大数据-安装 Hadoop3.1.3 详细教程-伪分布式配置(Centos7)
**相关资源:**https://musetransfer.com/s/q43oznf6f(有效期至2023年3月16日)|【Muse】你有一份文件待查收,请点击链接获取文件
1.检查是否安装ssh (CentOS 7 即使是最小化安装也已附带openssh 可跳过本步骤)
rpm -qa | grep ssh
若已安装进行下一步骤 若未安装 请自行百度 本教程不做过多讲解
2.配置ssh,实现无密码登录
1.开启sshd服务
systemctl start sshd.service
2.进入 ~/.ssh 文件夹
cd ~/.ssh
若不存在该文件夹 可使用以下命令 使用root账户登录后生成
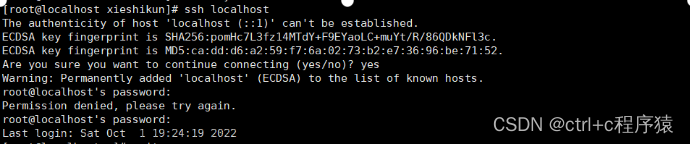
ssh root@localhost
然后输入yes 并输入本机root密码
3.进入 .ssh目录后 执行
ssh-keygen -t rsa
一路按回车就可以

4.做ssh免密认证 执行以下命令即可
cat id_rsa.pub >> authorized_keys
5.修改文件权限
chmod 644 authorized_keys
6.检测是否可以免密登录
ssh root@localhost
无需输入密码登录 即为成功

3上传jdk,并配置环境变量
将文件上传至CentOS7 的 /usr/local/java 文件夹中



进入文件夹并进行解压缩
tar -zxvf jdk-8u212-linux-x64.tar.gz

将压缩包删除

新建/etc/profile.d/my_env.sh 文件
vim /etc/profile.d/my_env.sh
添加如下内容:
#JAVA_HOME
export JAVA_HOME=/usr/local/java/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
保存后退出 :wq!
source 一下/etc/profile 文件,让新的环境变量 PATH 生效
source /etc/profile
测试 JDK 是否安装成功
java -version

4上传Hadoop,并配置环境变量
将文件上传至CentOS7 的 /usr/local/hadoop 文件夹中



进入文件夹并进行解压缩
tar -zxvf hadoop-3.1.3.tar.gz
将压缩包删除

将 Hadoop 添加到环境变量
vim /etc/profile.d/my_env.sh

保存后退出 :wq!
source 一下/etc/profile 文件,让新的环境变量 PATH 生效
source /etc/profile
测试 hadoop 是否安装成功
hadoop version

5 hadoop准备工作
创建hadoop存放数据的目录
cd 到hadoop目录下。执行以下命令
mkdir temp

创建namenode 存放 name table 的目录
cd 到 temp目录下创建dfs目录,再dfs目录下创建name目录
cd temp/
mkdir dfs
ls
cd dfs/
mkdir name
ls

创建 datanode 存放 数据 block 的目录
dfs目录下创建data目录
mkdir data
ls

修改/usr/local/hadoop/hadoop-3.1.3/etc/hadoop文件夹下的core-site.xml配置文件

默认情况下,Hadoop将数据保存在/tmp下,当重启系统时,/tmp中的内容将被自动清空,所以我们需要制定自己的一个Hadoop的目录,用来存放数据。另外需要配置Hadoop所使用的默认文件系统,以及Namenode进程所在的主机
vim core-site.xml
打开 core-site.xml 文件后,将其中的
<configuration>
</configuration>
修改为以下的配置:
<configuration>
<property>
<!-- 指定hadoop运行时产生文件的存储路径-->
<name>hadoop.tmp.dir</name>
<value>/opt/module/temp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<!--hdfs namenode的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://192.168.119.129:9000</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>

修改/usr/local/hadoop/hadoop-3.1.3/etc/hadoop文件夹下的hdfs-site.xml配置文件
该文件指定与HDFS相关的配置信息。需要修改HDFS默认的块的副本属性,因为HDFS默认情况下每个数据块保存3个副本,而在伪分布式模式下运行时,由于只有一个数据节点,所以需要将副本个数改为1,否则Hadoop程序会报错
执行以下命令修改 hdfs-site.xml 文件:
vim hdfs-site.xml # 编辑 hdfs-site.xml 文件
打开 hdfs-site.xml 文件后,将其中的
<configuration>
</configuration>
修改为以下的配置:
<configuration>
<property>
<!--指定HDFS储存数据的副本数目,默认情况下为3份-->
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<!--name node 存放 name table 的目录-->
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<!--data node 存放数据 block 的目录-->
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
<property>
<!--设置监控页面的端口及地址-->
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
</configuration>

修改/usr/local/hadoop/hadoop-3.1.3/etc/hadoop文件夹下的mapred-site.xml配置文件
vim mapred-site.xml
打开 mapred-site.xml文件后,将其中的
<configuration>
</configuration>
修改为以下的配置:
<configuration>
<property>
<!-- 指定mapreduce 编程模型运行在yarn上 -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>

修改/usr/local/hadoop/hadoop-3.1.1/etc/hadoop文件夹下的yarn-site.xml配置文件
vim yarn-site.xml
打开 mapred-site.xml文件后,将其中的
<configuration>
</configuration>
修改为以下的配置:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<!-- 指定mapreduce 编程模型运行在yarn上 -->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>

分别编辑开始和关闭脚本
分别/usr/local/hadoop/hadoop-3.1.3/sbin 下的 start-dfs.sh 和 stop-dfs.sh , start-yarn.sh 和 stop-yarn.sh

vim start-dfs.sh
在最上方 #/usr/bin/env bash 下空白处添加以下内容
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root

vim stop-dfs.sh
在最上方 #/usr/bin/env bash 下空白处添加以下内容
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root

vim start-yarn.sh
在最上方 #/usr/bin/env bash 下空白处添加以下内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root

vim stop-yarn.sh
在最上方 #/usr/bin/env bash 下空白处添加以下内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root

格式化namenode,只格式化一次即可
cd 到/usr/local/hadoop/hadoop-3.1.3/etc/hadoop 目录下

执行
hadoop namenode -format

启动hadoop
start-all.sh

查看进程,检查是否启动
jps

至此已经成功安装完成Hadoop (记得在防火墙里面放行以下的端口)
HDFS Web界面:自己的IP地址:50070

ResourceManager Web界面:自己的IP地址:8088文章来源:https://www.toymoban.com/news/detail-404629.html
 文章来源地址https://www.toymoban.com/news/detail-404629.html
文章来源地址https://www.toymoban.com/news/detail-404629.html
到了这里,关于大数据-安装 Hadoop3.1.3 详细教程-伪分布式配置(Centos7)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!