访问块存储
-
客户端安装
yum install createrepo -y yum install epel-release -y yum install lttng-ust -y #指定共享的yum yum -y install ceph-common -
客户端拷贝ceph文件到本地、配置文件和连接密钥文件
scp /my-cluster/ceph.conf root@192.168.66.242:/etc/ceph/ scp /my-cluster/ceph.client.admin.kevring root@192.168.66.242:/etc/ceph/ -
客户端挂载服务端的镜像
rbd map 池名/cxk-image 撤销磁盘挂载: rbd unmap /dev/rbd0(挂载点) -
客户端查看挂载服务端的镜像
rbd showmapped lsblk -
客户端格式化、挂载分区
mkfs.xfs /dev/rbd0 mount /dev/rbd0 /mnt/
创建MDS文件系统(inode+block)
要使用 CephFS, 至少就需要一个 metadata server 进程。可以手动创建一个 MDS, 也可以使 用 ceph-deploy 或者 ceph-ansible 来部署 MDS。
-
给那些osd部署mds服务:
cd /my-cluster ceph-deploy mds create ceph-node1ceph-node2 ceph-node3 (可以继续添加) -
创建存储池
数据:ceph osd pool create cephfs_cxk_data 128 元数据:ceph osd pool create cephfs_cxk_metadata 64 查看:ceph osd lspools -
创建Ceph文件系统
ceph fs new myfs-cxk cephfs_cxk_metadata cephfs_cxk_data -
查看
ceph fs ls
客户端挂载
vim /etc/fstab
ip:6789,ip:6789,ip:6789:/ /mnt/cephfs ceph name=admin,secret=xxxxxx,_netdev 0 0
mount -t ceph MON节点的IP:6789:/ /mnt/cephfs/
-o name=admin,secret=AQC0FaJgu2A2ARAACbXjhYEeZTX+nlUJ+seDGw==
#注意:文件系统类型为ceph
#admin是用户名,secret是密钥
#密钥可以在/etc/ceph/ceph.client.admin.keyring中找到
创建RGW对象存储
-
部署rgw服务:
ceph-deploy rgw create ceph-node1(可以继续添加) -
登陆该节点验证服务是否启动
ps aux |grep radosgw -
该节点修改服务端口
vim /etc/ceph/ceph.conf [client.rgw.node5] host = ceph-node1 rgw_frontends = "civetweb port=8000" //node5为主机名 //civetweb是RGW内置的一个web服务 -
该节点重启服务
systemctl status ceph-radosgw@\* -
创建radosgw用户
radosgw-admin user create --uid="radosgw" --display-name="radosgw" { "user_id": "radosgw", "display_name": "radosgw", "email": "", "suspended": 0, "max_buckets": 1000, "auid": 0, "subusers": [], "keys": [ { "user": "radosgw", "access_key": "DKOORDOMS6YHR2OW5M23", "secret_key": "OOBNCO0d03oiBaLCtYePPQ7gIeUR2Y7UuB24pBW4" } ], "swift_keys": [], "caps": [], "op_mask": "read, write, delete", "default_placement": "", "placement_tags": [], "bucket_quota": { "enabled": false, "check_on_raw": false, "max_size": -1, "max_size_kb": 0, "max_objects": -1 }, "user_quota": { "enabled": false, "check_on_raw": false, "max_size": -1, "max_size_kb": 0, "max_objects": -1 }, "temp_url_keys": [], "type": "rgw" }
客户端安装软件
-
安装
yum install s3cmd -
修改软件配置
s3cmd --configure Access Key: DKOORDOMS6YHR2OW5M23 Secret Key: OOBNCO0d03oiBaLCtYePPQ7gIeUR2Y7UuB24pBW4 Default Region [US]: ZH S3 Endpoint [s3.amazonaws.com]: 192.168.4.15:8000 [%(bucket)s.s3.amazonaws.com]: %(bucket)s.192.168.4.15:8000 Use HTTPS protocol [Yes]: no Test access with supplied credentials? [Y/n] n Save settings? [y/N] y -
创建存储数据的bucket(类似于存储数据的目录)创建桶并放入文件
s3cmd ls s3cmd mb s3://my_bucket Bucket 's3://my_bucket/' created s3cmd ls 2018-05-09 08:14 s3://my_bucket s3cmd put /var/log/messages s3://my_bucket/log/ s3cmd ls s3://my_bucket DIR s3://my_bucket/log/ s3cmd ls s3://my_bucket/log/ 2018-05-09 08:19 309034 s3://my_bucket/log/messages -
测试下载功能
s3cmd get s3://my_bucket/log/messages /tmp/ -
测试删除功能
s3cmd del s3://my_bucket/log/messages
使用
集群监控管理
-
集群整体运行状态
ceph -s -
检查集群健康状况的命令,后期用来查找故障
ceph health detail HEALTH_OK -
PG状态
ceph pg dump ceph pg stat -
Pool状态
ceph osd pool stats -
OSD状态
ceph osd stat ceph osd dump ceph osd tree ceph osd df -
Monitor状态和查看仲裁状态
ceph mon stat ceph mon dump ceph quorum_status -
集群空间用量
ceph df ceph df detail
集群配置管理(临时和全局,服务平滑重启)
有时候需要更改服务的配置,但不想重启服务,或者是临时修改。这时候就可以使用 tell和daemon子命令来完成此需求。
-
查看运行配置
#命令格式: ceph daemon {daemon-type}.{id} config show #命令举例: ceph daemon osd.0 config show -
tell子命令格式
使用 tell 的方式适合对整个集群进行设置,使用 * 号进行匹配,就可以对整个集 群的角色进行设置。而出现节点异常无法设置时候,只会在命令行当中进行报错, 不太便于查找。
#命令格式: ceph tell {daemon-type}.{daemon id or *} injectargs --{name}={value} [--{name}={value}] #命令举例: ceph tell osd.0 injectargs --debug-osd 20 --debug-ms 1 #daemon-type:为要操作的对象类型如osd、mon、mds等。 #daemon id:该对象的名称,osd通常为0、1等,mon为ceph -s显示的名称, 这里可以输入*表示全部。 #injectargs:表示参数注入,后面必须跟一个参数,也可以跟多个 -
daemon子命令
使用 daemon 进行设置的方式就是一个个的去设置,这样可以比较好的反馈,此 方法是需要在设置的角色所在的主机上进行设置。
#命令格式: ceph daemon {daemon-type}.{id} config set {name}={value} #命令举例: ceph daemon mon.ceph-monitor-1 config set mon_allow_pool_delete false
集群操作
命令包含start、restart、status
-
启动所有守护进程
systemctl start ceph.target -
按类型启动守护进程
systemctl restart ceph-mgr.target systemctl restart ceph-osd@id systemctl restart ceph-mon.target systemctl restart ceph-mds.target systemctl restart ceph-radosgw.target -
更新所有节点的配置文件的命令
ceph-deploy --overwrite-conf config push cephnode01 cephnode02 cephnode03
添加和删除OSD
添加OSD
-
格式化磁盘
ceph-volume lvm zap /dev/sd<id> -
进入到ceph-deploy执行目录/my-cluster,添加OSD
删除OSD
-
调整osd的crush weight为 0
ceph osd crush reweight osd.<ID> 0.0 -
将osd进程stop
systemctl stop ceph-osd@<ID> -
将osd设置out
ceph osd out <ID> -
立即执行删除OSD中数据
ceph osd purge osd.<ID> --yes-i-really-mean-it -
卸载磁盘
umount /var/lib/ceph/osd/ceph-?
RDB快设备操作
-
创建
#方法一:默认池中创建镜像 rbd create cxk-image --image-feature layering --size 1G #方法二:指定池中创建镜像 rbd create 池名/cxk-image --image-feature layering --size 1G -
查看
#查看镜像: rbd list 池名 #查看详细信息: rbd info 池名/cxk-image -
镜像动态调整
#扩容容量 rbd resize --size 2G 池名/cxk-image #缩小容量 rbd resize --size 1G 池名/cxk-image --allow-shrink -
删除RBD块设备
rbd rm 池名/cxk-image -
快照操作
#给镜像创建快照 rbd snap create 池名/cxk-image --snap cxk-snap1#克隆快照 #保护快照不让删除: rbd snap protect 池名/cxk-image --snap cxk-snap1 #取消保护: rbd snap unprotect 池名/cxk-image --snap cxk-snap1 rbd clone 池名/cxk-image --snap cxk-snap1 cxk-snap2 --image-feature layering#还原快照: rbd snap rollback 池名/cxk-image --snap cxk-snap1#把快照脱离父母独立工作 rbd flatten cxk-snap1#删除快照: rbd snap rm 池名/cxk-image --snap cxk-snap1#查看快照: #查看镜像快照 rbd snap ls 池名/cxk-image #查看克隆镜像与父镜像快照的关系 rbd info 池名/cxk-clone
扩容PG
ceph osd pool set {pool-name} pg_num 128
ceph osd pool set {pool-name} pgp_num 128
1、扩容大小取跟它接近的2的N次方
2、在更改pool的PG数量时,需同时更改PGP的数量。PGP是为了管理placement 而存在的专门的PG,它和PG的数量应该保持一致。如果你增加pool的 pg_num,就需要同时增加pgp_num,保持它们大小一致,这样集群才能正常 rebalancing。
Pool操作
-
列出存储池
ceph osd lspools -
创建存储池
#命令格式: ceph osd pool create {pool-name} {pg-num} [{pgp-num}] #命令举例: ceph osd pool create rbd 32 32 -
设置存储池配额
#命令格式: ceph osd pool set-quota {pool-name} [max_objects {obj-count}] [max_bytes {bytes}] #命令举例: ceph osd pool set-quota rbd max_objects 10000 -
删除存储池
在ceph.conf配置文件中添加如下内容:
[global] ....... mon_allow_pool_delete = true使用ceph-deploy推配置给所有节点
ceph-deploy --overwrite-conf config push cephnode1 cephnode2 cephnode3重启ceph-mon服务
systemctl restart ceph-mon.target#执行删除pool命令 ceph osd pool delete {pool-name} [{pool-name} --yes-i-really-really-mean-it #命令举例: ceph osd pool delete kube kube --yes-i-really-really-mean-it -
重命名存储池
ceph osd pool rename {current-pool-name} {new-pool-name} -
查看存储池统计信息
rados df -
给存储池做快照
ceph osd pool mksnap {pool-name} {snap-name} -
删除存储池的快照
ceph osd pool rmsnap {pool-name} {snap-name} -
获取存储池选项值
ceph osd pool get {pool-name} {key} -
调整存储池选项值
ceph osd pool set {pool-name} {key} {value} #size:设置存储池中的对象副本数,详情参见设置对象副本数。仅适用于副本 存储池。 #min_size:设置 I/O 需要的最小副本数,详情参见设置对象副本数。仅适用 于副本存储池。 #pg_num:计算数据分布时的有效 PG 数。只能大于当前 PG 数。 #pgp_num:计算数据分布时使用的有效 PGP 数量。小于等于存储池的 PG 数。 #hashpspool:给指定存储池设置/取消 HASHPSPOOL 标志。 #target_max_bytes:达到 max_bytes 阀值时会触发 Ceph 冲洗或驱逐对象。 #target_max_objects:达到 max_objects 阀值时会触发 Ceph 冲洗或驱逐对象。 #scrub_min_interval:在负载低时,洗刷存储池的最小间隔秒数。如果是 0 , 就按照配置文件里的 osd_scrub_min_interval 。 #scrub_max_interval:不管集群负载如何,都要洗刷存储池的最大间隔秒数。 如果是 0 ,就按照配置文件里的 osd_scrub_max_interval 。 #deep_scrub_interval:“深度”洗刷存储池的间隔秒数。如果是 0 ,就按照配 置文件里的 osd_deep_scrub_interval 。 -
获取对象副本数
ceph osd dump | grep 'replicated size'
用户管理
Ceph 把数据以对象的形式存于各存储池中。Ceph 用户必须具有访问存储池的权限才 能够读写数据。另外,Ceph 用户必须具有执行权限才能够使用 Ceph 的管理命令。
-
查看用户信息
#查看所有用户信息 ceph auth list #获取所有用户的key与权限相关信息 ceph auth get client.admin #如果只需要某个用户的key信息,可以使用pring-key子命令 ceph auth print-key client.admin -
添加用户
ceph auth add client.john mon 'allow r' osd 'allow rw pool=liverpool' ceph auth get-or-create client.paul mon 'allow r' osd 'allow rw pool=liverpool' ceph auth get-or-create client.george mon 'allow r' osd 'allow rw pool=liverpool' -o george.keyring ceph auth get-or-create-key client.ringo mon 'allow r' osd 'allow rw pool=liverpool' -o ringo.key -
修改用户权限
ceph auth caps client.john mon 'allow r' osd 'allow rw pool=liverpool' ceph auth caps client.paul mon 'allow rw' osd 'allow rwx pool=liverpool' ceph auth caps client.brian-manager mon 'allow *' osd 'allow *' ceph auth caps client.ringo mon ' ' osd ' ' -
删除用户
ceph auth del {TYPE}.{ID} #其中, {TYPE} 是 client,osd,mon 或 mds 的其中一种。{ID} 是用户的名 字或守护进程的 ID 。
常见错误操作
1
health: HEALTH_WARN
1 daemons have recently crashed
#ceph报守护程序最近崩溃了的解决方法
ceph health detail
#新的崩溃可以通过以下方式列出
ceph crash ls-new
#有关特定崩溃的信息可以通过以下方法检查
ceph crash info <crash-id>
#可以通过“存档”崩溃(可能是在管理员检查之后)来消除此警告,从而不会生成 此警告
ceph crash archive <crash-id>
#所有新的崩溃都可以通过以下方式存档
ceph crash archive-all
#通过ceph crash ls仍然可以看到已存档的崩溃
可以通过以下方式完全禁用这些警告
ceph config set mgr/crash/warn_recent_interval 0
2
health: HEALTH_WARN
mons are allowing insecure global_id reclaim
ceph health detail
ceph config set mon auth_allow_insecure_global_id_reclaim false
3
health: HEALTH_WARN
application not enabled on 1 pool(s)
ceph health detail
ceph osd pool application enable rbd rbd
4
HEALTH_WARN
Degraded data redundancy: 187/561 objects degraded (33.333%), 43 pgs degraded, 160 pgs undersized; OSD count 2 < osd_pool_default_size 3; mons are allowing insecure global_id reclaim
默认3副本没满足
ceph共享节点扩容
节点扩容
扩容mon
-
环境准备
硬件配置:2C4G
另外每台机器最少挂载三块硬盘 -
关闭防火墙:
systemctl stop firewalld systemctl disable firewalld -
关闭selinux:
sed -i 's/enforcing/disabled/' /etc/selinux/config setenforce 0 -
关闭NetworkManager
systemctl disable NetworkManager systemctl stop NetworkManager -
cephnode1操作机上主机名与IP对应关系
vim /etc/hosts 192.168.66.10 cephnode1 192.168.66.11 cephnode2 192.168.66.12 cephnode3 -
设置文件描述符
echo "ulimit -SHn 102400" >> /etc/rc.local vim /etc/security/limits.conf * soft nofile 655360 * hard nofile 655360 root soft nofile 655360 root hard nofile 655360 * soft core unlimited * hard core unlimited root soft core unlimited -
内核参数优化
vi /etc/sysctl.conf #仅在内存不足的情况下--当剩余空闲内存低于vm.min_free_kbytes limit时,使用交换空间。 vm.swappiness = 0 #单个进程可分配的最大文件数 fs.nr_open=2097152 #系统最大文件句柄数 fs.file-max=1048576 #backlog 设置 net.core.somaxconn=32768 net.ipv4.tcp_max_syn_backlog=16384 net.core.netdev_max_backlog=16384 #TCP Socket 读写 Buffer 设置 net.core.rmem_default=262144 net.core.wmem_default=262144 net.core.rmem_max=16777216 net.core.wmem_max=16777216 net.core.optmem_max=16777216 net.ipv4.neigh.default.gc_stale_time=120 #TIME-WAIT Socket 最大数量、回收与重用设置 net.ipv4.tcp_max_tw_buckets=1048576 net.ipv4.tcp_tw_reuse=1 net.ipv4.tcp_tw_recycle=1 #TCP 连接追踪设置 net.nf_conntrack_max=1000000 net.netfilter.nf_conntrack_max=1000000 net.netfilter.nf_conntrack_tcp_timeout_time_wait=30 # FIN-WAIT-2 Socket 超时设置 net.ipv4.tcp_fin_timeout=15 net.ipv4.ip_forward = 1 kernel.pid_max=4194303 sysctl -p -
同步网络时间和修改时区
yum -y install chrony vim /etc/chrony.conf systemctl restart chronyd systemctl enable chronyd chronyc sources -
安装createrepo和epel源(传软件包\安装包到服务器上)
yum install createrepo -y yum install epel-release -y yum install lttng-ust -y -
编辑yum源文件
vim /etc/yum.repos.d/ceph.repo [Ceph] name=Ceph packages for $basearch baseurl=http://192.168.0.6/ceph/rpm-nautilus/el7/$basearch gpgcheck=0 priority=1 [Ceph-noarch] name=Ceph noarch packages baseurl=http://192.168.0.6/ceph/rpm-nautilus/el7/noarch gpgcheck=0 priority=1 [ceph-source] name=Ceph source packages baseurl=http://192.168.0.6/ceph/rpm-nautilus/el7/SRPMS gpgcheck=0 priority=1 #执行 yum makecache -
传软件包\安装包到服务器上
yum -y install ceph ceph -v
cephnode1操作节点上把新加mon加入集群
for i in 13 14; do ssh-copy-id root@192.168.66.$i; done
cd /my-cluster/
vim ceph.conf
mon_initial_members = cephnode1, cephnode2, cephnode3, cephnode4, cephnode5
mon_host = 192.168.66.10,192.168.66.11,192.168.66.12,192.168.66.13,192.168.66.14
public_network = 192.168.66.0/24
#配置文件推送到各各节点
ceph-deploy --overwrite-conf config push
cephnode1 cephnode2 cephnode3 cephnode4 cephnode5
ceph-deploy mon add cephnode4 --address 节点ip
ceph-deploy mon add cephnode5 --address 节点ip
cephnode1操作节点上安装Ceph CLI,方便执行一些管理命令
如前所示,我们执行admin的命令,要提供admin的key(–keyring ceph.client.admin.keyring)以及配置文件(-c ceph.conf)。在后续的运维中,我们经常 需要在某个node上执行admin命令。每次都提供这些参数比较麻烦。实际上,ceph 会默认地从/etc/ceph/中找keyring和ceph.conf。因此,我们可以把 ceph.client.admin.keyring和ceph.conf放到每个node的/etc/ceph/。ceph-deploy可 以 帮做这些
ceph-deploy admin cephnode4 cephnode5
cephnode1操作节点上部署监控配置mgr,用于管理集群
ceph-deploy mgr create cephnode4 cephnode5
cephnode1操作节点上部署MDS(CephFS)
ceph-deploy mds create cephnode4 cephnode5
cephnode1操作节点上添加osd(添加的磁盘必须是没有被处理过的裸盘)
ceph-deploy osd create --data /dev/sdb cephnode4
ceph-deploy osd create --data /dev/sdc cephnode4
ceph-deploy osd create --data /dev/sdb cephnode5
ceph-deploy osd create --data /dev/sdc cephnode5
检查状态
ceph osd tree
查看Ceph集群概况文章来源:https://www.toymoban.com/news/detail-403160.html
ceph -s
喜欢的亲可以关注点赞评论哦!以后每天都会更新的哦!本文为小编原创文章; 文章中用到的文件、安装包等可以加小编联系方式获得;
欢迎来交流小编联系方式VX:CXKLittleBrother 进入运维交流群文章来源地址https://www.toymoban.com/news/detail-403160.html
到了这里,关于ceph分布式存储的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!