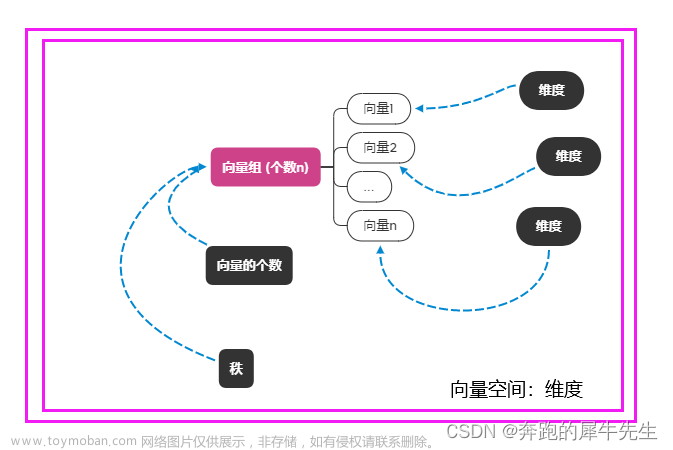
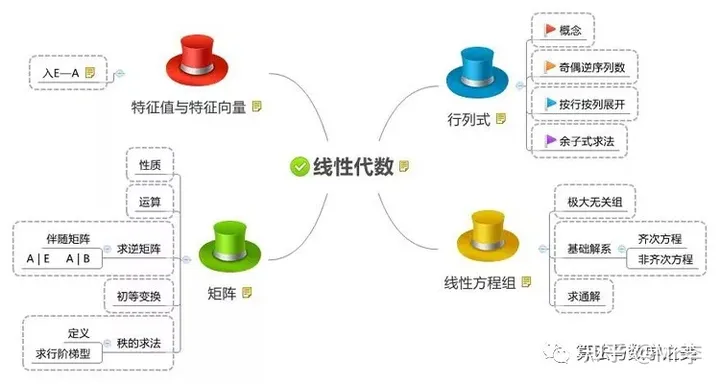
知识总览
先把知识都罗列出来,然后我们看着目录来学习就好了。
我们还未整理完,会随着自己的学习同步更新的,同时我发现网上有很多已经整理好的帖子,咱们在同步更新的时候也要参考他们的整理方式一起学习(因为他们已经考过一遍了,真的很精炼哈)
我们整理完复习完知识以后,一定要学习这些作者,用简明的几句话,描述一章的脉络,以及为什么一章的脉络(知识点)要这样来安排,以及这样安排有什么用,这样才是真的学懂了矩阵论。(假如自己是徐涛或腿姐那样的老师,怎样用一种脉络,让学生在浩如烟海的知识里简洁明快的了解一章要干什么,一章要学什么,还能把一章知识彻底的记住。实际上自己做科研的话也要追求这样的理解)
矩阵论知识点
矩阵论核心知识点
矩阵论复习笔记-华中科技大学
矩阵论概念及定理
矩阵基础知识
矩阵理论学习笔记
第一章 线性空间和线性变换
1.1 线性空间
- 集合与映射
- 线性空间的定义和性质
- 线性空间的基
- 线性子空间
1.2 线性映射,线性函数,线性变换及它们的矩阵表示
- 矩阵在线性映射研究中的应用;
- 线性映射在矩阵研究中的应用;
- 线性函数
- 线性变换
- 线性映射
1.3 线性变换的表示
- 线性变换的特征值和特征向量
- 相似变换
- Hamilton-Cayley定理
- 矩阵的最小多项式
- 不变子空间
- 线性变换可对角化条件
- 若当(Jordan)标准形;
1.4欧氏(Euclid)空间和酉空间
- 向量内积
- 向量长度
- Schwarz不等式
- 正交性
- 正交变换及其正交矩阵表示
- 正交矩阵的性质
- 对称变换和对称矩阵
- 酉空间介绍
- 酉变换和酉矩阵
- Heirmite变换和Hermite矩阵
- Heirmite矩阵的谱分解
- Gram-Schmidt正交化过程
第一章 线性空间和线性变换
1.1 线性空间
- 集合与映射
- 线性空间的定义和性质
- 线性空间的基
- 线性子空间
推荐参考矩阵论知识点,矩阵论核心知识点这两个网址来学习
集合与映射
集合
- 集合与其说是一个数学概念,还不如说是一种思维方式,即用集合(整体)的观点思考问题。
- 集合的运算及规则,两个集合的并、交运算以及一个集合的补;
集合中元素没有重合(统计中的采样可以重合),子集,元素。
映射
每个人都看得懂的映射(单射、满射、双射)
映射的定义
- 设 S , S ′ S,S' S,S′为给定的集合(可以相同也可以不同),定义一个规则 σ : S → S ’ \sigma:S → S’ σ:S→S’, 使得S中元素a和S’中唯一一个元素对应, 记为 a ′ = σ ( a ) a'=\sigma(a) a′=σ(a),或 σ : a → a ′ \sigma:a→a' σ:a→a′.
- 映射最本质的特征在于对于S中的任意一个元素在S’中仅有唯一的一个元素和它对应。 (自己的碎碎念:可以把映射当成一种函数来处理)
- 映射的原象,象;映射的复合。满射,单射,一一映射。
- 若 S ′ S' S′和 S S S相同,则称 σ \sigma σ为变换。
- 若 S ′ S' S′为数域,则称 σ \sigma σ为函数。
- 由单点映射导出的集值映射。
单点映射和极值映射 - 映射 σ : S → S ′ \sigma: S→S' σ:S→S′是将S中的每个元素映射为S’中的唯一一个元素,看成是单点映射,也就是将S中的每一个点(元素)映射为S’中的一个点(元素)。
- 基于映射
σ
\sigma
σ我们可以导出关于S的子集和S’的子集之间的一个映射
σ
\sigma
σ
和逆映射 σ − 1 \sigma^{-1} σ−1 ,我们称它们为集值映射,它们在将S的子集和S’的子集之间建立对应: σ : 2 s → 2 s ′ \sigma: 2^s→ 2^{s'} σ:2s→2s′, σ − 1 : 2 s ′ → 2 s \sigma^{-1}:2^{s'}→2^{s} σ−1:2s′→2s
(注:对于两个集合 ,如果按照一个对应关系(规则),使得对于 中的每一元素 ,都有 中的一个(几个)确定的元素 与之对应,那么我们把这个对应关系叫做集合 到集合 的单值(多值)映射,多值映射也称“集值映射”集值映射)
极值映射的性质这页应该不重要
线性空间的定义及性质
通俗来说,空间其实就是向量的集合,而什么是线性空间呢??线性空间就是满足下面8条性质的向量集合。
线性空间的定义
定义1.1 设V是一个非空集合,它的元素用x,y,z等表示,并称之为向量;K是一个数域,它的元素用k,l,m等表示,如果V满足下列条件:
-
在V中定义一个加法运算,即当 x , y ∈ V x,y \in V x,y∈V时,有惟一的 x + y ∈ V x+y\in V x+y∈V,且加法运算满足下列性质
- 结合律x+(Y+z)=(X+Y)+Z
- 交换律X+y=y + x;
- 存在零元素0,使x+0=x;
- 存在负元素,即对任何一向量x \in V,存在向量Y,x+y=0,则称y为x的负元素,记为-x,于是有x+(-x)=0
-
在V中定义数乘运算,即当 x ∈ V , k ∈ K x\in V,k \in K x∈V,k∈K,有唯一的 k x ∈ v kx\in v kx∈v,且数乘运算满足下列性质
5. 数因子分配律k(x+y)=kx+ky;
6. 分配律 (k+l) x = kx + lx ;
7. 结合律 k(lx) = (kl) x ;
8. 1 x = x
则称V为数域K一上的线性空间或向量空间。
- 特别地,当K为实数域R时,则称v为实线性空间;
- 当K为复数域c时,则称v为复线性(酉)空间。
(自己的碎碎念,我们做题目的时候,就是验证满足不满足这八条性质,简要来说就是:满不满足加法四条性质,满不满足数乘四条性质)
线性空间中,向量的关系
线性相关
若存在一组不全为零的数 c 1 , c 2 , … , c m c_1,c_2,…,c_m c1,c2,…,cm,使得 c 1 x 1 + c 2 x 2 + … + c m x m = 0 c_1x_1+c_2x_2+…+c_mx_m=0 c1x1+c2x2+…+cmxm=0,则称向量组 x 1 , x 2 , … , x m x_1,x_2,…,x_m x1,x2,…,xm线性相关,否则为线性无关。
极大线性无关组
一个不可能再往里添加向量而保持它们的线性无关性的向量组。
-
公理1(有限维空间的基本假设)线性无关组总是可以扩充为极大线性无关组
(PPT中有证明)(自己的碎碎念:证明一定要跟一遍,不然在考试的那么短的时间里,根本没法写出靠谱的证明过程) -
引理1.2:在一个线性空间中任两个极大线性无关组若它们的所含向量个数都有限,则所含向量个数一定相同
(PPT中有证明)
线性空间的维数
(定义)线性空间V的维数:V中极大线性无关组的所含向量的个数,定义为线性空间的维数。维数有限的称为有限维空间,否则称为无穷维空间
这个定义之所以有意义,是因为在引理1.2中我们证明了极大线性无关组的个数是相同的。
(PS:本课程仅仅研究有限维空间,这里得到的结论有些可以直接推广到无穷维空间,但有些却不可能。必须小心!在后面的讨论中我们仅仅讨论有限维空间,而不一一说明)
线性空间的基
若线性空间V的向量 x 1 , x 2 , … , x r x1,x2,…,xr x1,x2,…,xr满足
- x 1 , x 2 , … , x r x_1,x_2,…,x_r x1,x2,…,xr线性无关;
- V中的任意向量x都是
x
1
,
x
2
,
…
,
x
r
x_1,x_2,…,x_r
x1,x2,…,xr的线性组合,即
x = ∑ k = 1 n a k x k x = \sum_{k=1}^{n}a_{k}x_{k} x=k=1∑nakxk
则称 x 1 , x 2 , … , x r x1,x2,…,xr x1,x2,…,xr为V的一个基或基底,相应地称 x i xi xi为基向量。{ 特别强调组成基的向量排列是有顺序的}
推论1.1: 线性空间中任意一个极大无关组构成它的一个基。
定义1.2:称线性空间Vn的一个基x1,x2,…,xn为Vn的一个坐标系。设向量
x
∈
V
n
x\in V^n
x∈Vn,它在该坐标系下的线性表示为
x
=
c
1
x
1
+
c
2
x
2
+
…
+
c
n
x
n
x = c_1x_1+c_2x_2+…+c_nx_n
x=c1x1+c2x2+…+cnxn则称
c
1
,
c
2
,
…
,
c
n
c1,c2,…, cn
c1,c2,…,cn为x在该坐标系下的坐标或分量,有时我们称 n维向量
(
c
1
,
c
2
,
…
,
c
n
)
T
(c_1,c_2,\dots, c_n)^T
(c1,c2,…,cn)T为向量x在该坐标系下的表示
例题:
思路:基已经设置成
(
1
,
x
,
x
2
,
…
…
,
x
n
−
1
)
(1,x,x^2,……,x^{n-1})
(1,x,x2,……,xn−1)这个向量了,f(x)与g(x)又都可以在这个基下表示成
X
A
T
XA^T
XAT和
X
B
T
XB^T
XBT的形式【(基向量)(坐标)T的形式】,两个函数加起来,可以类似于向量坐标加和
坐标表示和映射
给定基X,那么向量x的坐标表示定义了一个
V
V
V和
R
n
R_n
Rn或
(
C
n
)
(C_n)
(Cn)之间的一一映射:
σ
:
V
→
R
n
(
或
C
n
)
\sigma: V \rightarrow R_n(或Cn)
σ:V→Rn(或Cn)
即
σ
:
x
∈
V
→
(
c
1
,
c
2
,
…
,
c
n
)
T
∈
R
n
(
或
C
n
)
即 \sigma: x\in V→ (c_1,c_2,\dots, c_n)^T\in R_n(或C_n)
即σ:x∈V→(c1,c2,…,cn)T∈Rn(或Cn)
数域相同的线性空间和n维列向量空间的关系:
(PS:我自己的理解:线性空间就是满足8条性质的向量集合,而Rn是实数域空间,Cn)
数域相同的线性空间和n维列向量空间的关系:
定理1.2 在一个基
X
X
X下我们看到任意n维实(或复)线性空间
V
V
V和n维列向量空间
R
n
R_n
Rn(或
C
n
C_n
Cn)代数同构,即存在
V
V
V和
R
n
Rn
Rn(或
C
n
Cn
Cn)的之间一一映射
σ
:
V
→
R
n
(
或
C
n
)
\sigma:V→ Rn(或Cn)
σ:V→Rn(或Cn)
使得
σ
(
x
+
y
)
=
σ
(
x
)
+
σ
(
y
)
,
x
,
y
∈
V
\sigma(x+y)= \sigma(x)+ \sigma(y), x, y\in V
σ(x+y)=σ(x)+σ(y),x,y∈V
σ
(
k
x
)
=
k
σ
(
x
)
,
x
∈
V
,
k
∈
K
,
\sigma(kx) =k \sigma(x), x\in V, k\in K,
σ(kx)=kσ(x),x∈V,k∈K,
也就是
σ
\sigma
σ保持加法和数乘运算。(其中,
σ
\sigma
σ(x)为x在X下的坐标)(按后面的定义,
σ
\sigma
σ实际为可逆的线性映射)
(按后面的定义,
σ
\sigma
σ实际为可逆的线性映射
(PS:我自己的理解,这里的意思是,原本的线性空间,用向量表示映射到实(复)数域空间后,这些映射也是满足加法性质与数乘性质的(这里称其为同构))
定理1.2完整的回答了问题1.
定理1.2 说明虽然n维线性空间有无穷多,但是从代数的角度我们仅仅研究n维实(或复)向量空间就足够了。
例如:前面介绍次数不超过
n
−
1
n-1
n−1的多项式全体按照通常的多项式加法和数乘构成一个线性的多项式函数空间
P
n
P_n
Pn,选择
P
n
P_n
Pn的一个基
x
1
=
1
,
x
2
=
x
,
x
3
=
x
2
,
…
,
x
n
=
x
n
−
1
x_1=1,x_2=x,x_3=x^2,…,x_n=x^{n-1}
x1=1,x2=x,x3=x2,…,xn=xn−1, 则任意次数不超过
n
−
1
n-1
n−1的多项式
f
(
x
)
=
a
0
x
n
−
1
+
a
1
x
n
−
2
+
…
+
a
n
−
2
x
+
a
n
−
1
f(x) =a_0x^{n-1}+a_1x^{n-2}+…+a_{n-2}x+a_{n-1}
f(x)=a0xn−1+a1xn−2+…+an−2x+an−1
=
(
1
,
x
,
x
2
,
…
,
)
(
a
n
1
,
a
n
−
2
,
…
,
a
0
)
T
=(1,x,x^2,…,)( a_{n_1}, a_{n-2},…, a_0)^T
=(1,x,x2,…,)(an1,an−2,…,a0)T
这样
(
a
n
−
1
,
a
n
−
2
,
…
,
a
0
)
T
(a_{n-1}, a_{n-2},…, a_0)^T
(an−1,an−2,…,a0)T就是多项式
f
(
x
)
f(x)
f(x)在基
x
1
,
x
2
,
…
,
x
n
x_1,x_2,…,x_n
x1,x2,…,xn的坐标。显然我们可以看成将
f
(
x
)
f(x)
f(x)映射为
(
a
n
−
1
,
a
n
−
2
,
…
,
a
0
)
T
(a_{n-1}, a_{n-2},…, a_0)^T
(an−1,an−2,…,a0)T,这时明显可见映射为线性的,即若
σ
:
f
(
x
)
→
(
a
n
1
,
a
n
2
,
→
,
a
0
)
T
\sigma: f(x)\rightarrow (a_{n_1},a_{n_2},\rightarrow, a_0)^T
σ:f(x)→(an1,an2,→,a0)T
σ
:
g
(
x
)
→
(
b
n
1
,
b
n
2
,
→
,
b
0
)
T
\sigma: g(x)\rightarrow (b_{n_1}, b_{n_2},\rightarrow, b_0)^T
σ:g(x)→(bn1,bn2,→,b0)T
则
σ
:
f
(
x
)
+
g
(
x
)
→
(
a
n
−
1
+
b
n
−
1
,
a
n
−
2
+
b
n
−
2
,
…
,
a
0
+
b
0
)
T
\sigma: f(x)+g(x)\rightarrow (a_{n-1}+b_{n-1}, a_{n-2}+b_{n-2},\dots, a_0+b_0)^T
σ:f(x)+g(x)→(an−1+bn−1,an−2+bn−2,…,a0+b0)T
线性空间定义的说明
(下面涉及的概念在后面会陆续介绍和讨论)
- 任何实(复)线性空间都和通常的实(复)的列向量空间代数同构;
- 为什么要引入抽象的一般化的线性空间的定义:
- 可以把讨论的结论适用于更广的范围
- 由线性映射全体构成的向量空间包括在内,进而推广到无穷维的线性空间中的线性函数
的全体构成的线性空间(泛函)等 - 利于引进更多的代数运算,如向量的代数乘法,从而引出李代数、结合代数等
线性空间与流形的对比
不考,可以忽略
基坐标与坐标变换
这里与线性代数中的向量空间的基坐标与坐标变换,过渡矩阵之类的知识类似。

实(复)矩阵A为奇异矩阵定义为:存在非零n维实(复)向量
x
x
x使得
A
x
=
0
Ax=0
Ax=0.
推论1.2 过渡矩阵非奇异.(自行证明)
从推论1.2我们可以发现,任何一个非奇异矩阵都可以看成是线性空间的两个基之间的过渡矩阵,换句话说,是一个基在另一个基下的坐标表示。
向量在不同基下的表示坐标的关系
设由一个基
x
1
,
x
2
,
…
,
x
n
x_1,x_2,\dots,x_n
x1,x2,…,xn变换为另一个基
y
1
,
y
2
,
…
,
y
n
y_1,y_2,\dots,y_n
y1,y2,…,yn时过渡矩阵为
C
C
C,向量
x
x
x在基
x
1
,
x
2
,
…
,
x
n
x_1,x_2,\dots,x_n
x1,x2,…,xn和基
y
1
,
y
2
,
…
,
y
n
y_1,y_2,\dots,y_n
y1,y2,…,yn的坐标表示分别为
ξ
=
[
ξ
1
,
ξ
2
,
…
,
ξ
n
]
T
,
η
=
[
η
1
,
η
2
,
…
,
η
n
]
T
\xi = [\xi_1,\xi_2,\dots,\xi_n]^T,\eta=[\eta_1,\eta_2,\dots,\eta_n]^T
ξ=[ξ1,ξ2,…,ξn]T,η=[η1,η2,…,ηn]T
则有
x
=
X
⋅
ξ
=
Y
⋅
η
=
(
X
⋅
C
)
⋅
η
=
x
⋅
(
C
⋅
η
)
x=X\cdot \xi=Y\cdot \eta=(X\cdot C)\cdot \eta=x\cdot (C\cdot \eta)
x=X⋅ξ=Y⋅η=(X⋅C)⋅η=x⋅(C⋅η),从而有
ξ
=
C
⋅
η
\xi=C\cdot \eta
ξ=C⋅η或者
η
=
C
−
1
⋅
ξ
\eta=C^{-1}\cdot \xi
η=C−1⋅ξ
或用分量形式推导得
x
=
∑
i
=
1
n
ξ
i
X
i
=
∑
k
=
1
n
η
k
y
k
=
∑
k
=
1
n
η
k
∑
i
=
1
n
c
i
k
x
i
=
∑
i
=
1
n
x
i
∑
k
=
1
n
c
i
k
η
k
x=\sum_{i=1}^{n}\xi_i X_i =\sum_{k=1}^{n}\eta_ky_k = \sum_{k=1}^{n}\eta_k \sum_{i=1}^{n}c_{ik}x_i=\sum_{i=1}^{n}x_i\sum_{k=1}^{n}c_{ik}\eta_{k}
x=i=1∑nξiXi=k=1∑nηkyk=k=1∑nηki=1∑ncikxi=i=1∑nxik=1∑ncikηk
即为
ξ
=
C
⋅
η
\xi=C\cdot \eta
ξ=C⋅η
n维列向量空间 R n R^n Rn(或 C n C^n Cn)的向量与坐标的关系(自然基)
例:对于n维列向量空间
R
n
R^n
Rn(或
C
n
C^n
Cn)的存在一个基
{
e
i
,
i
=
1
,
2
,
…
,
n
}
\{e_i,i=1,2,…,n\}
{ei,i=1,2,…,n},其中
e
i
e_i
ei的第
i
i
i个分量为
1
1
1,其余分量为0;这个基称为
R
n
R_n
Rn(或
C
n
C_n
Cn)的自然基。在自然基下,
R
n
R^n
Rn(或
C
n
C^n
Cn)中的任意向量
x
x
x和它在自然基下的表示坐标
ξ
\xi
ξ是完全一致的。即
x
=
∑
i
=
1
n
ξ
i
e
i
=
∑
i
=
1
n
x
i
e
i
x=\sum_{i=1}^n\xi_i e_i =\sum_{i=1}^nx_i e_i
x=i=1∑nξiei=i=1∑nxiei
所以在 R n R^n Rn(或 C n C^n Cn)中,除非特别指明,我们一般都假设它的基为自然基,这时向量和它的坐标表示在形式上完全相同,这种情况下我们不加区别的用同一符号表示,但具体的含义应该根据上下文加以区别。
(自己的碎碎念:之前证明了线性空间与实复数域空间同构,为了用实数域空间方便的表示线性空间的性质。现在引入自然基,为了说实复空间中的向量与它在自然基下的表示是完全一致的。为了在实数域空间更方便的表示向量)
n的维列向量空间 R n R^n Rn(或 C n C^n Cn)的基、向量组与矩阵关系
假设在
R
n
R^n
Rn(或
C
n
C^n
Cn)中的另外一个基为
Y
=
(
y
1
,
y
2
,
…
,
y
n
)
Y=(y_1,y_2,\dots,y_n)
Y=(y1,y2,…,yn),那么Y和自然基
I
=
(
e
1
,
e
2
,
…
,
e
n
)
I=(e_1, e_2,\dots,e_n)
I=(e1,e2,…,en) 的过渡矩阵B为
Y
=
I
⋅
B
Y=I·B
Y=I⋅B。很明显
B
=
Y
B=Y
B=Y,即
B
B
B的每个元素和
Y
Y
Y的每个元素在数值上是完全相同的。因此,很多时候我们将
R
n
R^n
Rn(或
C
n
C^n
Cn)中的基看作一个可逆矩阵,并且进行矩阵的代数运算。究其本质上来说,运算的对象是该基在自然基下的过渡矩阵,很多时候为了简单起见并
没有明确说明取自然基。
同样的,对于
R
n
R^n
Rn(或
C
n
C^n
Cn)中的向量组
Y
=
(
y
1
,
y
2
,
…
,
y
r
)
Y=(y^1,y^2,\dots,y^r)
Y=(y1,y2,…,yr),我们也可以看作矩阵,
进行矩阵运算。从严格意义上说,其实作为矩阵的
Y
Y
Y只不过表示的是作为向量组的
Y
Y
Y的在自然基下的坐标表示组成矩阵。由于在数值上完全相同,因此很多时候我们可以使用同样的符号,并且省略自然基的表示这样的说法。在使用中可以根据上下文进行正确理解和使用。
线性子空间
线性子空间定义
定义:设
V
1
V_1
V1是数域
K
K
K上线性空间
V
V
V的非空子集合,且对V己有的线性运算满足以下条件
(1)对加法封闭:若
x
,
y
∈
V
1
x,y\in V_1
x,y∈V1,则
x
+
y
∈
V
1
x+y \in V_1
x+y∈V1
(2)对数乘封闭:若
x
∈
V
1
,
k
∈
K
x\in V_1,k\in K
x∈V1,k∈K,则
k
•
x
∈
V
1
k•x\in V_1
k•x∈V1.
则称
V
1
V_1
V1为
V
V
V的线性子空间或子空间。
仅由
0
0
0元素构成的子空间为零子空间。
注意:零子空间的维数为0而不是1。
子空间的运算:交, 和, 直和
两个子空间 V 1 , V 2 V_1,V_2 V1,V2的交 V 1 ∩ V 2 V_1\cap V_2 V1∩V2仍为子空间。
定义1.8 设
V
1
,
V
2
V_1,V_2
V1,V2为数域
K
K
K上的线性空间
V
V
V的子空间,且
x
∈
V
1
,
y
∈
V
2
x\in V_1,y\in V_2
x∈V1,y∈V2则由
x
+
y
x+y
x+y的全体构成的集合称为V_I和V_2的和,记为
V
I
+
V
2
VI+V2
VI+V2.记
V
1
+
V
2
=
{
z
丨
z
=
x
+
y
,
x
∈
V
1
,
y
∈
V
2
}
V_1+V_2=\{z丨z=x+y,x\in V_1,y\in V_2\}
V1+V2={z丨z=x+y,x∈V1,y∈V2}。
显然·两个子空间
V
1
,
V
2
V_1,V_2
V1,V2的和
V
1
+
V
2
V_1+V_2
V1+V2仍为子空间,并且交与和分别满足结合律,
即
(
V
1
∩
V
2
)
∩
V
3
=
V
I
∩
(
V
2
∩
V
3
)
(V_1\cap V_2)\cap V_3 = V_I \cap (V_2 \cap V_3)
(V1∩V2)∩V3=VI∩(V2∩V3),
(
V
1
+
V
2
)
+
V
3
=
V
1
+
(
V
2
+
V
3
)
(V_1+ V_2)+ V_3 = V_1 + (V_2 + V_3)
(V1+V2)+V3=V1+(V2+V3),
从而它们都可以推广到几个子空间的情形,并且
V
1
∩
V
2
∩
⋯
∩
V
n
V_1\cap V_2 \cap \dots \cap V_n
V1∩V2∩⋯∩Vn 或
V
1
+
V
2
+
⋯
+
V
n
V_1+V_2+\dots + V_n
V1+V2+⋯+Vn有意义。
子空间和的维度公式
d i m V 1 + d i m V 2 = d i m ( V 1 + V 2 ) + d i m ( V 1 ∩ V 2 ) dim V_1+dim V_2=dim (V_1+V_2)+dim(V_1 \cap V_2) dimV1+dimV2=dim(V1+V2)+dim(V1∩V2)
证明思路:从最小的子空间V1V2出发构造它的一个基X12,然后分别扩展成V1的一个基{X12,X1}和V2的一个基{X12,X2},最后证明向量组{X12,X1,X2}为V1+V2的一个基,从而命题得证
直和的定义和性质
直和的定义: 若
V
1
∩
V
2
=
0
V_1\cap V_2 = 0
V1∩V2=0,则
V
1
+
V
2
V_1+V_2
V1+V2为
V
1
,
V
2
V_1,V_2
V1,V2的直和,记为
V
1
⊕
V
2
V_1\oplus V2
V1⊕V2。
直和的性质:对于
V
1
⊕
V
2
V_1\oplus V_2
V1⊕V2中的元素在
V
I
V_I
VI和
V
2
V_2
V2分别存在唯一
x
x
x和
y
y
y,使得
z
=
x
+
y
z=x+y
z=x+y.即
z
z
z的分解唯一
这个性质实际构成了直和定义的背景,也就是说,如果知道
V
1
V_1
V1和
V
2
V_2
V2,我们可以得到
V
1
+
V
2
V_1+V_2
V1+V2,但是反过来,如果知道两个子空间
V
3
V_3
V3和
V
1
V_1
V1,且
V
1
⊆
V
3
V_1 \subseteq V_3
V1⊆V3我们是否可以知道唯一的字空间
V
2
V_2
V2使得
V
1
+
V
2
=
V
3
V_1+V_2=V_3
V1+V2=V3。直和的定义告诉我们应该如何约束
V
2
V_2
V2得到唯一性。
直和的简单性质
V
1
⊕
V
2
⇔
d
i
m
(
V
1
∩
V
2
)
=
0
V_1\oplus V_2 \Leftrightarrow dim(V_1\cap V_2)=0
V1⊕V2⇔dim(V1∩V2)=0
⇔
d
i
m
V
1
+
d
i
m
V
2
=
d
i
m
(
V
1
⊕
V
2
)
\Leftrightarrow dim V_1+dim V_2=dim (V_1\oplus V_2)
⇔dimV1+dimV2=dim(V1⊕V2)
子空间的构成
(1)由几个子空间的交或和构成。
(2)向量
x
1
,
x
2
,
…
,
x
m
x_1,x_2,\dots,x_m
x1,x2,…,xm组扩张而成。
由单个非零向量x对数乘运算封闭构成的一维子空间
L
(
x
)
=
{
z
∣
z
=
k
⋅
x
,
k
∈
K
}
.
L(x)=\{z | z=k·x, k\in K\}.
L(x)={z∣z=k⋅x,k∈K}.
同理记
L
(
x
1
,
x
2
,
…
,
x
m
)
=
L
(
x
1
)
+
L
(
x
2
)
+
⋯
+
L
(
x
m
)
L(x_1,x_2,\dots,x_m)=L(x_1)+L(x_2)+\dots+L(x_m)
L(x1,x2,…,xm)=L(x1)+L(x2)+⋯+L(xm)
显然
d
i
m
(
L
(
x
1
,
x
2
,
…
,
x
m
)
)
≤
m
dim(L(x1,x2,\dots,xm)) \le m
dim(L(x1,x2,…,xm))≤m
思考题1:一个n维线性空间的真子空间有多少?
思考题2:若
V
1
,
V
2
,
…
,
V
m
V_1,V_2,\dots,V_m
V1,V2,…,Vm为线性空间
V
V
V的真子空间,证明存在一个向量
x
∈
V
x\in V
x∈V但
x
∉
V
1
∪
V
2
∪
⋯
∪
V
m
x\notin V_1\cup V_2\cup \dots \cup V_m
x∈/V1∪V2∪⋯∪Vm成立。
矩阵列向量构成的子空间
定义:
在实线性空间
R
m
R^m
Rm中矩阵
A
=
(
a
i
j
)
∈
R
m
×
n
A=(a_{ij})\in R^{m\times n}
A=(aij)∈Rm×n的列向量构成的
子空间
L
(
a
1
,
a
2
,
…
,
a
n
)
L(a_1,a_2,\dots,a_n)
L(a1,a2,…,an)称为矩阵
A
A
A的值域(列空间),记为
R
(
A
)
=
L
(
a
1
,
a
2
,
…
,
a
n
)
⊂
R
R(A)=L(a_1,a_2,\dots,a_n)\subset R
R(A)=L(a1,a2,…,an)⊂R
矩阵的秩
矩阵的列秩:由矩阵的列向量构成的最大无关组的个数。
矩阵的行秩:由矩阵的行向量构成的最大无关组的个数。
定理: 矩阵的行秩和列秩相同。
证明:由于
r
a
n
k
(
A
)
=
r
a
n
k
(
A
A
T
)
≤
r
a
n
k
(
A
T
)
rank(A)=rank(AA^T)\le rank(A^T)
rank(A)=rank(AAT)≤rank(AT)
同样,
r
a
n
k
(
A
T
)
≤
r
a
n
k
(
A
)
rank(A^T) \le rank(A)
rank(AT)≤rank(A)
这样,
r
a
n
k
(
A
)
=
r
a
n
k
(
A
T
)
rank(A)= rank(A^T)
rank(A)=rank(AT),
即矩阵的行秩和列秩相同.
从而它们称为矩阵的秩,记为
r
a
n
k
(
A
)
rank(A)
rank(A).由矩阵列秩的定义显然可得:
定理
d
i
m
(
R
(
A
)
)
=
r
a
n
k
(
A
)
dim(R(A))=rank(A)
dim(R(A))=rank(A).
证明:利用自然基,由A的列向量和它的表示坐标的一一对应关系证明结论。
这个定理建立了矩阵秩和它的值域空间维数的等价关系,从而为利用子空间的维数研究矩阵的秩
给出了另外一种方法,后面我们会举例说明。
核空间(类似于向量空间的解空间,n-r(A)=解的秩)
定义1.7 设在实线性空间
R
n
R^n
Rn中矩阵
A
=
(
a
i
j
)
∈
R
m
×
n
A=(a_{ij})\in R^{m\times n}
A=(aij)∈Rm×n,称集合
x
∣
A
x
=
0
{x|Ax=0}
x∣Ax=0为矩阵A的核空间,记为
N
(
A
)
N(A)
N(A),即
N
(
A
)
=
x
∣
A
x
=
0
∈
R
n
.
N(A)={x|Ax=0}\in R^n.
N(A)=x∣Ax=0∈Rn.
称N(A)的维数为A的零度,记为
n
(
A
)
n(A)
n(A),即
n
(
A
)
=
d
i
m
(
N
(
A
)
)
n(A)=dim(N(A))
n(A)=dim(N(A)).
定理: d i m ( R ( A ) ) + d i m ( N ( A ) ) = n dim(R(A))+dim(N(A))=n dim(R(A))+dim(N(A))=n.
证明思路:构造 N ( A ) N(A) N(A)的一个基 X 1 X_1 X1,将它扩张成 R n R^n Rn的一个基 X 1 , X 2 {X1,X2} X1,X2,然后证明 A X 2 AX_2 AX2为 R ( A ) R(A) R(A)的一个基,从而命题得证。
思考:若 A ∈ C n × n A\in C^{n\times n} A∈Cn×n, R ( A ) ⊕ N ( A ) R(A)\oplus N(A) R(A)⊕N(A)成立吗?举例说明?成立的条件是什么?
1.2线性映射,线性函数,线性变换及它们的矩阵表示
表示是什么?表示究是本质来说是一种映射,它把我们不熟悉或抽象的事物映射为我们熟知或具体的事物。
例如:抽象的线性空间在一个基下可表示为实或复的列向量空间。
同样地,线性空间之间的线性映射都可以表示为矩阵。这正是矩阵的代数本质所在。(向量为特殊的矩阵)
这就是本节所研究的内容
线性映射
建议先看百度百科的线性代数定义:线性映射( linear mapping)是从一个向量空间V到另一个向量空间W的映射且保持加法运算和数量乘法运算,而线性变换(linear transformation)是线性空间V到其自身的线性映射。
再看一下【线性代数】三、线性映射里的线性映射与线性映射的表示部分。主要是为了解决①转换维度的问题(n维转成m维)②向量映射后的可加性问题 f ( b ) = f ( b 1 e 1 + ⋯ + b n e n ) = b 1 f ( e 1 ) + ⋯ + b n f ( e n ) f(b)=f(b_1e_1+\dots+b_ne_n)=b_1f(e_1)+\dots+b_nf(e_n) f(b)=f(b1e1+⋯+bnen)=b1f(e1)+⋯+bnf(en)来方便我们计算
定义:
数域相同的线性空间 X X X到线性空间 Y Y Y的映射 T T T称为线性映射,若 T T T满足下列条件:
- T ( x + y ) = T ( x ) + T ( y ) T(x+y)=T(x)+T(y) T(x+y)=T(x)+T(y)
- T ( k x ) = k T ( x ) T(kx)=kT(x) T(kx)=kT(x)
(PS:自己的碎碎念: 第一章所做的都是利用定义把复杂的线性空间(符合那八条性质的向量空间),缩减到简单的线性空间(子空间),通过基,线性映射,映射到我们熟悉的空间(矩阵的列向量空间)来解决问题(核空间就是解空间,帮助我们解决问题)。)
线性映射的表示
若线性空间 W W W和线性空间 V V V的维数分别为: m = d i m ( W ) , n = d i m ( V ) , x 1 , x 2 , … , x m m=dim(W),n=dim(V),x_1,x_2,\dots,x_m m=dim(W),n=dim(V),x1,x2,…,xm以及 y 1 , y 2 , … , y n y_1,y_2,\dots,y_n y1,y2,…,yn分别为 W W W和 V V V的一个基,则线性映射可以表示为一个 R n × m R^{n\times m} Rn×m(或者 C n × m C^{n\times m} Cn×m)的矩阵。
(PS:自己的碎碎念:这里的定义是为了告诉我们如何去计算一个线性映射的问题。(用一个线性映射的矩阵))
设向量
T
x
i
T_{x_i}
Txi在基
y
1
,
y
2
,
…
,
y
n
y_1,y_2,\dots,y_n
y1,y2,…,yn的坐标表示为
T
x
i
=
(
y
1
,
y
2
,
…
,
y
n
)
(
a
1
i
,
a
2
i
,
…
,
a
n
i
)
T
T_{xi} =(y_1,y_2,\dots,y_n) (a_{1i},a_{2i},\dots,a_{ni})^T
Txi=(y1,y2,…,yn)(a1i,a2i,…,ani)T
=
(
y
1
,
y
2
,
…
,
y
n
)
a
i
,
i
=
1
,
2
,
…
,
m
=(y1,y2,…,yn)a_i,i=1,2,…,m
=(y1,y2,…,yn)ai,i=1,2,…,m
记矩阵
A
=
(
a
1
,
a
2
,
…
,
a
m
)
A=(a_1,a_2,\dots,a_m)
A=(a1,a2,…,am),
而基为
Y
=
(
y
1
,
y
2
,
…
,
y
n
)
,
X
=
(
x
1
,
x
2
,
…
,
x
m
)
Y=(y_1,y_2,\dots,y_n), X= (x_1,x_2,\dots,x_m)
Y=(y1,y2,…,yn),X=(x1,x2,…,xm)。
则有
T
X
=
(
T
x
1
,
T
x
2
,
…
,
T
x
m
)
=
Y
⋅
A
(
2.1
)
TX=(T_{x_1},T_{x_2},\dots,T_{x_m})=Y\cdot A (2.1)
TX=(Tx1,Tx2,…,Txm)=Y⋅A(2.1)
对任意向量
x
x
x在基
x
1
,
x
2
,
…
,
x
m
x_1,x_2,\dots,x_m
x1,x2,…,xm的坐标表示为
ξ
=
[
ξ
1
,
ξ
2
,
…
,
ξ
m
]
T
\xi=[\xi_1,\xi_2,\dots,\xi_m]^T
ξ=[ξ1,ξ2,…,ξm]T,向量
T
x
T_x
Tx在基
y
1
,
y
2
,
…
,
y
n
y_1,y_2,\dots,y_n
y1,y2,…,yn的坐标表示为
η
=
[
η
1
,
η
2
,
…
,
η
n
]
T
\eta =[\eta_1,\eta_2,\dots,\eta_n]^T
η=[η1,η2,…,ηn]T,那么我们有
T
x
=
Y
⋅
η
=
T
(
X
⋅
ξ
)
=
(
T
X
)
⋅
ξ
Tx=Y\cdot \eta=T(X\cdot\xi)=(TX) \cdot\xi
Tx=Y⋅η=T(X⋅ξ)=(TX)⋅ξ
=
(
T
x
1
,
T
x
+
2
,
…
,
T
x
m
)
⋅
ξ
=
Y
⋅
(
A
ξ
)
=(T_{x_1},T_{x_+2},\dots,T_{x_m}) \cdot\xi=Y\cdot(A\xi )
=(Tx1,Tx+2,…,Txm)⋅ξ=Y⋅(Aξ)
⇒
η
=
A
ξ
(
2.2
)
\Rightarrow\eta=A\xi (2.2)
⇒η=Aξ(2.2)
从而对于线性映射
T
T
T,在基
X
X
X和
Y
Y
Y的下的表示为矩阵
A
A
A.
(PS:自己的碎碎念:如何理解这里的推导。 X X X和 Y Y Y是两个基; x , y x,y x,y是两个基下的向量, ξ \xi ξ和 η \eta η是 x x x和 y y y在基 X X X与基 Y Y Y下的坐标表示,现在要用线性映射 T T T,把向量 x x x从基 X X X下映射到基 Y Y Y下,把我说的这句话搞懂,而 A A A是对基 X X X做线性映射 T X TX TX得到 Y Y Y的矩阵( T X = Y A TX=YA TX=YA)。这里的推导意思是:知道了基的线性映射,如何求一个基 X X X下的向量 x x x映射到基 Y Y Y下的向量 y y y(自然就是利用基的转移矩阵 A A A来方便向量的映射的计算)。把我这里的碎碎念理解了(基与基的映射,转移矩阵A,向量与向量的映射),上面的推导就全能看懂了)
线性映射的图示
从而对于线性映射
T
T
T,在基
X
X
X和
Y
Y
Y的下的表示为矩阵
A
A
A.
T
:
x
→
y
=
T
x
其中
x
=
X
ξ
,
y
=
Y
η
T : x \rightarrow y = T x 其中x=X\xi, y=Y\eta
T:x→y=Tx其中x=Xξ,y=Yη
↓
↓
↓
\ \ \ \ \ \ \downarrow \ \ \ \ \ \ \ \downarrow \ \ \ \ \ \downarrow
↓ ↓ ↓
A
:
ξ
→
η
=
A
ξ
A: \xi \rightarrow \eta = A \xi
A:ξ→η=Aξ
注意对于同一映射,若基X和Y选择不同,则T的表示A一般不相同。
(PS:自己的碎碎念:原来latex里打空格不用\quad和\qquad, 直接’\ ',一个转义字符后面跟着一个空格就行了)
线性映射在不同基下的各种表示
一个很自然的问题:
线性映射在不同基下的各种表示之间的关系如何?
线性映射的矩阵表示
若用映射的形式我们可以将线性映射的矩阵表示记为:
A
=
σ
(
T
;
X
,
Y
)
(
2.3
)
A=\sigma (T; X,Y) \ \ \ (2.3)
A=σ(T;X,Y) (2.3)
(PS:自己的理解对不对?果然就是要求基与基之间映射的矩阵关系。这里的公式好好看,指的是基X与基Y在线性映射T下的得到的矩阵A)
线性映射在不同基下的矩阵表示的关系式
设线性空间
W
W
W的另一组基为
X
′
X'
X′,且
X
′
=
X
C
X'=XC
X′=XC,线性空间
V
V
V的另一组基为
Y
′
Y'
Y′,且
Y
′
=
Y
D
Y'=YD
Y′=YD,或
Y
=
Y
′
D
−
1
Y=Y'D^{-1}
Y=Y′D−1
(注意,因为C和D分别为过渡矩阵,从而可逆)
设线性映射
T
T
T在基
x
′
x'
x′和
Y
′
Y'
Y′下的矩阵为
A
′
A'
A′,即
T
X
′
=
Y
′
A
′
TX'=Y'A'
TX′=Y′A′
则
T
X
′
=
T
(
X
C
)
=
(
T
X
)
C
(
由
(
2
⋅
1
)
)
TX'=T(XC)=(TX)C(由(2·1))
TX′=T(XC)=(TX)C(由(2⋅1))
=
(
Y
A
)
C
=
Y
(
A
C
)
=
Y
′
D
−
1
A
C
=
Y
′
A
′
=(YA)C=Y(AC)=Y'D^{-1}AC=Y'A'
=(YA)C=Y(AC)=Y′D−1AC=Y′A′
从而我们有
A
′
=
D
−
1
A
C
(
2
⋅
4
)
A'=D^{-1}AC (2·4)
A′=D−1AC(2⋅4)
这就是线性映射在不同基下的矩阵表示的关系式。
注意:
D
∈
R
n
×
n
,
A
∈
R
n
×
m
,
C
∈
R
m
×
m
D\in R^{n\times n} , A\in R^{n \times m} , C\in R^{m\times m}
D∈Rn×n,A∈Rn×m,C∈Rm×m
线性映射的复合
S
:
W
→
V
;
T
:
V
→
Z
S: W\rightarrow V; T: V\rightarrow Z
S:W→V;T:V→Z 定义
(
T
o
S
)
(
x
)
=
T
(
S
(
x
)
)
(ToS)(x)=T(S(x))
(ToS)(x)=T(S(x)). 其中
W
W
W,
V
V
V和
Z
Z
Z为线性空间,
S
S
S和
T
T
T都为线性映射。 很明显, 线性映射的复合仍为线性映射。
设
x
1
,
x
2
,
…
,
x
m
x_1, x_2,\dots,x_m
x1,x2,…,xm为
W
W
W的一个基,
y
1
,
y
2
,
…
,
y
n
y_1,y_2,\dots,y_n
y1,y2,…,yn为
V
V
V的一个基,
z
1
,
z
2
,
…
,
z
r
z_1,z_2,\dots,z_r
z1,z2,…,zr为
Z
Z
Z的一个基,
S
S
S在
W
W
W和
V
V
V的当前基下的表示为
A
A
A, 而
T
T
T在
V
V
V和
Z
Z
Z的当前基下的表示为
B
B
B,则它们的复合ToS在当前基下的矩阵表示为BA.
由于映射的复合一般不可交换,从而对应的矩阵的乘法也不可交换, 即
B
A
=
A
B
BA=AB
BA=AB一般不成立。
思考题:
根据(2.3),若用映射的形式我们可以表示为:
B
A
=
σ
(
T
o
S
;
X
,
Z
)
BA=\sigma(ToS; X, Z)
BA=σ(ToS;X,Z)
可见,
T
o
S
ToS
ToS的矩阵表示和
V
V
V的基
Y
Y
Y的选择无关,假如选择另外一组
V
V
V的基
Y
′
Y'
Y′,证明这一点
(自己的碎碎念:PPT里的思考题一定要做,不然考试的时候没时间想那么多。其次,应该熟悉这种映射所对应的矩阵的表达方式了吧?基是 X X X和 Z Z Z,映射是 T o S ToS ToS,所对应的矩阵是 B A = σ ( T o s ; X , Z ) BA=\sigma(Tos;X,Z) BA=σ(Tos;X,Z))
定理:设
T
T
T为线性空间
W
W
W到线性空间
V
V
V的线性映射,则
W
W
W内的线性子空间
W
1
W_1
W1在
V
V
V中的象
V
1
V_1
V1为
V
V
V的线性子空间。
反之,
V
V
V中的线性子空间
V
1
V_1
V1的逆象
T
−
1
(
V
1
)
=
{
x
∣
∃
y
∈
V
1
s
.
t
.
y
=
T
x
}
T^{-1}(V_1)=\{ x | \exists y \in V_1 \ \ s.t.\ \ y=Tx\}
T−1(V1)={x∣∃y∈V1 s.t. y=Tx}
也为
W
W
W中的线性子空间。
证明:利用子空间的定义,显然可以得到。
定理:设 T T T为线性空间 W W W到线性空间 V V V的线性映射, W 1 W_1 W1, W 2 W_2 W2为 W W W内的子空间,则
- T ( W 1 + W 2 ) = T ( W 1 ) + T ( W 2 ) T(W1+W2)= T(W1)+T(W2) T(W1+W2)=T(W1)+T(W2)
-
T
(
W
1
∩
W
2
)
∈
T
(
W
1
)
∩
T
(
W
2
)
T(W1\cap W2) \in T(W1) \cap T(W2)
T(W1∩W2)∈T(W1)∩T(W2)
(思考为什么等式不能成立?)
线性映射的维数公式
(PS:象是映射里的概念)
记R(T)为
W
W
W在
V
V
V中的象,称之为值域, 即
R
(
T
)
=
{
y
∈
V
∣
y
=
T
x
,
∀
x
∈
W
}
R(T)=\{ y\in V | y=Tx, \forall x\in W \}
R(T)={y∈V∣y=Tx,∀x∈W}
记
N
(
T
)
N(T)
N(T)为
V
V
V中零向量空间的逆象
T
−
1
(
0
)
T^{-1}(0)
T−1(0),称之为T的核,
即
N
(
T
)
=
{
x
∣
T
x
=
0
,
x
∈
W
}
N(T)=\{ x| Tx=0, x\in W \}
N(T)={x∣Tx=0,x∈W}
T
T
T的值域
R
(
T
)
R(T)
R(T)的维数
d
i
m
(
R
(
T
)
)
dim(R(T))
dim(R(T))称为T的秩,其核子空
间的维数dim(N(T))称为T的亏度。
定理:
d
i
m
(
R
(
T
)
)
+
d
i
m
(
N
(
T
)
)
=
d
i
m
(
W
)
dim(R(T))+ dim(N(T))=dim(W)
dim(R(T))+dim(N(T))=dim(W)
(PS:自己的碎碎念:这里的核或核空间,基本就指的解或解空间。亏度就是指解空间的维数(解空间最大线性无关组的秩。“值域秩+解空间秩=定义域秩” 和n-r(A)以及线性方程组的秩区分开。)
上面那个线性映射的维数公式的证明:设
x
1
,
x
2
,
…
,
x
r
x_1,x_2,\dots,x_r
x1,x2,…,xr为
N
(
T
)
N(T)
N(T)的一个基,扩充它们使之为
W
W
W的一个基:
x
1
,
x
2
,
…
,
x
r
,
x
r
+
1
,
…
,
x
n
x_1,x_2,\dots,x_r,x_{r+1},\dots,x_n
x1,x2,…,xr,xr+1,…,xn,那么我们证明
T
(
x
r
+
1
)
,
…
,
T
(
x
n
)
T(x_{r+1}),\dots,T(x_n)
T(xr+1),…,T(xn)为
R
(
T
)
R(T)
R(T)的一个基。首先证明
T
(
x
r
+
1
)
,
…
,
T
(
x
n
)
T(x_{r+1}),\dots,T(x_n)
T(xr+1),…,T(xn)线性无关.设
t
r
+
1
T
(
x
r
+
1
)
+
⋯
+
t
−
n
T
(
x
n
)
=
0
t_{r+1}T(x_{r+1})+\dots+t-nT(x_n)=0
tr+1T(xr+1)+⋯+t−nT(xn)=0则
T
(
t
r
+
1
x
r
+
1
+
⋯
+
t
n
x
n
)
=
0
T(t_{r+1}x_{r+1}+\dots+t_nx_n)=0
T(tr+1xr+1+⋯+tnxn)=0,从而
t
r
+
1
x
r
+
1
+
⋯
+
t
n
x
n
∈
N
(
T
)
t_{r+1}x_{r+1}+\dots+t_nx_n\in N(T)
tr+1xr+1+⋯+tnxn∈N(T)所以
t
r
+
1
x
r
+
1
+
⋯
+
t
n
x
n
t_{r+1}x_{r+1}+\dots+t_nx_n
tr+1xr+1+⋯+tnxn能够被
x
1
,
x
2
,
…
,
x
r
x_1,x_2,\dots,x_r
x1,x2,…,xr线性表示。因此存在
t
1
,
…
,
t
r
t_1,\dots,t_r
t1,…,tr使得
t
1
x
1
+
⋯
+
t
r
x
r
=
t
r
+
1
x
r
+
1
+
⋯
+
t
n
x
n
t_1x_1+\dots+t_rx_r=t_{r+1}x_{r+1}+\dots+t_nx_n
t1x1+⋯+trxr=tr+1xr+1+⋯+tnxn,
即
t
1
x
1
+
⋯
+
t
r
x
r
−
t
r
+
1
x
r
+
1
−
⋯
−
t
n
x
n
=
0
t_1x_1+\dots+t_rx_r−t_{r+1}x_{r+1}−\dots−t_nx_n=0
t1x1+⋯+trxr−tr+1xr+1−⋯−tnxn=0
因此
t
1
=
t
2
=
⋯
=
t
r
=
t
r
+
1
=
⋯
=
t
n
=
0
t_1=t_2=\dots=t_r=t_{r+1}=\dots=t_n=0
t1=t2=⋯=tr=tr+1=⋯=tn=0
这样就说明T(xr+1),…,T(xn)线性无关。
其次我们证明对于任给
y
∈
R
(
T
)
y\in R(T)
y∈R(T),
y
y
y能被
T
(
x
r
+
1
)
,
…
,
T
(
x
n
)
T(x_{r+1}),\dots,T(x_n)
T(xr+1),…,T(xn)线性表示. 由于
y
∈
R
(
T
)
y\in R(T)
y∈R(T),因此存在
x
∈
W
x\in W
x∈W使得
y
=
T
(
x
)
y=T(x)
y=T(x). 由于
x
1
,
x
2
,
…
,
x
r
,
x
r
+
1
,
…
,
x
n
x_1,x_2,\dots,x_r,x_{r+1},\dots,x_n
x1,x2,…,xr,xr+1,…,xn为
W
W
W一个基,因此存在
t
1
,
…
,
t
r
,
t
r
+
1
,
…
,
t
n
t_1,\dots,t_r,t_{r+1},\dots,t_n
t1,…,tr,tr+1,…,tn使得
x
=
t
1
x
1
+
⋯
+
t
r
x
r
+
t
r
+
1
x
r
+
1
+
⋯
+
t
n
x
n
x=t_1x_1+\dots+t_rx_r+t_{r+1}x_{r+1}+\dots+t_nx_n
x=t1x1+⋯+trxr+tr+1xr+1+⋯+tnxn
从而
y
=
T
(
x
)
=
T
(
t
1
x
1
+
⋯
+
t
r
x
r
+
t
r
+
1
x
r
+
1
+
⋯
+
t
n
x
n
)
从而y=T(x)=T(t_1x_1+\dots+t_rx_r+t_{r+1}x_{r+1}+\dots+t_nx_n)
从而y=T(x)=T(t1x1+⋯+trxr+tr+1xr+1+⋯+tnxn)
=
t
1
T
(
x
1
)
+
⋯
+
t
r
T
(
x
r
)
+
t
r
+
1
T
(
x
r
+
1
)
+
⋯
+
t
n
T
(
x
n
)
= t_1T(x_1)+\dots+t_rT(x_r)+t_{r+1}T(x_{r+1})+\dots+t_nT(x_n)
=t1T(x1)+⋯+trT(xr)+tr+1T(xr+1)+⋯+tnT(xn)
=
t
r
+
1
T
(
x
r
+
1
)
+
⋯
+
t
n
T
(
x
n
)
= t_{r+1}T(x_{r+1})+\dots+t_nT(x_n)
=tr+1T(xr+1)+⋯+tnT(xn)
因此
y
y
y能够被
T
(
x
r
+
1
)
,
…
,
T
(
x
n
)
T(x_{r+1}),\dots,T(x_n)
T(xr+1),…,T(xn)线性表示。同时由于
T
(
x
r
+
1
)
,
…
,
T
(
x
n
)
T(x_{r+1}),\dots,T(x_n)
T(xr+1),…,T(xn)线性无关。这样它们就构成了
R
(
T
)
R(T)
R(T)的一个基。从而有
d
i
m
(
R
(
T
)
)
+
d
i
m
(
N
(
T
)
)
=
d
i
m
(
W
)
dim(R(T))+ dim(N(T))=dim(W)
dim(R(T))+dim(N(T))=dim(W)证毕.
维
(PS:扩充向量为基时,用到了Ax=0时 "n-r(A)=解的秩"的知识,所以可以用来扩充)
(这里用到了线性映射:
①
T
(
x
+
y
)
=
T
(
x
)
+
T
(
y
)
②
T
(
k
x
)
=
k
T
(
x
)
①T(x+y)=T(x)+T(y)②T(kx)=kT(x)
①T(x+y)=T(x)+T(y)②T(kx)=kT(x)的两条性质。)
维数公式的应用
例:对于 R n R^n Rn到 R m R^m Rm的线性映射 T T T, 对于任给 x ∈ R n , T ( x ) = A x x\in R^n,T(x)=Ax x∈Rn,T(x)=Ax,其中 A A A为 R m × n R^{m\times n} Rm×n的矩阵,这时 R ( T ) = R ( A ) R(T)=R(A) R(T)=R(A),即 A A A的列向量构成的线性子空间. N ( T ) N(T) N(T)为 A x = 0 Ax=0 Ax=0的解的全体构成的子空间.
由
d
i
m
(
R
(
T
)
)
+
d
i
m
(
N
(
T
)
)
=
d
i
m
(
W
)
dim(R(T))+ dim(N(T))=dim(W)
dim(R(T))+dim(N(T))=dim(W)
可以看出,
A
x
=
0
Ax=0
Ax=0的基础解系的个数为
n
−
r
(
A
)
n−r(A)
n−r(A),
其中
r
(
A
)
=
R
(
T
)
r(A)=R(T)
r(A)=R(T)为
A
A
A的秩.
这个结论我们在高等数学里已经得到过
(PS:注意这里的 r ( A ) = r ( T ) r(A)=r(T) r(A)=r(T),现在终于可以方便的计算线性映射了)
线性映射构成的空间
对于
W
W
W到
V
V
V的两个的线性映射
T
1
T_1
T1和
T
2
T_2
T2分别定义它们的加法和数乘如下:
(
T
1
+
T
2
)
(
x
)
=
T
1
x
+
T
2
x
(
2.4
)
(T_1+T_2)(x)=T_1x+T_2x (2.4)
(T1+T2)(x)=T1x+T2x(2.4)
(
k
T
1
)
(
x
)
=
k
(
T
1
x
)
(
2.5
)
(kT_1)(x) = k (T_1x) (2.5)
(kT1)(x)=k(T1x)(2.5)
那么有以下定理:
定理2.4:所有W到V的线性映射的全体按(2.4)和(2.5)定义的加法和数乘构成一个线性空间。这个空间的维数为mn.
(PS:这里应该意思是线性映射可以进一步的组合)
线性映射和矩阵
从这里我们可以看到:
- 借助矩阵表示,我们可以完全利用矩阵运算研究线性映射;
- 其实反过来也是对的,即,有时我们可以借助线性映射来研究矩阵。有时候,如果我们利用线性映射的某些特点可以证明矩阵的某些性质,如下例所示
(实际上前面的那些定义就是为了让我们方便的理解线性映射和矩阵的关系,实际上的计算基本都是用矩阵来完成的。)

注意这句:线性映射T在自然基下的表示矩阵为A
(问一下同学这里C_r^{m\times n}是啥意思)
线性映射复合的维数公式:
定理:
d
i
m
(
N
(
A
B
)
)
=
d
i
m
(
N
(
B
)
)
+
d
i
m
(
N
(
A
)
∩
R
(
B
)
)
dim(N(AB))=dim(N(B))+ dim(N(A)\cap R(B))
dim(N(AB))=dim(N(B))+dim(N(A)∩R(B))
d
i
m
(
R
(
A
B
)
)
=
d
i
m
(
R
(
B
)
)
−
d
i
m
(
N
(
A
)
∩
R
(
B
)
)
dim(R(AB))=dim(R(B)) − dim(N(A)\cap R(B))
dim(R(AB))=dim(R(B))−dim(N(A)∩R(B))
推论: 1)
r
a
n
k
(
A
)
+
r
a
n
k
(
B
)
−
n
≤
r
a
n
k
(
A
B
)
rank(A)+rank(B)−n \leq rank(AB)
rank(A)+rank(B)−n≤rank(AB)
2)
d
i
m
(
R
(
A
B
)
)
+
d
i
m
(
R
(
B
C
)
)
−
d
i
m
(
R
(
B
)
)
≤
d
i
m
(
R
(
A
B
C
)
dim(R(AB))+dim(R(BC))− dim(R(B)) \leq dim(R(ABC)
dim(R(AB))+dim(R(BC))−dim(R(B))≤dim(R(ABC)
(问一下同学这里N和R是什么意思)文章来源:https://www.toymoban.com/news/detail-403407.html
引理: 设
A
∈
C
m
×
n
,
B
∈
C
n
×
p
A\in C^{m\times n} , B\in C^{n\times p}
A∈Cm×n,B∈Cn×p. 则
N
(
A
B
)
=
B
−
1
N
(
A
)
∩
R
(
B
)
。
N(AB)=B−1{N(A)\cap R(B)}。
N(AB)=B−1N(A)∩R(B)。
证明显然文章来源地址https://www.toymoban.com/news/detail-403407.html
到了这里,关于矩阵论知识整理(未完成,同步更新)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!