Elasticsearch From/Size、Scroll、Search After对比
From/Size
可以使用from和size参数对结果进行分页。from参数定义要获取的第一个结果的偏移量。 size 参数允许您配置要返回的最大匹配数。
简单来说,需要查询from + size 的条数时,coordinate node就向该index的其余的shards 发送同样的请求,等汇总到(shards * (from + size))条数时在coordinate node再做一次排序,最终抽取出真正的 from 后的 size 条结果。
注意from + size 不能超过 index.max_result_window 索引设置,默认为 10,000。 有关深入滚动的更有效方法,请参阅 Scroll 或 Search After API。
示例
举个例子,一个索引,有10亿数据,分10个shards,然后,一个搜索请求,from=1,000,000,size=100,这时候,会带来严重的性能问题:
- CPU
- 内存
- IO
- 网络带宽
CPU、内存和IO消耗容易理解,网络带宽问题稍难理解一点。在query阶段,每个shards需要返回1,000,100条数据给coordinating node,而coordinating node需要接收10*1,000,100条数据,即使每条数据只有_doc _id 和_score,这数据量也很大了,而且,这才一个查询请求,那如果再乘以100呢?
在另一方面,我们意识到,这种深度分页的请求并不合理,因为我们是很少人为的看很后面的请求的,在很多的业务场景中,都直接限制分页,比如只能看前100页。
Search Type
在执行分布式搜索时可以执行不同的执行路径。分布式搜索操作需要分散到所有相关的shard,然后收集所有的结果。当使用分散/集中类型执行时,有几种方法可以做到这一点,特别是使用搜索引擎。
执行分布式搜索时的一个问题是从每个shard检索多少结果。例如,如果我们有 10 个shard,则第一个shard可能保存从 0 到 10 的最相关的结果,而其他shard的结果排在后面。因此,在执行请求时,我们需要从所有shard中获取从0到10的结果,对它们进行排序,然后返回结果(如果我们希望确保得到正确的结果)。
与搜索引擎相关的另一个问题是每个shard独立存在的事实。当在特定shard上执行查询时,它不会考虑来自其他shard上term频率及(其他shard上)搜索引擎的信息。如果我们想要支持准确的排名,我们需要首先收集所有shard中的term频率,以计算全局term频率,然后使用这些term频率对每个shard执行查询。
此外,由于需要对结果进行排序,在维护正确的排序行为的同时,获取大型文档集,甚至是滚动它,可能是一个非常昂贵的操作。对于大型结果集滚动,如果返回文档的顺序不重要,则最好按_doc排序。
Elasticsearch非常灵活,可以根据每个搜索请求控制执行的搜索类型。可以通过设置查询字符串中的search_type参数来配置类型。类型是:
Query Then Fetch
参数值: query_then_fetch。
请求分两个阶段处理。 在第一阶段,查询被转发到所有涉及的分片。 每个分片执行搜索并生成对该分片本地的结果的排序列表。 每个分片只向协调节点返回足够的信息,以允许其合并并将分片级结果重新排序为全局排序的最大长度大小的结果集。
在第二阶段期间,协调节点仅从相关分片请求文档内容(以及高亮显示的片段,如果有的话)。
如果您未在请求中指定 search_type,那么这是默认设置。
Dfs, Query Then Fetch
参数值:dfs_query_then_fetch
与 “Query Then Fetch” 相同,除了初始分散阶段,该阶段计算分布式term频率以获得更准确的评分。
Scroll与Search After 都依赖于Search Type
Search After
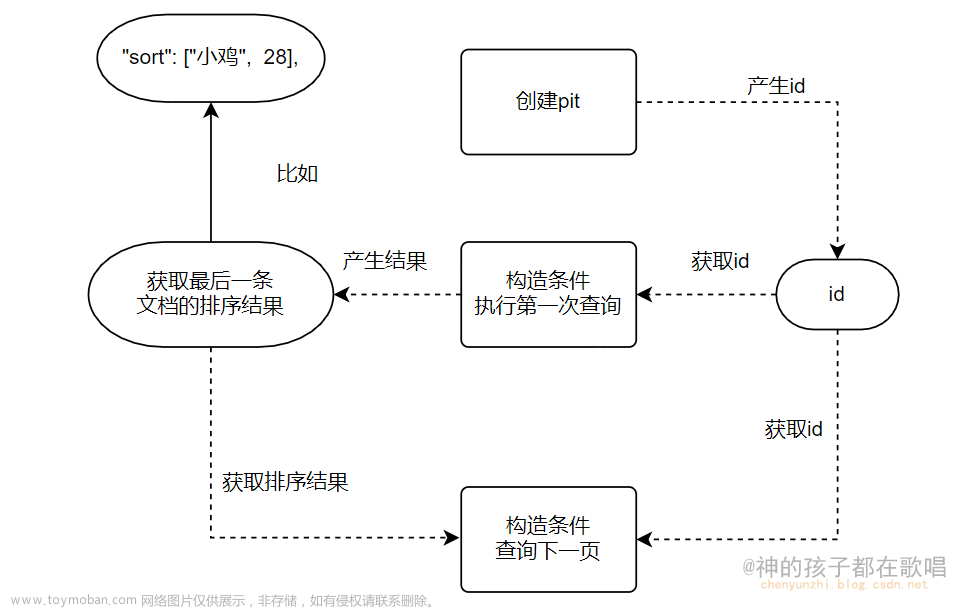
在日志服务架构设计中日志搜索后翻页、日志上下文的功能就是通过search_after实现的。
在官网文档中可以看出Search After有以下特点:
- 实时
- 可以深度分页(使用前一页的结果来帮助检索下一页)
- 不支持跳页
注意:每个文档具有一个唯一值的字段应用作排序规范的仲裁。 否则,具有相同排序值的文档的排序顺序将是未定义的。
建议的方法是使用字段 _uid(elasticsearch 6.x _uid 废弃 替换为_id),它确保每个文档包含一个唯一值。
The _id field is restricted from use in aggregations, sorting, and scripting. In case sorting or aggregating on the _id field is required, it is advised to duplicate the content of the _id field into another field that has doc_values enabled.
_id 字段被限制在聚合、排序和脚本中使用。 如果需要对 _id 字段进行排序或聚合,建议将 _id 字段的内容复制到另一个启用了 doc_values 的字段中。
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-id-field.html
Scroll
虽然搜索请求返回单个 “page” 的结果,但是滚动 API 可以用于从单个搜索请求中检索大量结果(甚至是所有结果),与在传统数据库上使用游标的方式大致相同。
滚动不是用于实时用户请求,而是用于处理大量数据,例如, 以便将一个索引的内容重新索引到具有不同配置的新索引中。
从滚动请求返回的结果反映了进行初始搜索请求时索引的状态,如时间快照。 对文档(索引,更新或删除)的后续更改只会影响以后的搜索请求。
可以把 scroll 分为初始化和遍历两步,初始化时将所有符合搜索条件的搜索结果缓存起来,可以想象成快照,在遍历时,从这个快照里取数据,也就是说,在初始化后对索引插入、删除、更新数据都不会影响遍历结果。
滚动请求具有优化,使排序顺序为_doc时更快。 如果你想迭代所有文档,无论顺序如何,这是最有效的选择:
GET /_search?scroll=1m
{
"sort": [
"_doc"
]
}
Keeping the search context alive
滚动参数(传递到搜索请求和每个滚动请求)告诉Elasticsearch应该保持搜索上下文活动的时间。其值(例如,1m,请参阅 “Time unit” 一节)不需要足够长以处理所有数据 - 它只需要足够长的时间来处理前一批结果。每个滚动请求(具有滚动参数)设置新的到期时间。
通常,后台合并过程通过将较小的段合并在一起以创建新的较大段来优化索引,此时较小的段被删除。此过程在滚动期间继续,但是打开的搜索上下文防止旧段在它们仍在使用时被删除。这就是Elasticsearch如何能够返回初始搜索请求的结果,而不考虑对文档的后续更改。
小结
如果要做非常多页的查询时,search after是一个常量查询延迟和开销,并无什么副作用,可是,就像要查询结果全量导出那样,要在短时间内不断重复同一查询成百甚至上千次,效率就显得非常低了。
2023-03-18现在不用纠结了 😭 😭 😭 😭 😭 😭

https://www.elastic.co/guide/en/elasticsearch/reference/current/paginate-search-results.html#scroll-search-results
search after是lucene原生支持的:
https://lucene.apache.org/core/8_0_0/core/org/apache/lucene/search/IndexSearcher.html
https://lucene.apache.org/core/8_0_0/core/org/apache/lucene/search/IndexSearcher.html#searchAfter-org.apache.lucene.search.ScoreDoc-org.apache.lucene.search.Query-int-
猜测一下search after的实现原理,应该是通过doc_values来实现的
doc_values已经排好序了,所以通过每次search_after指定的值,往后查找即可
 文章来源:https://www.toymoban.com/news/detail-404159.html
文章来源:https://www.toymoban.com/news/detail-404159.html
本文内容来自官方文档,主要是做了翻译及汇总。文章来源地址https://www.toymoban.com/news/detail-404159.html
到了这里,关于Elasticsearch From/Size、Scroll、Search After对比的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![elasticsearch结果窗口限制10000[from+size小于或等于10000]](https://imgs.yssmx.com/Uploads/2024/02/590255-1.png)







