Flink-CDC简介
官网地址 https://ververica.github.io/flink-cdc-connectors/master/
CDC 是 Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的 变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
CDC主要分为基于查询和基于Binlog两种方式
| 基于查询的CDC | 基于Binlog的CDC | |
|---|---|---|
| 开源产品 | Sqoop、Kafka JDBC Source | Canal、MAxwell、Debezium |
| 执行模式 | Batch批处理 | Streaming流处理 |
| 是否可以捕获所有数据变化 | 否 | 是 |
| 延迟性 | 高延迟 | 低延迟 |
| 是否增加数据库压力 | 是 | 否 |
MySQL开启binlog日志文件
修改 /etc/my.cnf
log-bin=mysql-bin
binlog_format=row
binlog-do-db=bigdata-realtime

DataStream方式应用
引入依赖
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>com.alibaba.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>1.2.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
</dependencies>
打包方式:全量包
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
监控数据库变化
public static void main(String[] args) throws Exception {
// 1. 获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// Flink-cdc将读取binlog的位置信息以状态的方式保存在CK,如果想要做到断电续传,需要从CheckPoint或者SavePoint启动程序
// 开启CK,每隔5秒钟做一次CK,CK超时时间10s,最大并发数2,CK之间间隔1,访问HDFS的用户名root,重启策略延时2秒重启3次
env.enableCheckpointing(5000L);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 2000L));
env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/gmall-210325/ck"));
System.setProperty("HADOOP_USER_NAME", "root");
env.getCheckpointConfig().setCheckpointTimeout(10000L);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1L);
// 2. 通过FlinkCDC构建SourceFunction并读取数据
DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("root")
.databaseList("gmall-210325-flink")
.tableList("gmall-210325-flink.base_trademark") // 如果不添加该参数,则消费指定数据库中所有表的数据,如果指定,指定方式为db.table,必须带上库名
.deserializer(new StringDebeziumDeserializationSchema())
.startupOptions(StartupOptions.initial())
.build();
DataStreamSource<String> streamSource = env.addSource(sourceFunction);
// 3. 打印数据
streamSource.print();
// 4. 启动任务
env.execute("FlinkCDC");
}
启动任务
bin/flink run -m hadoop102:8081 -c com.atguigu.FlinkCDC ./gmall-flink-cdc.jar

保存savepoint
# bin/flink savepoint 任务id hdfs地址
bin/flink savepoint eaebb93839f0c66014b34a9bf21b4cfa hdfs://hadoop102:8020/gmall-210325/sv
从savepoint处启动
bin/flink run -m hadoop102:8081 -s hdfs://hadoop102:8020/gmall-210325/sv/savepoint-eaebb9-0759b72fba40 -c com.atguigu.FlinkCDC ./gmall-flink-cdc.jar

FlinkSQL方式应用
引入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.12.0</version>
</dependency>
监控数据库变化
public static void main(String[] args) throws Exception {
// 获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// DDL方式建表
tableEnv.executeSql("CREATE TABLE mysql_binlog ( " +
" id STRING NOT NULL, " +
" tm_name STRING, " +
" logo_url STRING " +
") WITH ( " +
" 'connector' = 'mysql-cdc', " +
" 'hostname' = 'hadoop102', " +
" 'port' = '3306', " +
" 'username' = 'root', " +
" 'password' = 'root', " +
" 'database-name' = 'gmall-210325-flink', " +
" 'table-name' = 'base_trademark' " +
")");
// 查询数据
Table table = tableEnv.sqlQuery("select * from mysql_binlog");
// 将动态表转换为流
DataStream<Tuple2<Boolean, Row>> retractStream = tableEnv.toRetractStream(table, Row.class);
retractStream.print();
// 启动任务
env.execute("FlinkCDCWithSQL");
}
自定义反序列化器
public class CustomerDeserialization implements DebeziumDeserializationSchema<String> {
// 封装的数据格式 json
/*
{
"database":"",
"tableName":"",
"type":"",
"before":"json",
"after":"json",
}
*/
@Override
public void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception {
// 创建JSON对线用于存储最终数据
JSONObject result = new JSONObject();
// 获取库名和表名
String topic = sourceRecord.topic();
String[] fields = topic.split("\\.");
String database = fields[1];
String tableName = fields[2];
Struct value = (Struct) sourceRecord.value();
// 获取before数据
Struct before = value.getStruct("before");
JSONObject beforeJson = new JSONObject();
if (before != null) {
Schema beforeSchema = before.schema();
List<Field> beforeFields = beforeSchema.fields();
for (int i = 0; i < beforeFields.size(); i++) {
Field field = beforeFields.get(i);
Object beforeValue = before.get(field);
beforeJson.put(field.name(), beforeValue);
}
}
// 获取after数据
Struct after = value.getStruct("after");
JSONObject afterJson = new JSONObject();
if (after != null) {
Schema afterSchema = after.schema();
List<Field> afterFields = afterSchema.fields();
for (Field field : afterFields) {
Object afterValue = after.get(field);
afterJson.put(field.name(), afterValue);
}
}
// 获取操作类型
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
String type = operation.toString().toLowerCase();
if("create".equals(type)){
type="insert";
}
// 将字段写入JSON对线
result.put("database", database);
result.put("tableName", tableName);
result.put("before", beforeJson);
result.put("after", afterJson);
result.put("type", type);
// 输出数据
collector.collect(result.toJSONString());
}
@Override
public TypeInformation<String> getProducedType() {
return BasicTypeInfo.STRING_TYPE_INFO;
}
}
使用自定义序列化器
public static void main(String[] args) throws Exception {
// 1. 获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// Flink-cdc将读取binlog的位置信息以状态的方式保存在CK,如果想要做到断电续传,需要从CheckPoint或者SavePoint启动程序
// 开启CK,每隔5秒钟做一次CK,CK超时时间10s,最大并发数2,CK之间间隔1,访问HDFS的用户名root,重启策略延时2秒重启3次
env.enableCheckpointing(5000L);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 2000L));
env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/gmall-210325/ck"));
System.setProperty("HADOOP_USER_NAME", "root");
env.getCheckpointConfig().setCheckpointTimeout(10000L);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1L);
// 2. 通过FlinkCDC构建SourceFunction并读取数据
DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("root")
.databaseList("gmall-210325-flink")
.tableList("gmall-210325-flink.base_trademark") // 如果不添加该参数,则消费指定数据库中所有表的数据,如果指定,指定方式为db.table,必须带上库名
.deserializer(new CustomerDeserialization())
.startupOptions(StartupOptions.initial())
.build();
DataStreamSource<String> streamSource = env.addSource(sourceFunction);
// 3. 打印数据
streamSource.print();
// 4. 启动任务
env.execute("FjavalinkCDCWithCustomerDeserialization");
}
Flink-SQLClient方式应用
同步Kafka
所需依赖
flink-sql-connector-kafka_2.11-1.13.6.jar
客户端设置
# 设置CheckPoint时间
set execution.checkpointing.interval = 3s;
# 设置方便查询
set sql-client.execution.result-mode=tableau;
创建FlinkCDC表
CREATE TABLE cdc_source (
id bigint,
tm_name STRING,
logo_url STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'bigdata',
'port' = '3306',
'username' = 'root',
'password' = 'root',
'database-name' = 'mall',
'table-name' = 'base_trademark'
);
创建Kafka表
对于upsert-kafka,新增则是配置的json格式数据,删除则是null
CREATE TABLE kafka_sink (
`id` BIGINT,
`name` STRING,
`pwd` STRING,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'test1',
'properties.bootstrap.servers' = 'bigdata:9092',
'key.format' = 'json',
'value.format' = 'json'
);
对于kafka,则是debezium格式
CREATE TABLE kafka_sink (
`id` BIGINT,
`tm_name` STRING,
`logo_url` STRING
) WITH (
'connector' = 'kafka',
'topic' = 'test1',
'properties.bootstrap.servers' = '192.168.80.100:9092',
'properties.group.id' = 'test1',
'scan.startup.mode' = 'earliest-offset',
'format' = 'debezium-json',
'debezium-json.ignore-parse-errors'='true'
);
插入数据
insert into kafka_sink select * from cdc_source;
同步MySQL
所需依赖
flink-sql-connector-mysql-cdc-2.2.1.jar
客户端设置
# 设置CheckPoint时间
set execution.checkpointing.interval = 3s;
# 设置方便查询
set sql-client.execution.result-mode=tableau;
CDC表
CREATE TABLE db1 (
id INT,
name STRING,
pwd STRING,
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'bigdata',
'port' = '3306',
'username' = 'root',
'password' = 'root',
'database-name' = 'db1',
'table-name' = 'user');
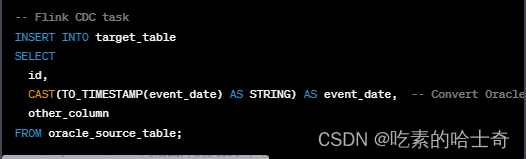
同步Oracle
官网参考地址
cdc-oracle依赖官网下载地址:https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-oracle-cdc/
使用docker安装oracle:https://blog.csdn.net/qq_36039236/article/details/124224500?spm=1001.2014.3001.5502
cdc-oracle官网地址:https://ververica.github.io/flink-cdc-connectors/master/content/connectors/oracle-cdc.html
所需依赖
flink-sql-connector-oracle-cdc-2.2.1.jar
Oracle日志支持准备
# 修改STUDENT_INFO表让其支持增量日志,这句先在Oracle里创建user表再执行
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
ALTER TABLE CZS.STUDENT_INFO ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
客户端设置
# 设置CheckPoint时间
set execution.checkpointing.interval = 3s;
# 设置方便查询
set sql-client.execution.result-mode=tableau;
创建Oracle表
create table student_info
(
sid number(10) constraint pk_sid primary key,
sname varchar2(10),
sex varchar2(2)
);
CDC表
CREATE TABLE test (
SID INT NOT NULL,
SNAME STRING,
SEX STRING,
PRIMARY KEY(SID) NOT ENFORCED
) WITH (
'connector' = 'oracle-cdc',
'hostname' = 'bigdata',
'port' = '1521',
'username' = 'czs',
'password' = 'czs',
'database-name' = 'helowin',
'schema-name' = 'czs',
'table-name' = 'student_info',
# 或略表名大小写
'debezium.database.tablename.case.insensitive'='false'
);
同步PG
官网参考地址
postgres-cdc官网地址:https://ververica.github.io/flink-cdc-connectors/master/content/connectors/postgres-cdc.html
所需依赖
flink-sql-connector-postgres-cdc-2.2.1.jar
环境准备
dockers启动pg
# 拉取镜像
docker pull postgres
# 创建容器
docker run --name postgres -d -p 5432:5432 -v /mydata/postgresql/data:/var/lib/postgresql/data/ -e POSTGRES_DB=postgres -e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=postgres postgres
# 进入pg
docker exec -it postgres psql -U postgres -d postgres
# 进入psql
psql -U postgres -d postgres
所需权限
-- pg新建用户
CREATE USER mtcs WITH PASSWORD 'mtcs';
-- 给用户复制流权限
ALTER USER mtcs REPLICATION;
-- 给用户登录数据库权限
grant CONNECT ON DATABASE postgres to mtcs;
-- 把当前库public下所有表查询权限赋给用户
GRANT SELECT ON ALL TABLES IN SCHEMA public TO mtcs;
-- 设置发布为true
update pg_publication set puballtables=true where pubname is not null;
-- 把所有表进行发布
CREATE PUBLICATION dbz_publication FOR ALL TABLES;
-- 查询哪些表已经发布
select * from pg_publication_tables;
创建postgres-cdc
CREATE TABLE postgres (
id INT,
name STRING,
pwd STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'postgres-cdc',
'hostname' = 'bigdata',
'port' = '5432',
'username' = 'czs',
'password' = 'czs',
'database-name' = 'hive',
'schema-name' = 'public',
'table-name' = 'user',
'debezium.plugin.name' = 'pgoutput'
);
同步MongoDB
mongodb快速入门:https://www.runoob.com/mongodb/
cdc官网说明地址:https://ververica.github.io/flink-cdc-connectors/master/content/connectors/mongodb-cdc.html
基于docker创建mongodb副本集:https://blog.csdn.net/weixin_44975592/article/details/125112407
cdc-mongo依赖官网下载地址:https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mongodb-cdc/
所需依赖
flink-sql-connector-mongodb-cdc-2.2.1.jar
环境准备
docker启动mongodb
# docker启动mongo
# -p 主机端口号:docker端口号
# –n me mongodb名称
# -v 主机路径:docker路径
# -replSet rs(集群名称,1主2从便是一个集群)
docker run -p 27017:27017 --name mongo -v /root/data/db:/data/db -d mongo --replSet rs
# 进入mongo
docker exec -it mongo mongo
# 添加从节点并初始化,这是初始化,直接初始化可以直接将当前节点变为主节点,然后可以在通过rs.add()添加,但是要注意,添加成功后,查看时会看到展示的是一个数组,数组中是一个节点一个集合,集合中有元素,元素有_id,这个_id的值必须是顺序下来,且主节点应该是0,是不是必须并不清楚。
# 看到"ok":1为成功,0为失败,如果你为0,看看上面有无操作出错
rs.initiate()
# 十秒左右,按回车,可看到变为主节点
rs: primary>
# 查看状态
rs.status()
# 创建admin用户 需要use admin在admin数据库下创建
db.createUser({ user:'admin',pwd:'admin',roles:[ { role:'userAdminAnyDatabase', db: 'admin'},"readWriteAnyDatabase"]});
# 使用admin认证
db.auth('admin', 'admin')
# czs用户是官网说明的cdc同步权限,需要use admin在admin数据库下创建
db.createUser({
user: "czs",
pwd: "czs",
roles: [
{ role: "read", db: "admin" },
{ role: "readAnyDatabase", db: "admin" }
]
});
创建CDC-MongoDB表
# 创建数据库
use runoob
# mongo中插入数据
db.runoob.insert({"name":"czs"})
# 查看所有数据库
show dbs
# mongo中查询数据
db.runoob.find()
# 创建mongo-flinkcdc表
CREATE TABLE runoob (
_id STRING,
name STRING,
PRIMARY KEY(_id) NOT ENFORCED
) WITH (
'connector' = 'mongodb-cdc',
'hosts' = 'bigdata:27017',
'username' = 'czs',
'password' = 'czs',
'database' = 'runoob'
);
# 验证cdc同步
select * from runoob;
操作Hive
所需依赖
flink-sql-connector-hive-3.1.2_2.11-1.13.6.jar
flink-shaded-hadoop3-uber-blink-3.3.0.jar、flink-shaded-hadoop-2-uber-2.8.3-10.0.jar(只需要一个即可)
使用Orc格式的Hive表
- orc表:https://blog.csdn.net/qq_35260875/article/details/109196553
- 官网hive依赖地址:https://mvnrepository.com/artifact/org.apache.flink/flink-sql-connector-hive-3.1.2_2.11/1.13.6
- 官网flink hive依赖说明:https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/connectors/table/hive/overview/
set sql-client.execution.result-mode=tableau;
# 创建目录
CREATE CATALOG myhive WITH (
'type' = 'hive',
'default-database' = 'default',
'hive-conf-dir' = '/opt/module/hive-3.1.2/conf'
);
# 创建orc格式的hive表
create table test(
a int,
b int,
c int,
d int
)
row format delimited fields terminated by ','
stored as orc tblproperties ("orc.compress"="NONE");
# 写入数据
insert into test values(1,2,3,4);
写入Hive的分区数据
set sql-client.execution.result-mode=tableau;
SET table.sql-dialect=hive;
# 创建目录
CREATE CATALOG myhive WITH (
'type' = 'hive',
'default-database' = 'default',
'hive-conf-dir' = '/opt/module/hive-3.1.2/conf'
);
CREATE TABLE hive_table (
user_id STRING,
order_amount DOUBLE
) PARTITIONED BY (dt STRING, hr STRING) STORED AS parquet TBLPROPERTIES (
'partition.time-extractor.timestamp-pattern'='$dt $hr:00:00',
'sink.partition-commit.trigger'='partition-time',
'sink.partition-commit.delay'='1 h',
'sink.partition-commit.policy.kind'='metastore,success-file'
);
SET table.sql-dialect=default;
insert into hive_table values('czs1',1.0,'part1','hr1');
同步Hive维表
CREATE CATALOG myhive WITH ( 'type' = 'hive', 'default-database' = 'default', 'hive-conf-dir' = '/opt/module/hive-3.1.2/conf' );
SET table.sql-dialect=hive;
CREATE EXTERNAL TABLE hive_table_test (
obuid STRING,
ck_time STRING
) PARTITIONED BY (dt STRING)
STORED AS ORC
LOCATION 'hdfs://bigdata:8020/datas/hive_table_test'
TBLPROPERTIES (
'partition.time-extractor.timestamp-pattern'='$dt $hr:00:00',
'sink.partition-commit.trigger'='partition-time',
'sink.partition-commit.delay'='1 h',
'sink.partition-commit.policy.kind'='metastore,success-file'
);
# 查看表信息
describe formatted hive_table_test;
describe hive_table_test;
show partitions hive_table_test;
SET table.sql-dialect=default;
create table kafka_bus_yiqi_rt_ck
(
obuid string ,
ck_time string ,
proc_time as proctime()
)
WITH(
'connector.type' = 'kafka',
'connector.topic' = 'kafka_bus',
'connector.properties.zookeeper.connect' = 'localhost:2181',
'connector.properties.bootstrap.servers' = 'localhost:9092',
'connector.properties.group.id' = 'testGroup',
'connector.version'='universal',
'format.type' = 'json',
'connector.startup-mode'='earliest-offset'
);
炸裂函数使用
json格式如下
{
"id":1238123899121,
"name":"asdlkjasjkdla998y1122",
"date":"1990-10-14",
"obj":{
"time1":"12:12:43Z",
"str":"sfasfafs",
"lg":2324342345
},
"arr":[
{
"f1":"f1str11",
"f2":134
},
{
"f1":"f1str22",
"f2":555
}
],
"time":"12:12:43Z",
"timestamp":"1990-10-14T12:12:43Z",
"map":{
"flink":123
},
"mapinmap":{
"inner_map":{
"key":234
}
}
}
创建flink表
CREATE TABLE json_source (
id BIGINT,
name STRING,
`date` DATE,
obj ROW<time1 TIME,str STRING,lg BIGINT>,
arr ARRAY<ROW<f1 STRING,f2 INT>>,
`time` TIME,
`timestamp` TIMESTAMP(3),
`map` MAP<STRING,BIGINT>,
mapinmap MAP<STRING,MAP<STRING,INT>>,
proctime as PROCTIME()
) WITH (
'connector.type' = 'kafka',
'connector.topic' = 'test',
'connector.properties.zookeeper.connect' = 'localhost:2181',
'connector.properties.bootstrap.servers' = 'localhost:9092',
'connector.properties.group.id' = 'testGroup',
'connector.version'='universal',
'format.type' = 'json',
'connector.startup-mode'='latest-offset'
);
插入验证文章来源:https://www.toymoban.com/news/detail-404194.html
insert into json_source select 111 as id,'name' as name,Row(CURRENT_TIME,'ss',123) as obj,Array[Row('f',1),Row('s',2)] as arr,Map['k1','v1','k2','v2'] as `map`,Map['inner_map',Map['k','v']] as mapinmap;
查询验证文章来源地址https://www.toymoban.com/news/detail-404194.html
select id,name,f1,f2 from json_source, UNNEST(arr) AS t (f1,f2);
到了这里,关于大数据技术-FlinkCDC学习笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!