一、Ceph简介
1、Ceph概念
分布式存储是指一种独特的系统架构,它由一组网络进行通信、为了完成共同的任务而协调工作的计算机节点组成;分布式系统是为了用廉价的、普通的机器完成单个计算无法完成的计算、存储任务;其目的是利用更多的机器,处理更多的数据。
Ceph是一个统一【块存储、文件系统存储、对象存储】的分布式存储系统,提供较好的性能、可靠性和可扩展性。
Ceph项目最早起源于Sage就读博士期间的工作(最早的成果于2004年发表),并随后贡献给开源社区。在经过了数年的发展之后,目前已得到众多云计算厂商的支持并被广泛应用。RedHat及OpenStack都可与Ceph整合以支持虚拟机镜像的后端存储。
2、Ceph特点
- 高性能
摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高。
考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。
能够支持上千个存储节点的规模,支持TB到PB级的数据。 - 高可用性
副本数可以灵活控制。
支持故障域分隔,数据强一致性。
多种故障场景自动进行修复自愈。
没有单点故障,自动管理。 - 高可扩展性
去中心化。
水平扩展,扩展灵活。
随着节点增加而线性增长。
3、Ceph架构
Ceph是一个统一块存储、文件存储、对象存储的分布式系统。
RadosGW、RBD和CephFS都是RADOS存储服务的客户端,它们把RADOS的存储服务接口(librados)分别从不同的角度做了进一步抽象,因而各自适用于不同的应用场景。
对象数据的底层存储服务是由多个主机(host)组成的存储集群,该集群也被称之为RADOS(Reliable Automatic Distributed Object Store)存储集群,即可靠、自动化、分布式对象存储系统。
librados是RADOS存储集群的API,它支持C、C++、Java、Python、Ruby和PHP等编程语言。
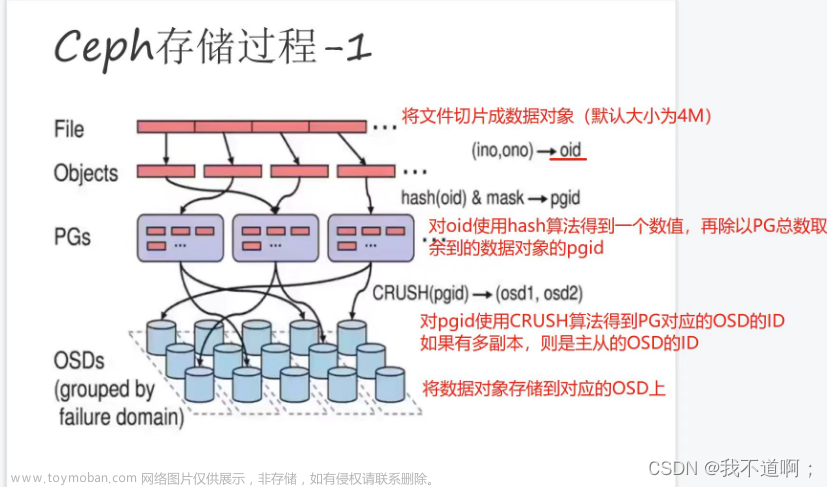
Ceph是一个对象式存储系统,它把每一个待管理的数据流(例如一个文件)切分为一到多个固定大小的对象数据,并以其为原子单元完成数据存取。数据的写入流程如下:
Cpeh基于Crush算法计算将Data Object映射到PG,再从PG映射到集群的某个osd。除此之外,Crush算法还负责修复osd等高级功能。
Cpeh集群中最核心的组件:Rados Cluster组件,它可以将File按照固定大小切分为DO,基于对象进行管理数据,将DO通过Crush算法路由到指定的OSD上进行存储。
另外,整个集群的状态[包括osd、PG等]是由监控组件mon【基于paxos的高可用集群】管理与维护的。mgr组件分担了一些monitor组件的功能,不需要高可用。
Cpeh没有文件元数据库服务器,它的所有数据访问都是基于Crush算法实时计算进行路由的,因此整个集群可以无限制水平扩展。
任何客户端[【RadosGW、RBD和CephFS】与rados的交互都是通过各自客户端的存储池pool。为了更好的管理大批量的Data Object,存储池pool中虚拟出PG概念,PG的数量根据公式计算定义出来的。
4、Ceph组件
一个Ceph分布式存储集群一般由多个OSDs组件【Object Storage Daemon】、Monitor组件、Manager组件、MDFs组件 [非必须,CephFS客户端专用] 组成。
1、Monitor组件维护了一个集群运行图【Cluster Map,包括监控映射、Crush算法映射、osd映射、PG映射等以及复杂的映射关系】。由运行在主机上的守护进程Monitor组件管理维护,它还维护整个集群的认证信息并实行认证【基于CephX协议】【至少三个才能保证高可用】
2、Manager组件跟踪集群运行时的指标以及集群状态信息,包括存储利用率、性能指标、系统负载等。【至少两个才能保证高可用】
3、Ceph OSDs是指单独的存储磁盘设备。每个磁盘上都会有osd守护进程。用于真正的存储数据、处理数据、复制、恢复、重新负载均衡、并提供监控信息给Monitor组件。【至少三个才能保证高可用】
4、MDFs是为CephFs文件系统提供存储元数据信息的Ceph元数据服务器。通过ceph-mds守护进程。
附注:Ceph Block Devices即RBD不需要守护进程;Ceph Filesystem需要ceph-mds守护进程;Ceph Object Gateway需要ceph-radosgw守护进程。文章来源地址https://www.toymoban.com/news/detail-404973.html
- OSD
存储设备。
全称Object Storage Device,也就是负责响应客户端请求返回具体数据的进程。一个Ceph集群一般都有很多个OSD。 - Monitor
集群监控组件。
一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,用来保存OSD的元数据。 - RadosGateway(RGW)
对象存储网关。 - MDSs
存放文件系统的元数据(对象存储和块存储不需要该组件)
全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。 - Client
ceph客户端。
5、Ceph存储引擎
-
FileStore和BlueStore
对于FileStore,元数据存储在levelDB;对于BlueStore【Ceph新的存储后台,更快】,元数据存储在RocksDB和BlueFS中。
为什么Blue Store更快?
因为FileStore需要先将数据格式化为XFS格式;而Blue Store无需格式化,直接在块设备上创建元数据区RocksDB。
二、Ceph部署
ceph官网:https://docs.ceph.com/en/pacific/
ceph中文文档:https://download.csdn.net/download/qq_41822345/85104644
阿里镜像部署包:https://mirrors.aliyun.com
ceph博客:https://blog.csdn.net/weixin_44908159/article/details/108303222
ceph博客专栏:https://blog.csdn.net/don_chiang709/category_8958706.html
三、Ceph块存储
Ceph块设备也叫做RADOS块设备 → RADOS block device : RBD
RBD驱动已经很好的集成在了Linux内核中。提供了企业功能,如快照、COW克隆等等。RBD还支持内存缓存,从而能够大大的提高性能。
Linux内核可用直接访问Ceph块存储,KVM可用借助于librbd访问Ceph块存储。
这也是Ceph Block Devices不需要守护进程的原因。
附注:Ceph Block Devices即RBD不需要守护进程;Ceph Filesystem需要ceph-mds守护进程;Ceph Object Gateway需要ceph-radosgw守护进程。

四、Ceph文件存储
块存储,仅允许同时一个客户端访问,无法实现多人同时使用块设备。而Ceph的文件存储共享则允许多人同时使用。
分布式文件系统(Distributed File System)是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连;CephFS使用Ceph集群提供与POSIX兼容的文件系统;允许Linux直接将Ceph存储mount到本地。
针对文件系统,有一个元数据(Metadata)的概念:
任何文件系统中的数据分为数据和元数据。数据是指普通文件中的实际数据,而元数据指用来描述一个文件的特征的系统数据【描述数据的数据】,比如:访问权限、文件拥有者以及文件数据库的分布信息(inode)等。
附注:Ceph Block Devices即RBD不需要守护进程;Ceph Filesystem需要ceph-mds守护进程;Ceph Object Gateway需要ceph-radosgw守护进程。
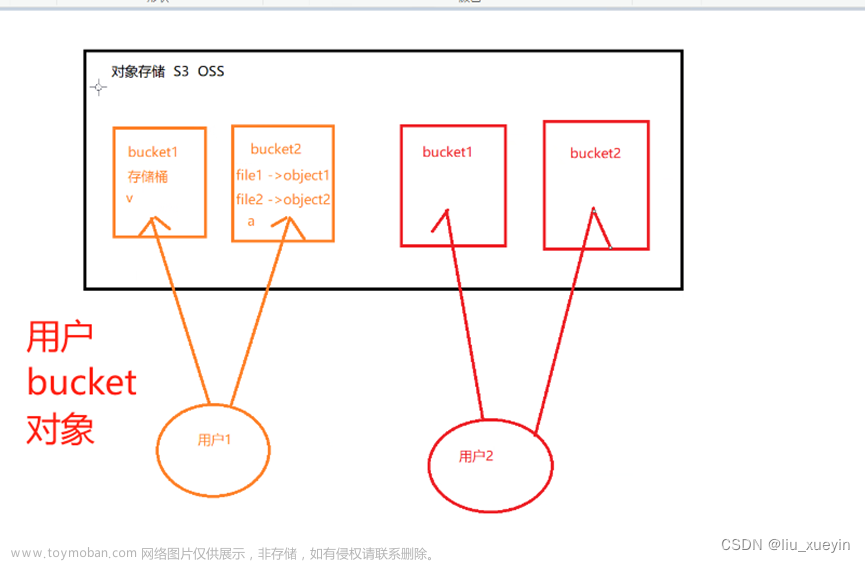
五、Ceph对象存储
对象存储也就是键值存储,通其接口指令,也就是简单的GET、PUT、DEL和其他扩展,向存储服务上传下载数据。
对象存储中所有数据都被认为是一个对象,所以,任何数据都可以存入对象存储服务器,如图片、视频、音频等。
RGW全称是Rados Gateway。RGW是Ceph对象存储网关,用于向客户端应用呈现存储界面,提供RESTful API访问接口。文章来源:https://www.toymoban.com/news/detail-404973.html
附注:Ceph Block Devices即RBD不需要守护进程;Ceph Filesystem需要ceph-mds守护进程;Ceph Object Gateway需要ceph-radosgw守护进程。
到了这里,关于Ceph分布式存储笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!