主要方案:
UUID(Universally Unique Identifier)
即通用唯一识别码,是一种由网络软件使用的标识符,它是由IP地址、当前时间戳、随机数、节点等多个部分组成,具有唯一性。但是,UUID方案的缺点是,生成的id较长,不便于存储和使用。
Snowflake算法
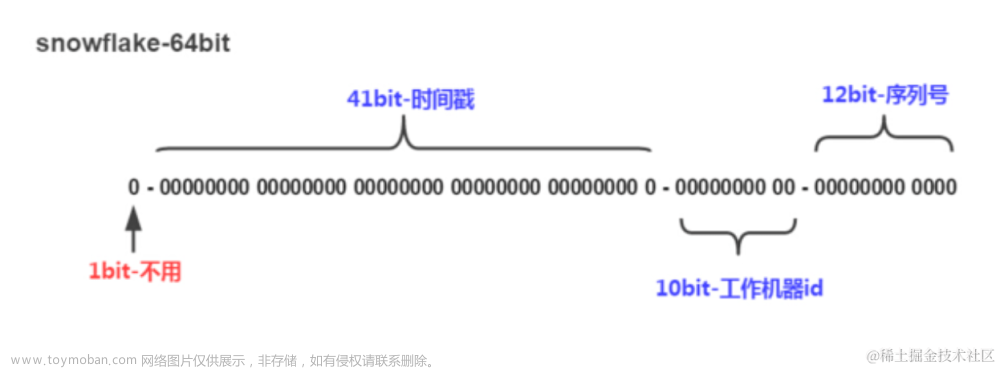
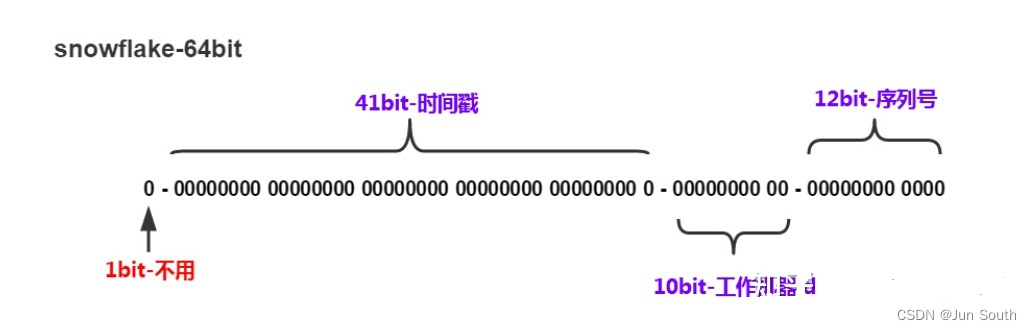
它是Twitter公司开源的一个分布式唯一ID生成器,采用64位的二进制格式,其中高位是符号位,其次是时间戳,然后是数据中心ID和机器ID,最后是序列号。主要缺点是序列号存在单点故障问题,同时如果Clock回拨,可能会产生重复ID。
Leaf算法
它是美团点评公司开源的一个唯一ID生成服务,采用64-bit的ID存储方式,支持1s内最高生成2^63-1个唯一ID。该方案集成简单,ID生成速度较快,且可支持多语言。
总结
对于一般的业务系统,建议采用Leaf算法或其他中间件提供的分布式ID生成服务,原因如下:
ID生成速度快:分布式ID生成服务将ID生成逻辑放到了中间件中,可以直接从中间件中获取ID,不需要再进行ID的生成,避免了过多的ID生成计算和存储。
ID唯一性高:现有的分布式ID生成方案的ID生成算法都具有很高的唯一性,不会出现ID冲突的问题。
集成简单:将分布式ID生成中间件集成到业务系统中比自己编写ID生成逻辑更方便,还可以通过配置中间件进行ID生成器的相关配置和调整,提高系统的灵活性和可维护性。
Springboot集成leaf算法
引入Leaf算法,主要步骤:文章来源:https://www.toymoban.com/news/detail-404236.html
- 首先需要下载并依赖Leaf算法的客户端和服务端,可以选择maven依赖或者直接从github上下载jar包。
- 在业务系统的配置文件中,配置与Leaf算法相关的参数信息,包括服务端的地址、端口等信息。
- 在业务系统中调用Leaf算法的客户端SDK,进行ID的生成和获取,根据自己的业务需要自行封装API接口。进行调试测试,验证ID是否符合要求,并进行优化和调整。
需要注意的是,Leaf算法虽然解决了分布式系统中ID生成的问题,但是其也存在不足,例如无法完全保证ID连续递增、无法控制生成的ID长度、集群运维等问题,需要根据具体的业务需求进行选择。文章来源地址https://www.toymoban.com/news/detail-404236.html
1. 引入依赖。pom.xml中需要引入Leaf依赖。
<dependency>
<groupId>com.sankuai.inf.leaf</groupId>
<artifactId>leaf-core</artifactId>
<version>1.2.0</version>
</dependency>
2. 配置application.yml。配置Leaf Client连接的服务端信息。
leaf:
client:
# leaf所在server的IP和端口
server-addr: localhost:8080
port: 8080
3. 创建ID生成器接口。在项目中创建一个ID生成器接口,定义生成ID方法。
public interface IdGenerator {
Long nextId();
}
4. 实现ID生成器接口。创建一个Leaf算法实现的ID生成器类,实现上面的接口。
@Service
public class LeafIdGenerator implements IdGenerator {
private SegmentIdGenImpl leafIdGenerator;
public LeafIdGenerator() throws Exception {
// 构造Leaf ID生成器
Properties properties = new Properties();
properties.setProperty("leaf.name", "your-leaf-name");
properties.setProperty("leaf.segment.enable", "true");
properties.setProperty("leaf.segment.oneTimeCacheSize", "10000");
properties.setProperty("leaf.jdbc.url", "your-database-url");
properties.setProperty("leaf.jdbc.username", "your-database-username");
properties.setProperty("leaf.jdbc.password", "your-database-password");
properties.setProperty("leaf.jdbc.driver", "your-database-driver-class-name");
SegmentIDGenImpl segmentIDGen = new SegmentIDGenImpl();
segmentIDGen.init(properties);
this.leafIdGenerator = segmentIDGen;
}
@Override
public Long nextId() {
// 生成Leaf ID
return leafIdGenerator.getNextSegmentId("your-leaf-key").getId();
}
}
5. 在API Controller中使用ID生成器。例如,在UserController中生成用户ID。
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private IdGenerator idGenerator;
@PostMapping("")
public Result createUser(@RequestBody User user) {
Long id = idGenerator.nextId();
user.setId(id);
// 保存到数据库,...
return Result.success(user);
}
}
到了这里,关于分布式id生成方案及springboot进行集成的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!