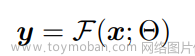- 一 随机森林算法的基本原理
-
二 随机森林算法的优点
- 1. 随机森林算法具有很高的准确性和鲁棒性
- 2. 随机森林算法可以有效地避免过拟合问题
- 3. 随机森林算法可以处理高维度数据
- 4. 随机森林算法可以评估特征的重要性
-
三 随机森林算法的缺点
- 1. 随机森林算法对于少量数据集表现不佳
- 2. 随机森林算法的结果不够直观
- 3. 随机森林算法的训练时间较长
- 4. 随机森林算法对于分类不平衡的数据集表现不佳
-
随机森林算法应用
- 数据集
- 数据预处理
- 随机森林分类模型
- 模型评估
随机森林(Random Forest)是一种集成学习(Ensemble Learning)算法,由于其优秀的表现在数据挖掘、机器学习等领域得到广泛应用。随机森林通过同时使用多个决策树对数据集进行训练,并通过投票机制或平均化方式来得出最终的预测结果。本文将对随机森林算法的基本原理、优点和缺点以及实现过程进行详细介绍。
一 随机森林算法的基本原理
随机森林算法是基于决策树算法的一种集成学习算法。决策树是一种树形结构,其中每个内部节点表示一个特征或属性,每个分支代表这个特征或属性的一个值,每个叶子节点表示一个分类或回归结果。通过决策树,我们可以把数据集分成多个子集,每个子集包含了具有相同特征或属性的数据。然后我们可以对每个子集进行分析,并将其分类或回归。
随机森林有两个重要的随机性来源:一是数据的随机性,二是特征的随机性。对于数据的随机性,随机森林使用自助采样法(bootstrap sampling)从原始数据集中随机选择 n 个样本(n 通常小于原始数据集的样本数),组成一个新的训练数据子集。这个新的数据子集被用来训练一个新的决策树。对于特征的随机性,随机森林在每个决策树的节点上,随机选择 m 个特征(m 远小于总特征数),并从这 m 个特征中选择最佳的特征用于分裂。
随机森林算法的训练过程可以概括为以下几个步骤:
- 从原始数据集中随机选择 n 个样本,组成一个新的训练数据子集。
- 随机选择 m 个特征,从这 m 个特征中选择最佳的特征用于分裂。
- 根据选定的特征进行分裂,得到一个子节点。
- 重复 1-3 步,直到决策树生长完毕。
- 重复 1-4 步,生成多个决策树。
- 预测时,将测试数据集在每个决策树上运行,得到每个决策树的预测结果,然后取所有决策树的预测结果的平均值(对于回归问题)或多数表决(对于分类问题)作为最终的预测结果。
二 随机森林算法的优点
随机森林算法具有以下优点:
1. 随机森林算法具有很高的准确性和鲁棒性
随机森林算法对于噪声和异常值等不利因素具有很高的鲁棒性。这是因为随机森林算法同时使用多个决策树对数据进行训练,可以通过平均化或投票机制得出一个更加稳定和可靠的预测结果。此外,随机森林算法能够自动处理数据集中的缺失值,这进一步增强了算法的鲁棒性。
2. 随机森林算法可以有效地避免过拟合问题
过拟合是机器学习中的一个常见问题,它会导致模型在训练集上表现很好,但在测试集上表现很差。随机森林算法通过使用随机子集和随机特征的方式,可以有效地避免过拟合问题。因为每个决策树都是在不同的随机子集上训练的,这使得每个决策树之间的差异性更大,从而减少了模型的方差。
3. 随机森林算法可以处理高维度数据
随机森林算法可以处理高维度数据,因为它只选择一部分随机特征进行训练。这使得随机森林算法不需要对所有特征进行计算,从而可以提高算法的效率。
4. 随机森林算法可以评估特征的重要性
随机森林算法可以通过计算每个特征在所有决策树中的重要性来评估特征的重要性。这个重要性指标可以帮助我们选择最相关的特征,从而提高算法的效率和准确性。
三 随机森林算法的缺点
随机森林算法的缺点主要包括以下几点:
1. 随机森林算法对于少量数据集表现不佳
随机森林算法需要大量的数据才能表现出它的优势。对于较小的数据集,随机森林算法往往表现不如其他算法。因为对于较小的数据集,随机森林算法很容易出现过拟合现象,这会导致算法的性能下降。
2. 随机森林算法的结果不够直观
随机森林算法通常输出的是一组结果,例如一组类别或一组数值。这样的结果不够直观,可能需要进一步的处理才能得到更加直观的结果。
3. 随机森林算法的训练时间较长
随机森林算法需要同时训练多个决策树,并且每个决策树的训练需要对数据集进行随机采样和特征选择等操作。这些操作会使得随机森林算法的训练时间较长。此外,当决策树的数量增加时,随机森林算法的训练时间也会增加。
4. 随机森林算法对于分类不平衡的数据集表现不佳
对于分类不平衡的数据集,随机森林算法往往会出现偏差。因为在多数投票机制中,具有较多样本的类别更容易成为预测结果的主导因素。为了解决这个问题,我们可以采用加权随机森林算法或通过重采样等方式来平衡类别权重。
随机森林算法应用
我们将使用Python的scikit-learn库实现一个基于随机森林的分类模型,并以鸢尾花数据集为例进行演示。
数据集
鸢尾花数据集是一个常用的分类问题数据集,它包含了三个不同种类的鸢尾花的花萼和花瓣的长度和宽度。数据集中的三个类别分别是山鸢尾(Iris Setosa)、变色鸢尾(Iris Versicolour)和维吉尼亚鸢尾(Iris Virginica)。数据集共有150个样本,其中每个类别各有50个样本。
我们可以使用Python的scikit-learn库加载鸢尾花数据集,代码如下:
from sklearn.datasets import load_iris
iris = load_iris()
数据预处理
我们可以使用Pandas库将数据集转换为DataFrame格式,这样更方便数据的处理和分析。代码如下:
import pandas as pd
data = pd.DataFrame(data=iris.data, columns=iris.feature_names)
target = pd.DataFrame(data=iris.target, columns=['target'])
然后我们可以将数据集分为训练集和测试集,训练集用于训练模型,测试集用于测试模型的预测准确率。我们可以使用scikit-learn库中的train_test_split函数将数据集划分为训练集和测试集。代码如下:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.3)
随机森林分类模型
在进行数据预处理后,我们可以使用scikit-learn库中的RandomForestClassifier来构建随机森林分类模型。随机森林算法有一些需要设置的参数,例如树的数量、树的最大深度等。在这里,我们使用默认的参数。
代码如下:
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_train, y_train.values.ravel())
模型评估
我们使用测试集来评估模型的预测准确率。代码如下:文章来源:https://www.toymoban.com/news/detail-404882.html
from sklearn.metrics import accuracy_score
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy:', accuracy)
在本例中,我们使用了默认参数的随机森林分类模型,在测试集上的预测准确率为0.978。这个结果表明,该模型可以很好地对鸢尾花进行分类。文章来源地址https://www.toymoban.com/news/detail-404882.html
到了这里,关于随机森林算法深入浅出的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!