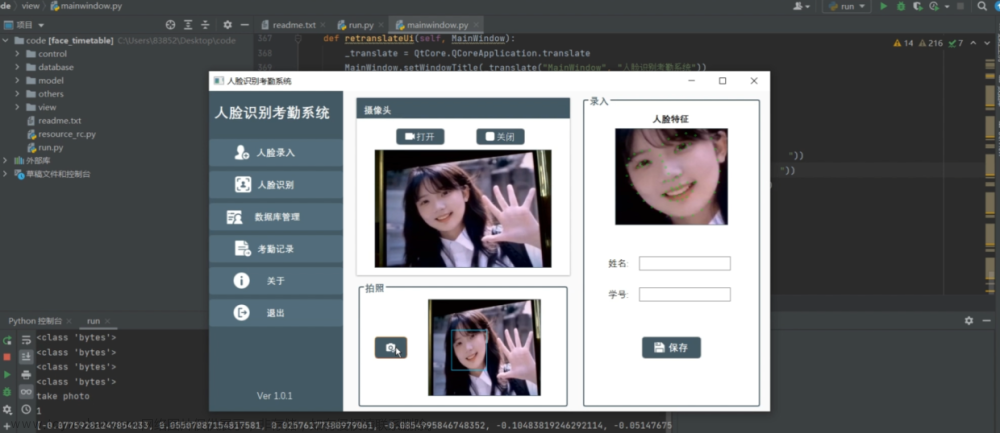
最近做了一个打架识别的项目,有感于当时开发资料的匮乏,特做一个小结,供大家参考。闲话少叙,看看效果先。
1. 研究现状
目前打架检测,主要有3种主流的方法,分别是:
(1)基于Detection的打架检测。其主要思想是: 将打架作为一种类别,通过分类的方式,将打架行为检测出来。目前这方面的研究较少,且没有公开可用的数据集,想要沿着这条路走,需自备数据集,自行探索。
(2)基于骨骼点的打架检测。其主要思想是:通过OpenPose等框架,将人体的骨骼点回归出来,然后基于骨骼点写逻辑,进行判断。目前有一部分人是基于这个做的打架检测。但是打架过程中如果人员纠缠在一起的话,利用骨骼点准确判断就比较困难。
(3)基于视频理解的打架检测。其主要思想是: 基于时序进行判断。打架对时序有着较强的依赖,利用目标检测技术去识别打架容易出现误检测或者漏检情况。另外如果人员重叠遮挡严重的话,基于骨骼点的行为识别,就有很大的局限性。而基于视频理解的打架检测,则较好的解决了这些问题。但是这种实现起来难度也较大。
2.选取的方案
我这里选择方案1,即基于目标检测做打架识别。前文也提到了,目前数据集十分匮乏。笔者也是反复查找,终于拿到了国外的一份很好的数据集。考虑到不同于一般的目标检测任务,所以数据集也是笔者亲自标注的,没有让第三方人员介入,目的就是保证标注的合理与精准。
基本流程是:
Labelme标注 -> 标注数据整理与格式转换 -> 模型训练 -> 部署
2.1 标注
目前开发工作都是在win11上,采用的是开源的labelme工具。笔者也是头一次使用该工具。使用之后才发现其实还是不错的,功能十分齐全。另外我拿到的国外数据集,是视频的形式,因此需要先将视频转换成图片,然后再进行标注。具体可以参考这篇文章,写的不错。
Labelme标注视频https://www.pudn.com/news/623b0a3f49c1dc3c8980863b.html

Fig.1 利用Labelme进行数据标注
利用几天空闲时间,笔者标注了上千张图片,然后剔除了一些无效图像,最终标注的数据集的信息如下:
| 标注工具 | Labelme |
| 数据集名称 | 打架数据集 |
| 图片数量/格式 | 800张左右/jpg |
| 图像分辨率 | 1920*1080 |
| 标注文件格式 | json |
| 是否涉密 | 否 |
2.2 标注数据整理与格式转换
Labelme标注的数据,无法直接用在训练中,需要自己再转换下。因为准备采用Yolo算法,所以这里我们要将Labelme格式转换成Yolo格式。以下是转换脚本:
"""
2023.1.1
该代码实现了labelme导出的json文件,批量转换成yolo需要的txt文件,且包含了坐标归一化
原来labelme标注之后的是:1.jpg 1.json
经过该脚本处理后,得到的是1.jpg 1.json 1.txt
"""
import os
import numpy as np
import json
from glob import glob
import cv2
from sklearn.model_selection import train_test_split
from os import getcwd
classes = ["NOFight", "Fight", "Person"]
# 1.标签路径
labelme_path = "Data20200108/"
isUseTest = False # 是否创建test集
# 3.获取待处理文件
files = glob(labelme_path + "*.json")
files = [i.replace("\\", "/").split("/")[-1].split(".json")[0] for i in files]
print(files)
if isUseTest:
trainval_files, test_files = train_test_split(files, test_size=0.1, random_state=55)
else:
trainval_files = files
# split
train_files, val_files = train_test_split(trainval_files, test_size=0.1, random_state=55)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
wd = getcwd()
print(wd)
def ChangeToYolo5(files, txt_Name):
if not os.path.exists('tmp/'):
os.makedirs('tmp/')
list_file = open('tmp/%s.txt' % (txt_Name), 'w')
for json_file_ in files:
json_filename = labelme_path + json_file_ + ".json"
imagePath = labelme_path + json_file_ + ".jpg"
list_file.write('%s/%s\n' % (wd, imagePath))
out_file = open('%s/%s.txt' % (labelme_path, json_file_), 'w')
json_file = json.load(open(json_filename, "r", encoding="utf-8"))
height, width, channels = cv2.imread(labelme_path + json_file_ + ".jpg").shape
for multi in json_file["shapes"]:
points = np.array(multi["points"])
xmin = min(points[:, 0]) if min(points[:, 0]) > 0 else 0
xmax = max(points[:, 0]) if max(points[:, 0]) > 0 else 0
ymin = min(points[:, 1]) if min(points[:, 1]) > 0 else 0
ymax = max(points[:, 1]) if max(points[:, 1]) > 0 else 0
label = multi["label"]
if xmax <= xmin:
pass
elif ymax <= ymin:
pass
else:
cls_id = classes.index(label)
b = (float(xmin), float(xmax), float(ymin), float(ymax))
bb = convert((width, height), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
print(json_filename, xmin, ymin, xmax, ymax, cls_id)
ChangeToYolo5(train_files, "train")
ChangeToYolo5(val_files, "val")
# ChangeToYolo5(test_files, "test")
2.3 模型的训练
这里我采用的是反响比较好的yolov5算法,利用Pycharm进行开发。这里简单介绍下yolov5: yolov5是一个设计精巧的深度学习网络,对于目标检测任务来说,十分好用。同时作者还十分贴心的提供了模型转换部署等一系列脚本,可以说用起来是十分的顺手。并且该repo还在不停的更新,开发者众多,选择该模型省时省力省心。这里笔者采用的是yolov5-6.1版本,其他版本尚未进行验证。

Fig.2 yolov5-v6.1
将该repo下载到本地,然后用pycharm打开:

Fig.3 pycharm打开工程
然后就是利用anaconda配置yolov5的环境了。这里就不再展开了,不会配置的朋友们,可以参考这里:annconda配置虚拟环境
笔者的显卡是3070Ti,所以配置了支持cuda的虚拟环境,如下图所示。基于cuda的环境,训练起来速度快,能达到cpu的20-40倍。如果没有独立N卡,就需要配置cpu的虚拟环境,一样可以使用,只是速度会慢不少。

Fig.4 anaconda配置虚拟环境
笔者这里用的是torch1.12.1+cu113,我看很多的博客还在教大家使用torch1.7.1,实在是误人子弟。这里因为是用yolov5训练自己的数据集,所以我们这里需要进行一些配置,包括数据集的配置,配置文件的编写等,下面进行详细的一些说明。
2.3.1 数据集配置:
打架的数据集,就是我们这里的Data20200108,其中images下又有train和val,里面存放的都是原始的图像。labels中存放的是标注的文件,全部转换成了txt文件,和images一样,也分为了train和val。

Fig.5 配置自己的数据集
这里的train_list.txt和val_list.txt里面是训练数据集图像的路径和测试数据集的路径,摘录部分给大家看下:
datasets/Data20200108/images/train/cam1_100000.jpg
datasets/Data20200108/images/train/cam1_100001.jpg
datasets/Data20200108/images/train/cam1_100002.jpg
datasets/Data20200108/images/train/cam1_100003.jpg
datasets/Data20200108/images/train/cam1_100004.jpg
datasets/Data20200108/images/train/cam1_100005.jpg
datasets/Data20200108/images/train/cam1_100006.jpg
datasets/Data20200108/images/train/cam1_100007.jpg
datasets/Data20200108/images/train/cam1_100008.jpg2.3.2 配置文件编写:
在data文件夹下,我们新建fight_person.yaml脚本,并编写配置文件。
 Fig.6 配置文件编写
Fig.6 配置文件编写
好了,所有的准备工作都已经完成,下面我们选定训练脚本train.py,设置如下参数,进行训练。
--data fight_person.yaml --weights yolov5s.pt --img 640 --batch-size 8 --device 0 --epochs 10 --workers 0
含义我简单介绍下:
--data: 对应的配置脚本,里面有图像路径,类别等信息
--weights:权重文件,这里笔者选择yolov5s.pt
--img:训练分辨率,笔者选择默认640
--batch-size: 批大小,这个和机器的性能有关,性能约好,数字越大
--device:设备,如果没有显卡,就写cpu,如果是单显卡,就写0,多卡根据实际情况写0,1,2...
-epochs:迭代的次数
2.3.3 开始训练
训练结果后,我们在run/train/下得到了训练的一些log,我们挑一些重点的来看:

Fig.7 训练指标图
上图的信息还是比较全的,我们能明显看到,loss在迅速的下降,mAP在迅速上升。意味着很快就收敛了。对于检测任务,评价指标主要是mAP,具体可以参考这里:
mAP释义https://blog.csdn.net/HUAI_BI_TONG/article/details/121212733
可以简单理解为,mAP越大,意味着效果也越好。训练自动生成的文件夹里面,还有一些图片:

Fig.8人工 标注的框

Fig.9 模型检测框
可以看到效果还是很好的,标注的框和实际的框基本都能重合,意味着我们的模型拟合效果不错。文章来源:https://www.toymoban.com/news/detail-403220.html
3.结束语
以上就是利用yolov5训练自己数据集的全部内容,包含了数据集标注,制作,训练环境配置,训练过程解析等。在下篇文章中,我们会进行界面开发。人工智能配上华丽外衣,嘎嘎给力。文章来源地址https://www.toymoban.com/news/detail-403220.html
到了这里,关于打架识别(AI+Python+PyQt5)(一)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!