在第一篇博文中也提及到User-Agent,表示请求载体的身份,也就是说明通过什么浏览器进行访问服务器的,这一点很重要。
① UA检测
门户网站服务器会检测请求载体的身份。如果检测到载体的身份表示为某一款浏览器的请求,则说明这是一个正常的请求;若检测到载体身份标识并不是基于任意一款浏览器,则说明这是一个非正常的请求也就是爬虫,服务器很有可能拒绝该请求!!!
② UA伪装
让爬虫对应的请求载体身份标识进行伪装成某一款浏览器
项目
项目概述:用户输入指定的关键词,之后通过百度搜索引擎查到的所有相关页面进行下载到本地
步骤:
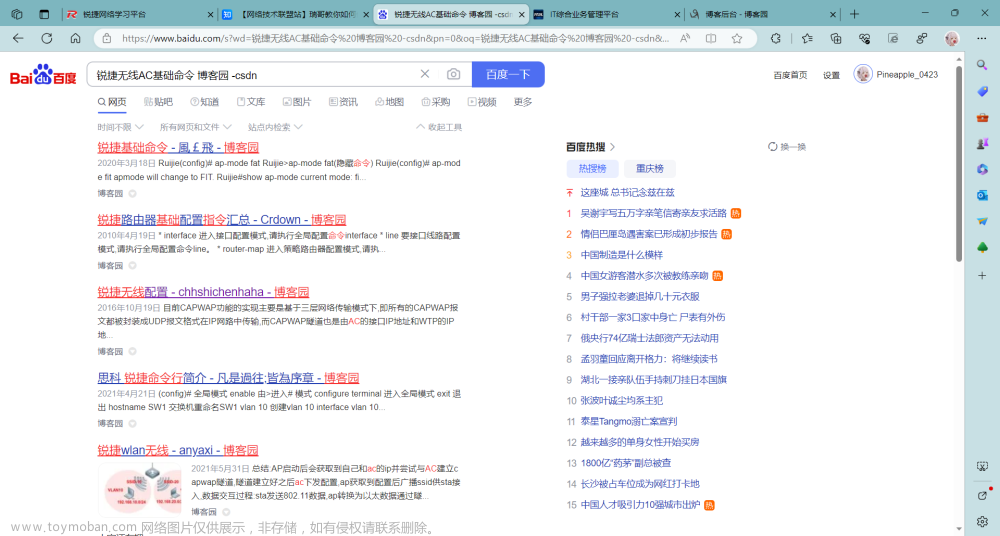
① 打开百度,搜索任意关键字信息,查看地址栏信息
例如我这里搜索beyond,地址栏信息为https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=beyond&oq=%25E9%25BB%2584%25E5%25AE%25B6%25E9%25A9%25B9&rsv_pq=86cafe360003cde6&rsv_t=6497SlvSbubKeEQiJKGnLL%2BCucYyWr9OJTHOTd0x%2Bbx0%2BViW%2FN75Q0avW1M&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=6&rsv_sug1=4&rsv_sug7=100&rsv_sug2=0&rsv_btype=t&inputT=964&rsv_sug4=965
实则有用信息仅为https://www.baidu.com/s?wd=beyond,你也可以单独输入该网址仍可接收到服务器反馈的相同页面结果信息。(同理其他的搜索引擎也都类似)其中beyond为可变参数,遇到可变参数需要把其放入到字典中去

②整理完url之后,我们需要获取某个浏览器载体身份认证信息,这里以Chrome为例,随便打开一个网站(例如https://www.baidu.com/s?wd=beyond),F12打开开发者工具,F5重新向服务器发出请求,Network下Name随便找一个点进入,就可以找到User-Agent信息,例如我的是这个User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36,该信息就是Chrome浏览器的唯一身份认证标识
③在get方法中,传入User-Agent和用户输入的关键字信息即可(均为字典形式)文章来源:https://www.toymoban.com/news/detail-405000.html
完整代码
import requests
if __name__ == '__main__':
#UA伪装,获取某个浏览器的User-Agent唯一载体身份标识
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
#指定url
url = 'https://www.baidu.com/s?'#https://www.baidu.com/s?word=%E9%BB%84%E5%AE%B6%E9%A9%B9
#处理url携带的参数,将参数封装到字典中
keyword = input("please input a word:")
param = {
'wd':keyword
}
#对指定的url发起请求,对应的url是携带参数的,并且请求过程中已经处理了参数
response = requests.get(url=url,params=param,headers=headers)#若不传入headers这个User-Agent信息,运行程序之后,服务器并不会给这个响应返回数据信息。这说明百度搜索引擎中采用了UA检测反爬虫机制
#获取响应
page = response.text
filename = keyword+".html"
#持久化存储
with open('E:/Jupyter_workspace/study/python/'+filename,'w',encoding='utf-8') as fp:#将服务器返回的页面信息存储到本地指定路径
fp.write(page)
print(filename,"保存成功")
运行效果如下:

 文章来源地址https://www.toymoban.com/news/detail-405000.html
文章来源地址https://www.toymoban.com/news/detail-405000.html
到了这里,关于三、实战---爬取百度指定词条所对应的结果页面(一个简单的页面采集器)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!